



1. 서 론
건축물의 구조가 복잡화, 대형화되면서 기존 화재 감지기의 적용 범위와 성능에 한계를 보이고 있으며 보다 신속하고 정확하게 화재를 감지하는 새로운 기술의 개발이 요구되고 있는 실정이다. 이에 따라 열⋅연기⋅가스 등 물리적 센싱 기술 기반의 기존 감지 기술을 고도화하는 노력과 더불어 보안 분야 등에서 널리 사용되고 있는 CCTV 영상 센싱 기술을 활용한 화재 감지 기술도 각광받기 시작했다.
본 연구의 대상인 지능형 CCTV는 현장에서 실시간으로 촬영된 영상 이미지를 지능형 분석 모듈과 결합하여 화재의 발생과 양상을 검출하는 기술이다. 이 방식은 주로 딥러닝(Deep Learning)의 영상 분석 기법인 CNN (Convolutional Neural Network) 모델에 기반을 두고 개발되고 있다. 현재까지 진행된 CCTV 화재 감지 기술은 주로 단일 카메라의 이미지를 분석하고 검출하는 방식(Fig. 1)을 채택하고 있어서 카메라 주변의 종합적인 환경 정보 수집이 어렵다. 예를 들어 각 CCTV별로 검출된 객체가 중첩되어 인식되는 등의 문제가 발생할 수 있으며 이로 인하여 같은 장소에서 발생된 동일 화재임에도 불구하고 서로 다른 복수의 화재로 오인하는 등의 문제점이 있다.

본 논문에서는 이러한 카메라의 중첩을 해결하고 이를 적극적으로 활용하여 화재 발생 위치를 신속하게 구체화하고자 화재 발생뿐 아니라 복수의 카메라를 상호 연동하여 발생 위치를 추정하는 방법을 제안하고자 한다. 이 방식은 단독 카메라만의 이미지 분석 방식보다 정확하게 화재의 정도와 상황 정보를 함께 얻을 수 있다. 기존 지능형 CCTV 이미지에서는 중첩 부분의 화재 발생인 경우에 관찰자가 CCTV 이미지를 비교하여 중첩 부분임을 육안으로 판단하는 방식인데 본 논문은 이를 자동화하는 방법을 적용하였다.
제안하는 방식은 감시 공간을 표현하는 기초 지도를 작성하는 단계와 화재 검출에 따라 위치를 표시하여 지도를 완성하는 두 가지 단계로 이루어진다. 기초 지도 작성은 카메라 설치시 1회에 걸쳐 격자형 구역을 나누고 초기 지도를 작성하는 과정을 말한다. 기초 지도 작성과 화재 검출 과정을 위한 검출 엔진으로는 최근 성능과 안정성을 인정받고 있는 CNN 기반의 분석 모델인 YOLOv5 를 적용하였다. 화재 위치 산정 알고리즘에서는 카메라별로 작성된 공간지도를 교차하는 방식으로 공통의 영역 인덱스를 추출하는 방식이다. 하지만 딥러닝 기반 검출 방식은 학습 샘플의 양과 절차에 따라 성능이 크게 달라질 수 있다. 이에 본 논문에서는 딥러닝 엔진으로 화재, 연기, 사람 등 물체 검출율을 높이기 위한 다양한 샘플 수집 방법, 학습 진행 순서 등 다양한 실험을 진행하였고 이에 따른 성능 변화를 4장에서 설명하였다.
2. 선행 연구 고찰
CCTV와 같은 카메라로 촬영된 이미지를 분석하여 물체를 인식하고 찾아내는 일은 컴퓨터 비전(Computer Vision) 분야의 작업으로 자율 주행 자동차, 로봇 등 자동화 기계의 주요 센싱 기술로 자리잡고 있다. 이러한 컴퓨터 비전기술은 다양한 범주와 대상으로 확대되어 화재 검출 기능을 갖는 지능형 CCTV로 진화하고 있다.
화재 검출과 같이 이미지 내의 객체를 인식(Object Detecton)하는 작업은 해당 대상이 무엇인지를 식별하는 객체 분류 단계(Classification)와 이미지 내 어느 지점에서 발견 되는 가를 결정하는 위치 선정 단계(Localization) 등 두 가지 세부 작업으로 이루어진다(Zhong-Qiu et al., 2019). 일반적으로 객체 인식을 위해서 주로 사용되는 프로그램은 이미지 딥러닝 분석으로 특화된 CNN (Convolution Neural Network) 형식으로 대표적인 것으로 R-CNN (Region-CNN), Fast R-CNN, YOLO (You Only Look Once) 등이 있다(Sojasingarayar, 2022). R-CNN은 Fig. 2와 같이 이미지로부터 다양한 방식으로 영역 분포를 만들고 개개 영역별로 특징을 구한 뒤 CNN 구조체로 처리하는 과정으로 설명할 수 있다. 다시 말해서 CNN과 영역 제안(Region proposals)을 결합했다고 할 수 있다. R-CNN은 2014년 Girshick 등에 의해서 연구되었다(Girshick et al., 2014).

R-CNN 방식은 위에서 언급한 객체 분류 단계와 위치 선정 단계를 구분하여 2단계로 나누어 순차적으로 진행하는 데 이것을 1단계로 통합하여 수행하도록 한 것이 YOLO 방식이다. 일반적으로 R-CNN 방식은 검출 정확도가 높은 반면에 처리 속도가 느려서 이를 개선한 것이 Fast R-CNN 이지만 YOLO 모델에 비하면 여전히 상대적으로 느리다. Fig. 3은 이러한 영역 설정의 차이를 비교 설명한 것이다(Saydirasulovich et al., 2023).
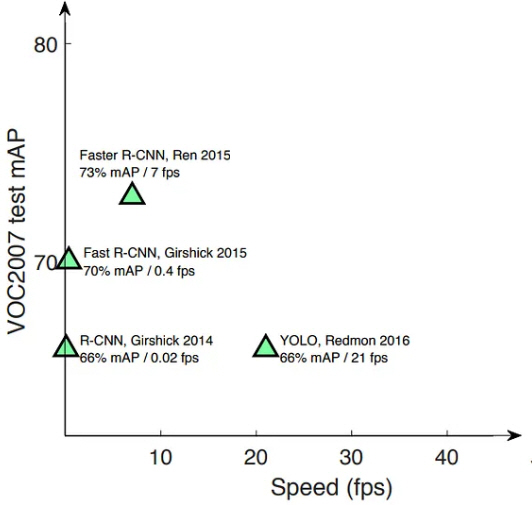
R-CNN은 많은 수의 후보 영역을 선정하고 영역별로 CNN을 적용하여 특징 벡터(Feature Vector)를 생산하는 방식이기 때문에 실시간 검출 용도로 활용하기 어렵다. 실생활에 적용하기 위해서는 충분히 빠른 속도와 실용적인 정확도를 갖춘 보다 개선된 모델이 필요하며 대표적으로 YOLO 모델을 예로 할 수 있다. YOLO는 이미지를 1회 스캔하는 방식으로 대상의 위치를 계산하는 방식이기 때문에 R-CNN으로 적용하기 어려운 실시간 처리가 가능하다(Sumit et al., 2020).
카메라 이미지를 분석하여 화재 검출을 위한 다양한 딥러닝 분석 방법이 적용되고 있다(Roh et al., 2022; Lee et al., 2017). Zheng et al. (2023)의 연구에서는 화재, 연기 검출을 위한 딥러닝 분석 시스템을 구성하고 다양한 방식으로 실험하였다. 비교 대상으로 삼은 딥러닝 모델로는 Fater-RCNN, SSD (Single Shot MultiBox Detector), YOLOv3, YOLOv4-tiny, YOLOv4를 사용하여 성능 테스트를 하고 자신들이 제안하는 개선 모델(MobileNetV3-large-YOLOv4)과 비교하는 연구를 진행하였다(Zheng et al., 2023). Saydirasulovich 의 연구는 YOLOv6를 이용하여 4,000장 이미지를 학습, 테스팅, 성능 평가에 사용하였다(Saydirasulovich et al., 2023).
3. 화재 위치 산정 알고리즘을 위한 기초 지도 작성
YOLO 모델을 활용하여 Fig. 4에 나타낸 바와 같이 공간(감시 구역) 내에 설치된 복수의 CCTV 이미지를 분석하여 화재 발생 여부와 발생 위치를 나타내는 상황 지도를 작성하기 위해서는 두 가지 단계가 필요하다. 첫 번째 단계는 준비 단계로서 공간(감시 구역)을 격자로 나누고 영역별로 인덱스를 부여하는 단계이다. 그리고 두 번째 단계는 CCTV가 신속하게 화재의 위치를 판별하기 위해서 격자로 나눈 영역과 카메라별 이미지를 상호 비교하여 위치를 선정하는 단계로 구분된다. 따라서 본 연구에서는 복수의 CCTV 이미지 내에서 인덱스를 구분하여 영역을 나누고, 상호 중첩되는 이미지가 있다고 가정하였다.
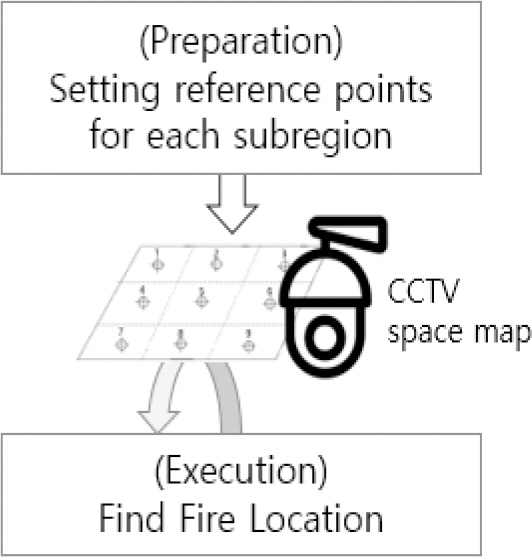
3.1 기초 지도 작성
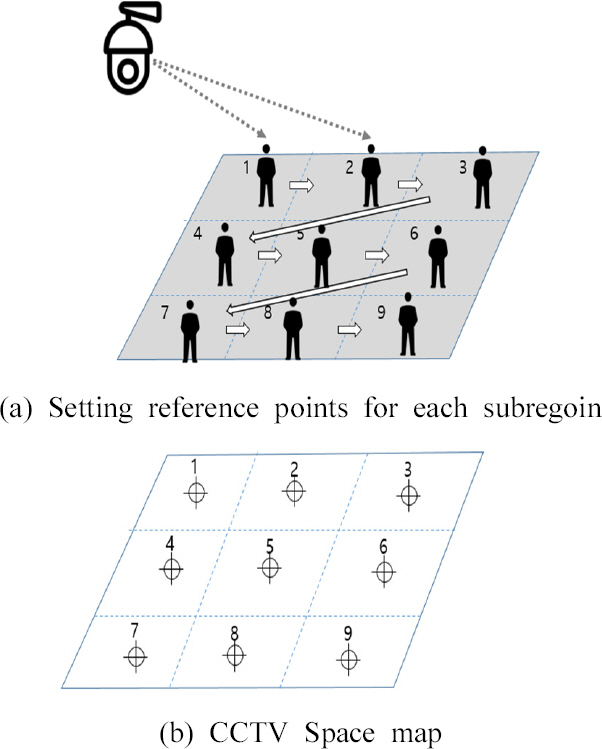
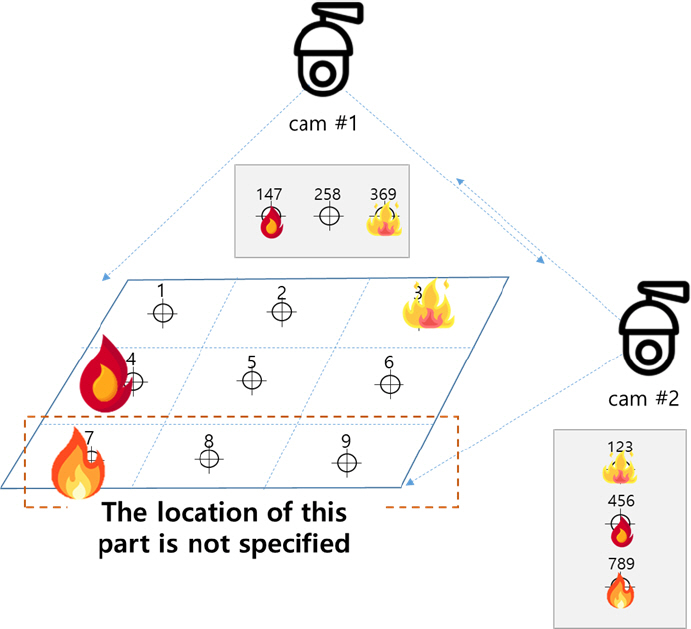
공간(감시 구역) 지도는 카메라 설치 시 인식되는 공간을 통해 작성하며, 카메라 위치가 변경되지 않는 한 반복적으로 사용할 수 있다. 기초 지도 작성을 위해서 Fig. 5에 나타낸 바와 같이 공간(감시 구역)을 소 영역으로 나누고, 각 영역별로 CCTV가 이동형 객체(사람)를 통해 기준점 설정하고 추적하여 모든 소 영역별로 위치를 인식하도록 하였다. 이처럼 Fig. 5(a)는 전체 공간(감시 구역)을 3 × 3 격자 형식으로 실제 공간을 9개의 소영역으로 구분하였고, 이동형 객체(사람)가 소 영역에 위치한 순서대로 인덱스를 부여하여 CCTV space map (Fig. 5(b))을 구성하였다. Fig. 6은 실제 실험을 통해 기초 공간 지도 작성을 진행한 것으로 이동형 객체(사람)를 인식한 후 원하는 소영역에 위치했을 때 인덱스를 부여하는 방식으로, 3대의 CCTV를 이용해 각기 다른 각도와 거리에서 객체를 검출하였으며, 실시간으로 영상을 송출받아 진행하였다. 이때 카메라에 부여된 인덱스와 CCTV Space Map이 동일하게 감지되므로 공간적인 동기화를 실현할 수 있게 된다. 따라서 각 격자의 소 영역별로 인덱스가 부여됨에 따라 공간(감시 구역)의 위치 정보를 파악할 수 있다. 이를 통해 다수의 카메라 이미지에 나타나는 화재 발생은 카메라 대수가 아니라 격자의 소 영역별로 부여된 인덱스를 분석하는 방식으로 중복 카운팅을 피할 수 있다. 예를 들어 Fig. 7에 나타낸 바와 같이 cam #1은 소영역 4와 7에서 발생한 화재의 이미지가 겹쳐 보여 화재 위치를 정확하게 판별할 수 없지만, cam #2은 소영역 3, 4, 7 에서 발생한 화재의 위치를 판별할 수 있다. 따라서 각 카메라의 화재의 위치가 다르므로 복수개의 카메라를 통해 사각지대를 해소하고, 공간(감시 구역) 내 소 영역별로 인식할 수 있도록 화재 위치 산정 알고리즘을 설계하였다.

3.2 화재 위치 산정 알고리즘
화재 위치 산정 알고리즘은 카메라 별로 작성된 공간지도를 교차하여 공통의 인덱스를 추출하는 방식으로 화재 위치를 특정하는 것이다. 또한 화재 지도의 변화 추이를 분석하여 실시간으로 화재 현황 정보를 얻을 수 있다.
화재 위치 선정은 공간(감시 구역) 지도를 기반으로 진행하며, 화재가 검출된 위치를 좌표로 표시하여 가장 근접한 소 영역으로 확인하는 방식이다. 그리고 정확한 소 영역의 위치 지정은 각 카메라의 이미지 내 부여된 인덱스를 조합하여 비교한다.
Fig. 8은 실제 화재 실험을 통해 기초 공간 지도 작성 당시 부여된 인덱스의 좌표와 가까운 화원의 위치를 찾아서 좌표 및 인덱스를 부여한 결과이다. 즉 카메라 A에서 화원이 검출된 인덱스는 4와 5, 카메라 B에서 화원이 검출된 인덱스는 0과 5, 카메라 C에서 검출된 인덱스는 5와 4이다. 3대의 카메라 정보를 교차⋅비교하여 화재가 발생한 인덱스의 좌표가 5임을 특정할 수 있다.

카메라는 2D 이미지 형태로 공간을 감지하기 때문에 이미지가 겹쳐 보이는 경우가 있다. 이러한 현상은 Eq. (1)과 같이 카메라 A와 카메라 B의 그리드(Grid)의 중첩(교차)된 영역을 표현하며, 각 함수는 카메라의 화재 검출 여부를 나타낸다.
따라서 Fig. 7과 같이 화재 검출 알고리즘을 통해 cam #1에서 소영역 4와 7의 이미지가 겹쳐 보여 화재를 인식하지 못하지만, cam #2에서는 화재를 인식하기 때문에, 화재가 발생한 위치를 정확하게 판별하기 위하여 다수의 카메라가 필요하다. 이것은 각 카메라가 검출하는 이미지를 중첩(교차)하여 사각지대를 해소하기 위함이다.
4. 실험 결과
인공신경망의 노드 연결 가중치를 안정 수준으로 안착시키기 위해서는 많은 반복 학습이 필요하다. 만약 표본 수가 적을 경우 일반적이지 못한 특정 패턴에서 가중치가 상대적으로 높아질 수 있는 과적합 현상이 발생할 염려가 있어서 충분한 표본 수가 필요하다. 특히 화재나 연기 등은 일정한 형태를 유지하기 어려운 객체이므로 더 많은 표본이 필요할 수 있지만 일반적으로 표본 수집 과정에 많은 시간과 비용이 요구되는 수작업이기 때문에 원하는 표본 개수를 확보하기 어렵다. 이를 보완하기 위해서 이미 확보된 표본에 이미지를 다양하게 변환하여 표본의 수를 늘리는 방법을 사용할 수 있다. 본 논문에서 일부 사용한 이미지 표본은 Fig. 9와 같다.

본 연구에서 적용한 이미지 변환 함수로 이미지 회전, 명도 조정(+ 10, - 10 등), 뒤집기(Vertical Flip, Horizontal Flip) 등을 사용하였다. 이미지 회전에서 값이 큰 경우(90°, - 90° 등) 학습 효과 감소로 이어지는 경우가 많았고 회전각을 작게 한 경우(1°, - 1° 등) 가 보다 효과적이었다.
다양한 각도에서 이미지를 촬영할 경우 카메라에서 객체를 바라보는 각도에 따라 인덱스를 부여하는 영역의 이미지가 경계를 벗어나는 경우가 발생하였다. 이러한 현상을 개선하기 위해 90°, 180°, 270° 등 각도가 변하여도 인덱스 부여 영역의 이미지 경계가 벗어나는 현상을 방지하여 이미지 경계 이탈이 발생하지 않도록 표본을 확장하였다(Rizwan, 2020).
화재(fire)나 연기(smoke)를 검출 대상으로 하는 경우 인식 패턴의 변화 정도가 매우 심한 편이며, 이러한 경향을 갖는 패턴에 효과적이라고 알려진 CNN 딥러닝 모델인 YOLOv5를 사용하여 구현하였다. YOLOv5의 검출 대상은 화재(fire), 연기(smoke), 사람(person)으로 총 3가지이며, 앞서 설명하는 방법으로 필요한 표본을 수집하고 확장하여 YOLOv5 모델을 학습시켰다.
검출 대상이 화재나 연기와 같은 위험 요소인 경우는 오인식이 포함되더라도 미인식되는 경우를 최소화하여 재현율(Recall)을 높이는 것이 정밀도(Precision)보다 중요할 수 있다. 즉 확실한 경우를 우선하는 방식(정밀도, Precision)보다는 인식의 허용 범위를 넓게 하는 방식이다. 정밀도와 재현율은 딥러닝 학습의 성능을 측정하는 중요한 척도로서 상호 트레이드오프(Trade-off) 관계를 갖는다. 일반적으로 모델의 정밀도를 정의하면 TP/ (TP+FP)의 값으로 계산하고 재현율은 TP/ (TP+FN)로 나타내는데, 이때 (T)는 해당 대상을 옳게 분류한 경우를 (F)는 그렇지 않은 경우를 나타낸다. 정밀도가 높은 경우 재현율은 낮아지는 트레이드오프 관계이므로 적절한 조율이 필요하다.
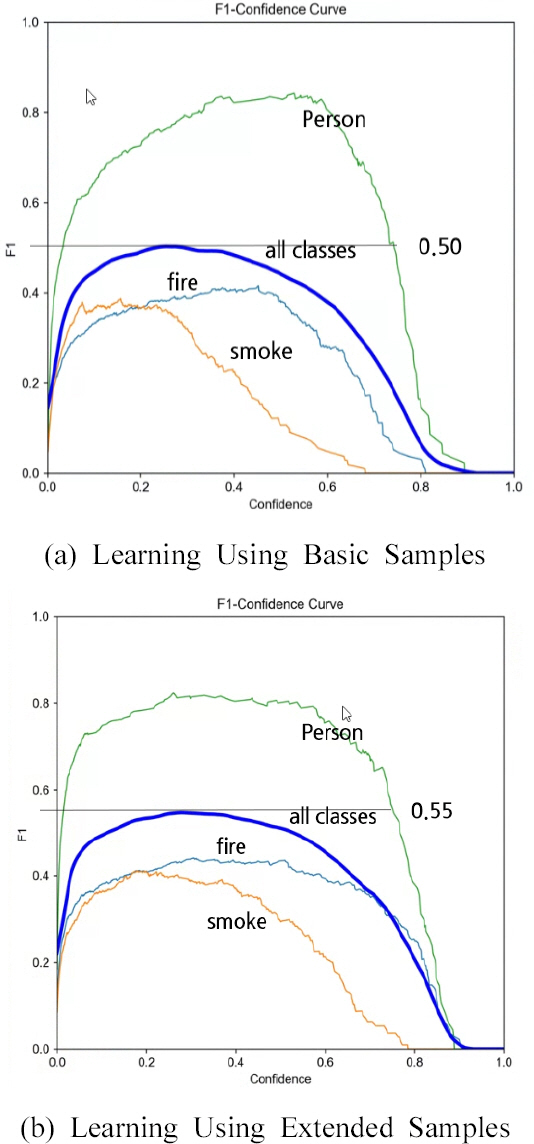
본 논문의 검출 대상인 3가지 클래스 중에서 Fig. 9에 나타낸 바와 같이 객체의 형태가 화재(fire)는 모의 화재 실험을 촬영한 동영상을 프레임별로 추출하고 라벨링하여 사용하였다. 그리고 Fig. 10은 F1-Confidence Curve를 구한 그래프로서 객체 검출의 정밀도(Precision)와 재현율(Recall)의 조화평균 값을 구하여 F1으로 표시(y축)한 것이다. 검출 대상인 3클래스 중에서 “사람(person)”이 비교적 높은 값으로 표시되었다. 다른 객체(클래스)에 비해 “사람(person)”이 높은 값을 갖는 이유는 비교적 학습 샘플을 구하기 쉽고, 충분한 양의 학습이 가능하다. 또한 객체의 형태가 화재(fire)나 연기(smoke)에 비하여 비교적 분명한 패턴으로 식별할 수 있어 높은 값이 나온 것으로 사료된다. 연기(smoke)의 경우는 상대적으로 낮은 F1 값을 보이는 데 연기의 형태 변이를 표현할 만큼 패턴을 명확하게 식별하기 어렵고, 학습 샘플 수가 충분하지 못한 것으로 판단된다.
Fig. 10(a)는 딥러닝 학습을 통해 수집한 기본 샘플을 가지고 진행한 경우의 F1 값을 나타내고 Fig. 10(b)는 객체(화재, 연기, 사람)별 샘플의 수를 확장하여 학습하고 측정한 값을 나타낸다. Fig. 10(a)의 F1 값은 0.5이고, Fig. 10(b)의 경우는 0.55로 Fig. 10(a)에 비하여 약 5% 정도 향상된 것을 확인할 수 있었다.
5. 결 론
일반적으로 건물의 방범과 안전을 목적으로 출입구, 사무실 등 주요 공간(감시 구역)에 다수의 카메라가 설치⋅운영되고 있으며, 딥러닝 모델을 적용한 지능형 CCTV도 검토되고 있는 추세이다.
하지만 지능형 CCTV의 화재 검출이 카메라별로 배타적으로 이루어지고 있어 화재 발생 시 중첩되는 영역(이미지)이 발생함에 따라 동일한 화재임에도 불구하고 서로 다른 영역(이미지)으로 오인할 수 있다.
이에 본 연구에서 제안하는 알고리즘은 이러한 상호 중첩되는 이미지를 역으로 이용하여 동일한 영역(이미지)으로 판별하고 화재 발생 위치와 규모를 정확하게 파악할 수 있게 하였다. 이를 위해 공간(감시 구역) 기초 지도를 작성하고, 실제 카메라를 설치하여 화재를 검출하는 두 단계로 제시하였다. 딥러닝 기반의 물체 검출 알고리즘을 사용하였으며, 몇 가지 대상을 구분하여 검출하였다. 이러한 CCTV 지능 분석을 위하여 YOLOv5을 선정하였고, 다양한 분석 실험을 진행하였다. 검출 대상은 화재(fire), 연기(smoke), 사람(person)으로 총 3가지로 구분하여 수집하였고, 그 중 사람(person)은 이동형 객체로 공간(감시 구역) 기초 지도를 작성하는 데 활용하였는데, 이동형 객체(사람(person))를 추적하여 모든 소영역별로 위치를 인식하여 인덱스를 부여하였으며, 이것은 공간적인 동기화를 구현할 수 있게 하였다. 그리고 화재 위치 산정 알고리즘을 구현하였는데, 카메라별로 작성된 공간지도를 교차하여 공통의 인덱스를 추출하는 방식으로 화재 위치를 특정할 수 있었다. 이것은 화재 지도의 변화 추이를 분석하여 실시간으로 화재 현황 정보를 얻을 수 있게 되었다. 하지만 카메라가 이동하거나 설치 각도가 변경되는 경우 실제 공간(감시 구역)과 CCTV 가상 공간의 소영역별로 공간 동기화를 다시 실행해야 한다는 한계점이 나타났다.
이 한계점을 제외하면 기존 지능형 CCTV의 문제점을 보완하는 연구로서, 화재 발생 시 중첩되는 영역(이미지)이 발생할 경우 자동으로 분석하여 화재 발생 위치 정보를 신속하게 제공할 수 있는 데이터베이스 구축에 기여할 수 있을 것으로 판단된다.




