



1. м„ң лЎ
мөңк·ј мқҙмғҒкё°нӣ„(abnormal climate)лЎң мқён•ң нҳёмҡ°(heavy rainfall)мҷҖ нғңн’Қ(typhoon) л“ұм—җ мқҳн•ҙ лҸҢл°ңнҷҚмҲҳ(freshet) л°Ҹ к·№н•ңнҷҚмҲҳ(extreme flood)мқҳ л°ңмғқмқҙ л№Ҳл°ңн•ҳкі мһҲлӢӨ. лҳҗн•ң, лҸ„мӢңнҷ” л°Ҹ л¶ҲнҲ¬мҲҳ л©ҙм Ғ мҰқк°ҖлҠ” мқёкө¬мҷҖ мһ¬мӮ°мқҙ л°Җ집н•ҙ мһҲлҠ” лҸ„мӢңн•ҳмІң мң м—ӯмқҳ лҢҖк·ңлӘЁ нҷҚмҲҳн”јн•ҙлҘј л°ңмғқмӢңнӮӨлҠ” мЈјлҗң мҡ”мқёмңјлЎң мһ‘мҡ©н•ҳкі мһҲлӢӨ. нҠ№нһҲ, кёүмҶҚн•ң лҸ„мӢңнҷ”лЎң мқён•ҙ мһ¬н•ҙм—җ м·Ём•Ҫн• лҝҗл§Ң м•„лӢҲлқј н”јн•ҙм•ЎлҸ„ л§Өмҡ° нҒ¬кІҢ л°ңмғқн•ҳкі к·ё н”јн•ҙлҠ” лӮ лЎң мҰқк°Җн•ҳкі мһҲлҠ” 추세мқҙлӢӨ(AON, 2019; Kim, Lee et al., 2022).
мһ¬лӮңмңјлЎң мқён•ң н”јн•ҙлҘј к°җмҶҢн•ҳкё° мң„н•ҙ мӢңн–үлҗҳкі мһҲлҠ” мһ¬н•ҙ м Җк°җ лҢҖмұ…мқҖ нҒ¬кІҢ кө¬мЎ°м Ғ лҢҖмұ…(structural measure)кіј 비кө¬мЎ°м Ғ лҢҖмұ…(non-structural measure)мңјлЎң кө¬л¶„н• мҲҳ мһҲлӢӨ. кө¬мЎ°м Ғ лҢҖмұ…мқҳ кІҪмҡ° кіөн•ҷм Ғмқё кё°мҲ мқ„ мқҙмҡ©н•ҳм—¬ мһ¬лӮңмң„н—ҳ м§Җм—ӯм—җ кө¬мЎ°л¬ј нҳ№мқҖ мӢңм„Өл¬јмқ„ м„Өм№ҳн•ҳкұ°лӮҳ мһ¬лӮңм—җ л…ём¶ңлҗң кұҙл¬јмқ„ ліҙк°• л°Ҹ к°ңм„ н•ҳлҠ” л°©лІ•мңјлЎң мһ¬лӮңмңјлЎң мқён•ң мң„н—ҳ(risk)мқ„ лӮ®м¶”кі мҲҳмҡ©л Ҙ(capacity)мқ„ лҶ’мқҙлҠ” кІғмқҙлӢӨ. к·ёлҹ¬лӮҳ, мһҗм—°ліҙм „ л°Ҹ мғқнғң кІҪкҙҖ ліҙм „ л“ұ мғқнғңм Ғ к°Җм№ҳк°Җ мӨ‘мҡ”н•ҳкІҢ м—¬кІЁм§Җл©ҙм„ң мӢңн–үм—җ м–ҙл ӨмӣҖмқ„ кІӘкі мһҲлӢӨ(Kang et al., 2007; Kim et al., 2007; Kim, Han et al., 2022). лҳҗн•ң, кө¬мЎ°м Ғ лҢҖмұ…мқҖ 집мӨ‘нҳёмҡ°лЎң мқён•ҙ м„Өкі„ л№ҲлҸ„лҘј мҙҲкіјн•ҳлҠ” мһ¬лӮңмқҙ л°ңмғқн•ҳл©ҙ мӨ„мқҙм§Җ лӘ»н•ҳлҠ” л¬ём ңм җкіј 비кө¬мЎ°м Ғ лҢҖмұ…ліҙлӢӨ мғҒлҢҖм ҒмңјлЎң 비мҡ©кіј мӢңк°„мқҙ л§Һмқҙ мҶҢмҡ”лҗңлӢӨ(Kim, Kim et al., 2022). мң„мҷҖ к°ҷмқҖ н•ңкі„м җмқ„ к·№ліөн•ҳкё° мң„н•ҙ 비кө¬мЎ°м Ғ лҢҖмұ…мқҳ н•ҳлӮҳлЎң мӮ¬м „м—җ мһ¬н•ҙлҘј мҳҲмёЎн•ҳкі м Җк°җн• мҲҳ мһҲлҠ” нҷҚмҲҳ мҳҲвӢ…кІҪліҙм—җ лҢҖн•ң м—°кө¬мқҳ н•„мҡ”м„ұмқҙ лҢҖл‘җлҗҳкі мһҲлӢӨ.
нҳ„мһ¬ нҷҚмҲҳнҶөм ңмҶҢм—җм„ңлҠ” нҷҚмҲҳ мҳҲвӢ…кІҪліҙ мӢңмҠӨн…ңмқ„ мҡҙмҳҒн•ҳкі мһҲмңјл©°, мҲҳл¬ён•ҷм Ғ лӘЁнҳ• мӨ‘ м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•(storage function model, SFM)мқҙ кө¬нҳ„лҗҳкі мһҲлӢӨ. нҷҚмҲҳмҳҲмёЎм—җ лҢҖн•ң лӢӨм–‘н•ң лӘЁнҳ•мқҳ м Ғмҡ©м—җ л§ҺмқҖ м—°кө¬к°Җ мқҙлЈЁм–ҙм§Җкі мһҲлӢӨ(Kratzert et al., 2018; Xiang et al., 2020; Han et al., 2021; Kim, Lee et al., 2022). н•ҳм§Җл§Ң, м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ мӢӨмӢңк°„ нҷҚмҲҳмң м¶ң нҳ„мғҒмқ„ лӘЁмқҳ н•ҳлҠ” лҚ° мһҲм–ҙ к°ҖмһҘ м–ҙл Өмҡҙ м җмқҖ л§Өк°ңліҖмҲҳлҘј кІ°м •н•ҳлҠ” кІғмқҙлӢӨ. м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҳ л§Өк°ңліҖмҲҳ м¶”м •л°©лІ•мқҖ нҷҚмҲҳ мҲҳл¬ё мһҗлЈҢ л“ұмқҳ л¶ҖмЎұмңјлЎң мқён•ҳм—¬ мқјліёмқҳ мқҙк·јмІң(еҲ©ж №е·қ) кіөмӢқмқ„ мЈјлЎң мӮ¬мҡ©н•ҳкі мһҲм–ҙ мҡ°лҰ¬лӮҳлқјмқҳ мң м—ӯ нҠ№м„ұмқ„ 충분нһҲ л°ҳмҳҒн•ҳм§Җ лӘ»н•ҳлҠ” л“ұ л§ҺмқҖ л¬ём ңм җмқ„ к°Җм§Җкі мһҲлӢӨ. лҚ”л¶Ҳм–ҙ, л§Өк°ңліҖмҲҳлҘј кІ°м •н• мҲҳ мһҲлҠ” к°қкҙҖм Ғмқҙкі н•©лҰ¬м Ғмқё л°©лІ•мқҙ м ңмӢңлҗҳм–ҙ мһҲм§Җ м•Ҡм•„ нҷҚмҲҳ мӮ¬мғҒм—җ л§һ추м–ҙ л§Өк°ңліҖмҲҳлҘј кІ°м •н• л•Ң кІҪн—ҳмӢқ лҳҗлҠ” м „л¬ёк°Җмқҳ нҢҗлӢЁм—җ мқҳн•ң ліҙм •м—җ мқҳмЎҙн•ҳкі мһҲлӢӨ. мҰү, мғҲлЎңмҡҙ нҷҚмҲҳмӮ¬мғҒмқҙ л°ңмғқн• л•Ңл§ҲлӢӨ л§ӨлІҲ мҲҳл¬ё м „л¬ёк°Җмқҳ кІҪн—ҳм—җ мқҳн•ң л§Өк°ңліҖмҲҳ мЎ°м •мқҙ н•„мҡ”н•ң мӢӨм •мқҙлӢӨ. мқҙлҹ¬н•ң лӢЁм җмңјлЎң мқён•ҙ нҷҚмҲҳ лҸ„лӢ¬мӢңк°„мқҙ 짧мқҖ мӮ°м§Җ н•ҳмІңмқҙлӮҳ мҶҢн•ҳмІңмқҳ нҷҚмҲҳ мҳҲвӢ…кІҪліҙлҘј мң„н•ң м„ н–үмӢңк°„ нҷ•ліҙк°Җ н•„мҡ”н•ң мӢӨм •мқҙлӢӨ. л¬јлҰ¬м Ғ лӘЁнҳ•мқҖ ліөмһЎн•ң мҲҳл¬ё мӢңмҠӨн…ңмқ„ лӢЁмҲңнҷ”н•ҳлҠ” кіјм •м—җм„ң кё°мғҒн•ҷ, м§Җнҳ•н•ҷм Ғ л“ұ лӢӨм–‘н•ң ліҖмҲҳлҘј кі л Өн•ҳкё° м–ҙл Өмҡҙ н•ңкі„к°Җ мһҲлӢӨ(Jung et al., 2018; Han et al., 2021). к·ёлҰ¬кі мҲҳмң„ л°Ҹ к°•мҡ°мҷҖ к°ҷмқҖ л№„м„ нҳ•м Ғмқё мҡ”мҶҢл“Өмқ„ м„ нҳ• лӘЁнҳ•мңјлЎң н•ҙм„қн•ҳкё°м—җлҠ” м–ҙл Өмҡҙ л¶Җ분мқҙ мһҲлӢӨ(Montanari et al., 1997; Kim, 2010). мқҙлҹ¬н•ң л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ, лЁёмӢ лҹ¬лӢқ(machine learning)мқҳ л°ңм „кіј н•Ёк»ҳ л№„м„ нҳ• лӘЁнҳ•мқҙ мҲҳмң„ мҳҲмёЎм—җ мӮ¬мҡ©лҗҳкі лҶ’мқҖ м„ұлҠҘмқҳ кІ°кіјлҘј м ңкіөн•ңлӢӨ(Riad et al., 2004; Ghumman et al., 2011; Yan et al., 2018).
нҷҚмҲҳнҠ№ліҙ л°ңл № кё°мӨҖмқҖ м „көӯ н•ҳмІңм—җ лҸҷмқјн•ң кё°мӨҖмңјлЎң м„Өм •лҗҳм–ҙ мһҲлӢӨ. нҷҚмҲҳнҠ№ліҙлҘј л°ңл №н•ҳлҠ” м§Җм җмқҳ мҲҳмң„к°Җ кі„мҶҚ мғҒмҠ№н•ҳм—¬ мЈјмқҳліҙ л°Ҹ кІҪкі„ нҷҚмҲҳмң„(кі„нҡҚнҷҚмҲҳлҹүмқҳ 50% нқҗлҘј л•Ң мҲҳмң„)мқҳ мҙҲкіјк°Җ мҳҲмғҒлҗҳлҠ” кІҪмҡ° нҷҚмҲҳ мЈјмқҳліҙлҘј л°ңл №н•ңлӢӨ. нҷҚмҲҳ мЈјмқҳліҙк°Җ л°ңл №лҗҳм–ҙ мһҲлҠ” м§Җм җмқҳ мҲҳмң„к°Җ н•ҳк°•н•ҳм—¬ мЈјмқҳліҙ мҲҳмң„ мқҙн•ҳлЎң лӮҙл Өк°Ҳ кІғмқҙ мҳҲмғҒлҗҳлҠ” кІҪмҡ° нҷҚмҲҳ мЈјмқҳліҙлҘј н•ҙм ңн•ңлӢӨ. нҷҚмҲҳнҠ№ліҙ л°ңл №н•ҳлҠ” м§Җм җ мҲҳмң„к°Җ кі„мҶҚ мғҒмҠ№н•ҳм—¬ кІҪліҙмң„н—ҳ нҷҚмҲҳмң„(кі„нҡҚнҷҚмҲҳлҹүмқҳ 70% нқҗлҘј л•Ң мҲҳмң„)лҘј мҙҲкіјн• кІғмқҙ мҳҲмғҒлҗҳлҠ” кІҪмҡ° нҷҚмҲҳкІҪліҙлҘј л°ңл №н•ңлӢӨ(Ministry of Environment, 2020). мқҙлҠ” к°Ғ мң м—ӯмқҳ мқјкҙҖлҗң кё°мӨҖмңјлЎң м„Өм •лҗҳм–ҙ мһҲлӢӨ. мҰү, л°©мһ¬м„ұлҠҘмқҙ лӮ®мқҖ м§Җм—ӯмқҳ кІҪмҡ° мҳҲліҙ л°Ҹ кІҪліҙк°Җ л°ңн‘ңлҗҳм§Җ м•ҠлҚ”лқјлҸ„ к·ё м „м—җ н”јн•ҙк°Җ л°ңмғқн• к°ҖлҠҘм„ұмқҖ кі л Өлҗҳм–ҙ мһҲм§Җ м•ҠлӢӨ. мқҙмҷҖ кҙҖл Ён•ҳм—¬ мқјкҙ„м Ғмқё нҷҚмҲҳ мЈјмқҳліҙ л°Ҹ кІҪліҙ мІҙкі„лЎңлҠ” лҢҖмқ‘мқҳ н•ңкі„к°Җ мһҲкі м •нҷ•лҸ„ л°Ҹ мӢӨнҡЁм„ұм—җ л¬ём ңк°Җ м ңкё°лҗҳкі мһҲлӢӨ(Kim, Han et al., 2022).
нҳ„мһ¬ нҷҚмҲҳ мҳҲвӢ…кІҪліҙлҠ” кё°мЎҙ кҙҖмёЎмһҘ비мқҳ мҲҳм§‘м •ліҙлҘј лҚ°мқҙн„° лЎңкұ°лҘј нҶөн•ҙ м„јн„°лЎң мҲҳ집лҗҳм–ҙ 분м„қмқ„ мҲҳн–үн•ҳкі мӢӨл¬ҙмһҗм—җ кІҪн—ҳмқ„ л°”нғ•мңјлЎң кІҪліҙлҘј л°ңл №н•ҳкі мһҲм–ҙ мӢ мҶҚм„ұ, м •нҷ•м„ұ л°Ҹ мӢ лў°м„ұмқҙ лӮ®лӢӨ. мқҙлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ, AI лӘЁнҳ•мқ„ мқҙмҡ©н•ң нҷҚмҲҳмң„ мҳҲмёЎлӘЁнҳ• к°ңл°ңмқҳ н•„мҡ”м„ұмқҖ лҢҖл‘җлҗҳкі мҳҲмёЎлҗң нҷҚмҲҳмң„ кІ°кіјлҘј нҷңмҡ©н•ҳм—¬ мӢ мҶҚн•ҳкі м •нҷ•н•ң нҷҚмҲҳ мҳҲвӢ…кІҪліҙлҘј мҡҙмҳҒн•ҙм•ј н•ңлӢӨ.
л”°лқјм„ң, ліё м—°кө¬м—җм„ңлҠ” нҷҚмҲҳнҠ№ліҙк°Җ к°ҖмһҘ л§Һмқҙ л°ңмғқн•ң мң м—ӯмқ„ м—°кө¬ лҢҖмғҒм§Җм—ӯмңјлЎң м„ м •н•ҳкі мһҗ н•ҳмҳҖлӢӨ. нҷҚмҲҳ лҸ„лӢ¬мӢңк°„мқҙ 짧мқҖ кёүкІҪмӮ¬ м§Җм—ӯмқҳ мҶҢн•ҳмІң л°Ҹ мӮ°м§Җ н•ҳмІңмқ„ мӨ‘мӢ¬мңјлЎң нҷҚмҲҳ мҳҲвӢ…кІҪліҙ мӢңмҠӨн…ңмқ„ кө¬м¶•н•ҳкё° мң„н•ҙ, нҳ„мһ¬ кё° мҡҙмҳҒ мӨ‘мқё м ҖлҘҳн•ЁмҲҳ лӘЁнҳ• л°Ҹ лӢЁмқј AI лӘЁнҳ•мқҳ нҷҚмҲҳмң„ мҳҲмёЎ кІ°кіјлҘј 비көҗ л°Ҹ нҸүк°Җн•ҳкі мһҗ н•ҳмҳҖлӢӨ. к·ёлҰ¬кі мҳҲмёЎл Ҙ нҸүк°Җ кІ°кіјлҘј нҶөн•ҙ мөңм Ғмқҳ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ м„ м •н•ҳкі мһҗ н•ҳмҳҖлӢӨ. лҳҗн•ң, нҷҚмҲҳн”јн•ҙ кі„кёүкө¬к°„ 분лҘҳ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳкі нҷ•лҘ кіј н”јн•ҙк·ңлӘЁм—җ лҢҖн•ң мң„н—ҳмҲҳмӨҖмқ„ нҢҢм•…н• мҲҳ мһҲлҠ” нҷҚмҲҳн”јн•ҙ нҸүк°Җ кё°лІ•мқ„ к°ңл°ңн•ҳкі мһҗ н•ҳмҳҖлӢӨ.
2. мһҗлЈҢ л°Ҹ м—°кө¬ л°©лІ•
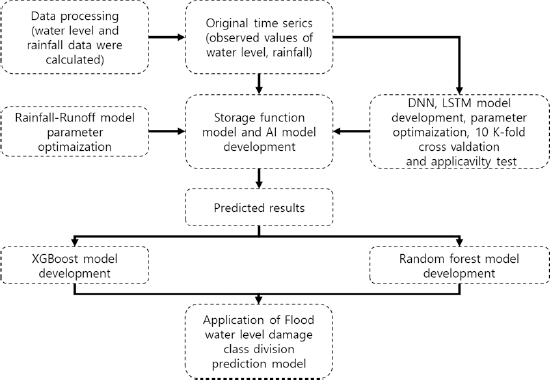
ліё м—°кө¬м—җм„ңлҠ” лҸ„лӢ¬мӢңк°„мқҙ 짧мқҖ мҷ•мҲҷмІң мң м—ӯмқҳ нҷҚмҲҳмң„ мҳҲмёЎ л°Ҹ нҷҚмҲҳн”јн•ҙ мҳҲвӢ…кІҪліҙ кё°лІ•мқ„ м ңм•Ҳн•ҳкі мһҗ Fig. 1кіј к°ҷмқҙ м—°кө¬ нқҗлҰ„лҸ„лҘј кө¬м„ұн•ҳмҳҖлӢӨ. мҲҳл¬ёмЎ°мӮ¬м—°ліҙлҘј м°ёкі н•ҳм—¬, 2008л…„л¶Җн„° 2020л…„к№Ңм§Җ нҷҚмҲҳнҠ№ліҙк°Җ к°ҖмһҘ л§Һмқҙ л°ңл №лҗң лӮЁм–‘мЈјмӢң(진кҙҖкөҗ) мҲҳмң„ кҙҖмёЎмҶҢк°Җ мң„м№ҳн•ң мҷ•мҲҷмІң мң м—ӯмқ„ м—°кө¬ лҢҖмғҒм§Җм—ӯмңјлЎң м„ м •н•ҳмҳҖлӢӨ. 진кҙҖкөҗ м§Җм җмқҳ мҲҳмң„ мһҗлЈҢ л°Ҹ мң м—ӯ мқёк·јм—җ мң„м№ҳн•ң к°•мҡ° мһҗлЈҢлҘј мқҙмҡ©н•ҳмҳҖлӢӨ. нҷҚмҲҳмң„лҘј мҳҲмёЎн•ҳкё° мң„н•ҙ, AI кё°л°ҳмқҳ DNN лӘЁнҳ• л°Ҹ LSTM лӘЁнҳ•мқ„ мқҙмҡ©н•ҳмҳҖлӢӨ. 진кҙҖкөҗ мҲҳмң„ кҙҖмёЎмҶҢмқҳ нҷҚмҲҳ нҠ№ліҙ кё°мӨҖмқ„ л°”нғ•мңјлЎң AI кё°л°ҳмқҳ XGBoost, лһңлҚӨнҸ¬л ҲмҠӨнҠё лӘЁнҳ•мқ„ м Ғмҡ©н•ҳм—¬ нҷҚмҲҳн”јн•ҙ 분лҘҳ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳмҳҖлӢӨ.
Fig.В 1
Research Flow Chart of Flood Water Level Forecasting and Flood Damage Prediction and Warning Technique Using AI-based Model
2.1 м—°кө¬ лҢҖмғҒм§Җм—ӯ л°Ҹ мһҗлЈҢ мҲҳ집
мҲҳл¬ёмЎ°мӮ¬м—°ліҙлҠ” нҷҳкІҪл¶Җ, 4лҢҖк°• нҷҚмҲҳнҶөм ңмҶҢ, кё°мғҒмІӯ, н•ңкөӯмҲҳмһҗмӣҗкіөмӮ¬, н•ңкөӯлҶҚм–ҙмҙҢкіөмӮ¬, н•ңкөӯмҲҳл Ҙмӣҗмһҗл Ҙ л“ұ л¬јкҙҖл Ё кё°кҙҖм—җм„ң кҙҖмёЎн•ң мҲҳл¬ёмһҗлЈҢлҘј мў…н•©вӢ…м •лҰ¬н•ҳм—¬ мҲҳлЎқн•ЁмңјлЎңмҚЁ, мҡ°лҰ¬лӮҳлқј мҲҳмһҗмӣҗ분야 м—°кө¬мҷҖ н•ҳмІңмқҳ нҡЁмңЁм Ғмқё кҙҖлҰ¬ л°Ҹ көӯнҶ к°ңл°ңкі„нҡҚ л“ұм—җ кё°мҙҲмһҗлЈҢлЎң нҷңмҡ©н•ҳкі мһҲлӢӨ(Ministry of Environment, 2020). мҲҳл¬ёмЎ°мӮ¬м—°ліҙлҘј м°ёкі н•ҳм—¬, 2008л…„л¶Җн„° 2020л…„к№Ңм§Җ нҷҚмҲҳ мЈјмқҳліҙ л°Ҹ кІҪліҙк°Җ к°ҖмһҘ л§Һмқҙ л°ңмғқн•ң м§Җм—ӯмқ„ мӮҙнҺҙліё кІ°кіј, лӮЁм–‘мЈјмӢңм—җ мң„м№ҳн•ң 진кҙҖкөҗ м§Җм җмқҙ 12лІҲмңјлЎң к°ҖмһҘ л§Һмқҙ л°ңл №лҗҳм—ҲлӢӨ.
진кҙҖкөҗ(м§Җм җлӘ…)лҠ” мҷ•мҲҷмІң(нҮҙкі„мӣҗ) мң м—ӯм—җ нҸ¬н•Ёлҗҳм–ҙ мһҲлҠ” м§Җм җ лӘ…м№ӯмқҙкі лҢҖн•ңлҜјкөӯ н•ңк°•мқҳ м ң1 м§ҖлҘҳмқҙл©° кІҪкё°лҸ„ нҸ¬мІңмӢң лӮҙмҙҢл©ҙ мӢ нҢ”лҰ¬ мҲҳмӣҗмӮ°м—җм„ң л°ңмӣҗн•ҳм—¬ лӮЁм–‘мЈјмӢңлҘј кұ°міҗ кө¬лҰ¬мӢң нҶ нҸүлҸҷм—җм„ң н•ңк°•кіј н•©лҘҳн•ҳлҠ” м§Җл°©н•ҳмІңмқҙлӢӨ. мң лЎңм—°мһҘмқҖ 37.34 km, мң м—ӯл©ҙм ҒмқҖ 270.79 km2, нҸүк· кі лҸ„лҠ” 177.51 EL.m, нҸүк· кІҪмӮ¬лҠ” 26.05%мқҙм§Җл§Ң, мғҒлҘҳ мң м—ӯмқҖ кі м§ҖлҢҖ л°Ҹ кёүкІҪмӮ¬ кө¬к°„мқҙкі н•ҳлҘҳ мң м—ӯмқҖ лҢҖл¶Җ분 м Җм§ҖлҢҖ л°Ҹ мҷ„кІҪмӮ¬ кө¬к°„мңјлЎң нҷҚмҲҳ мң„н—ҳлҸ„к°Җ лҶ’лӢӨ. лҳҗн•ң, нҷҚмҲҳлҸ„лӢ¬ мӢңк°„мқҖ 1мӢңк°„ мқҙлӮҙмқҙкі мң м—ӯ лӮҙ лҸ„мӢңнҷ”мңЁмқҙ кіјкұ° 3.6% (1985л…„)м—җм„ң 10.5% (2020л…„)лЎң мҰқк°Җн•ҳм—¬ лҸ„мӢңнҷ”м—җ л”°лҘё л¶ҲнҲ¬мҲҳл©ҙм Ғ мҰқк°ҖлЎң нҷҚмҲҳмң м¶ңлҹү л°Ҹ нҷҚмҲҳ мң„н—ҳлҸ„к°Җ мҰқк°Җн•ҳкі мһҲлӢӨ(Fig. 2).

ліё м—°кө¬м—җм„ң мӮ¬мҡ©н•ң м ҖлҘҳн•ЁмҲҳ лӘЁнҳ• л°Ҹ AI кё°л°ҳ лӘЁнҳ•мқҳ мһ…л Ҙ л°Ҹ кІҖмҰқ мһҗлЈҢлҠ” н•ңк°•нҷҚмҲҳнҶөм ңмҶҢ(Han River Flood Control Office)м—җм„ң м ңкіөн•ҳлҠ” 2008л…„л¶Җн„° 2020л…„к№Ңм§Җмқҳ 진кҙҖкөҗ мҲҳмң„ кҙҖмёЎмҶҢм—җм„ң кҙҖмёЎлҗң 10분лӢЁмң„ мҲҳмң„мһҗлЈҢ л°Ҹ 진кҙҖкөҗ мқёк·ј мң м—ӯмқҳ к°•мҡ° кҙҖмёЎмҶҢм—җм„ң кҙҖмёЎлҗң 10분лӢЁмң„ к°•мҡ°лҹүмһҗлЈҢлҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ.
2.2 м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•
м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ мӮ°м§Җк°Җ л§ҺмқҖ мң м—ӯм—җ м Ғн•©н•ҳлҸ„лЎқ к°ңл°ңлҗң нҷҚмҲҳмң м¶ң лӘЁнҳ•мңјлЎң м—°мҶҚл°©м •мӢқм—җ мң м—ӯмқҙлӮҳ н•ҳлҸ„м—җм„ңмқҳ мң м¶ңлҹүкіј м ҖлҘҳлҹүмқҳ кҙҖкі„лҘј н‘ңкё°н•ҳлҠ” м ҖлҘҳн•ЁмҲҳлҘј лҢҖмһ…н•ҳм—¬ нҷҚмҲҳ мң м¶ңлҹүмқ„ кі„мӮ°н•ҳлҠ” л°©лІ•мқҙлӢӨ(Song et al., 2006; Sung et al., 2008; Kim, Lee et al., 2022).
м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•м—җм„ңлҠ” нҷҚмҲҳмң м¶ңмқ„ л§ӨлӢқкіөмӢқ(manning formula)мңјлЎң мң м—ӯкіј н•ҳлҸ„кө¬к°„мқҳ м§Җн‘ңл©ҙ мң м¶ңмқҙлқј к°Җм •н•ҳкі м ҖлҘҳлҹүмқ„ мң м¶ңлҹүмқҳ м§ҖмҲҳн•ЁмҲҳлЎң н‘ңкё°н•ңлӢӨ.
нҷҚмҲҳнҢҢ(flood wave)мқҳ мҡҙлҸҷл°©м •мӢқ(equations of motion)мңјлЎңK, PлҠ” мң м—ӯмқҙлӮҳ н•ҳлҸ„ кө¬к°„м—җ лҢҖн•ң м ҖлҘҳмғҒмҲҳлҘј мқҳлҜён•ҳкі 1к°ң мң м—ӯм—җ лҢҖн•ң м—°мҶҚл°©м •мӢқ(continuity equation)мқҖ л¬јмҲҳм§Җ(water budget) л°©м •мӢқкіј к°ҷмқҙ лӮҳнғҖлӮёлӢӨ.
м—¬кё°м„ң,fлҠ” мң мһ…кі„мҲҳ, ОіaveлҠ” мӢңк°„лӢ№ мң м—ӯ нҸүк· к°•мҡ°лҹү(mm/hr), AлҠ” мң м—ӯл©ҙм Ғ(km2), Ql (t)=Q(t+Tl)лЎң мң м—ӯмқҳ м§ҖмІҙмӢңк°„Tlмқ„ кі л Өн•ң мң м—ӯмңјлЎңл¶Җн„° м§Ғм ‘мң м¶ңлҹү(m3/s), SlмқҖ мң м—ӯм ҖлҘҳлҹү(m3)мқ„ мқҳлҜён•ңлӢӨ.
мң м—ӯмқҳ мң м¶ңмқ„ кі„мӮ°н•ҳкё° мң„н•ҙ мң м—ӯмқҳ м—°мҶҚл°©м •мӢқкіј мҡҙлҸҷл°©м •мӢқмқ„ лӢЁмң„ мң мһ…лҹү(Оіave)кіј лӢЁмң„ мң м¶ңкі (ql) л°Ҹ лӢЁмң„ м ҖлҘҳкі (sl)лҘј м •лҰ¬н•ҳл©ҙ лӢӨмқҢкіј к°ҷлӢӨ.
к°•мҡ° мҙҲкё°м—җлҠ” м№ЁнҲ¬лЎң мқён•ҙ к°•мҡ° мң м¶ңмқҙ л°ңмғқн•ҳм§Җ м•Ҡкі к°•мҡ°лҹүмқҙ мҰқк°Җн•Ём—җ л”°лқј мқјл¶Җ м§Җм—ӯм—җм„ң мң м¶ңмқҙ л°ңмғқн•ҳкё° мӢңмһ‘н•ңлӢӨ. лҳҗн•ң, мў…көӯм—җлҠ” м „ мң м—ӯмңјлЎңл¶Җн„° мң м¶ңмқҙ л°ңмғқн•ңлӢӨкі к°Җм •н•ңлӢӨ. л”°лқјм„ң, кё°м Җмң лҹүмқ„ кі л Өн•ң мң м—ӯмңјлЎңл¶Җн„°мқҳ мң м¶ңлҹүмқ„ мҲҳмӢқмңјлЎң лӮҳнғҖлӮҙл©ҙ лӢӨмқҢкіј к°ҷлӢӨ.
м—¬кё°м„ң, flмқҖ 1м°Ё мң м¶ңлҘ ql,мқҖ мҙқмҡ°лҹүм—җ мқҳн•ң лӢЁмң„ мң м¶ңкі (mm/hr), qsa,lмқҖ нҸ¬нҷ”м җ мқҙнӣ„мқҳ мҡ°лҹүм—җ мқҳн•ң лӢЁмң„ мң м¶ңкі (mm/hr), QiлҠ” кё°м Җмң лҹү(m3/s)мқҙлӢӨ.
лӢЁмқј н•ҳлҸ„кө¬к°„м—җ лҢҖн•ң м—°мҶҚл°©м •мӢқмқҖ лӢӨмқҢкіј к°ҷлӢӨ.
м—¬кё°м„ң, fiлҠ” нҸүк· мң мһ…кі„мҲҳ, IjлҠ” мң м—ӯм—җм„ң н•ҳлҸ„лЎң мң мһ…лҗҳлҠ” мң мһ…лҹү(m3/s), QlмқҖQl(t)=Q(t+Tl)лЎң м§ҖмІҙмӢңк°„Tlмқ„ кі л Өн•ң н•ҳлҸ„кө¬к°„ н•ҳлҘҳлӢЁм—җм„ң л№ м ёлӮҳк°ҖлҠ” мң м¶ңлҹү(m3), SlмқҖ н•ҳлҸ„кө¬к°„ лӮҙм—җ м ҖлҘҳлҗҳлҠ” м ҖлҘҳлҹү(m3)мқ„ мқҳлҜён•ңлӢӨ.
мң„м—җм„ң м ҖлҘҳмғҒмҲҳK, PлҠ” кё°мҷ•нҷҚмҲҳмң м¶ң мһҗлЈҢлЎңл¶Җн„° мүҪкІҢ кө¬н• мҲҳ мһҲмңјл©°, SlкіјQlмқҳ кҙҖкі„к°Җ кө¬н•ҙм§Җл©ҙSlмқҖQlмқҳ н•ӯмңјлЎң лӮҳнғҖлӮңлӢӨ.
2.3 мӢ¬мёө мӢ кІҪл§қ
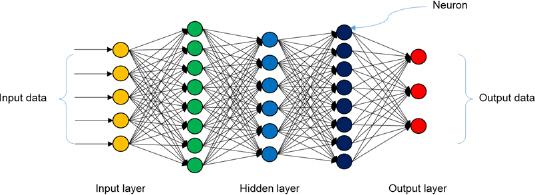
мӢ¬мёө мӢ кІҪл§қ(deep neural network, DNN)мқҖ мһ…л Ҙмёө(input layer)кіј м¶ңл Ҙмёө(output layer) мӮ¬мқҙм—җ м—¬лҹ¬ к°ңмқҳ мқҖлӢүмёө(hidden layer)л“ӨлЎң мқҙлӨ„진 мқёкіөмӢ кІҪл§қ(artificial neural network, ANN)мқҙлӢӨ. мқёкіөмӢ кІҪл§қмқҖ мқёк°„мқҳ лҮҢк°Җ мҲҳл§ҺмқҖ мӢ кІҪл“ӨлЎңл¶Җн„° мһ…л Ҙ(input)кіј м¶ңл Ҙ(output)мқҳ мӢ нҳёлҘј м „лӢ¬н•ҳлҠ” кіјм •мқ„ м°©м•Ҳн•ҳм—¬ к°ңл°ңн•ң л°©лІ•мқҙлӢӨ(McCullock and Pitts, 1956; Dreyfus, 1990). мӢ¬мёө мӢ кІҪл§қмқҳ н•өмӢ¬мқҖ мҲҳл§ҺмқҖ лҚ°мқҙн„° мҶҚм—җм„ң нҢЁн„ҙмқ„ л°ңкІ¬н•ҳм—¬ мҳҲмёЎн•ҳлҠ” кІғмқҙлӢӨ. кё°мЎҙмқҳ мқёкіөмӢ кІҪл§қ лӘЁнҳ•мқҖ лҚ°мқҙн„°мқҳ м–‘мқҙ л§Һм•„м§ҲмҲҳлЎқ кіјм Ғн•©мқҙлӮҳ, мҳҲмёЎ м„ұлҠҘм—җ н•ңкі„к°Җ мһҲм—ҲлӢӨ. к·ёлҹ¬лӮҳ мӢ¬мёө мӢ кІҪл§қмқҖ мқҙлҹ¬н•ң лӢЁм җмқ„ ліҙмҷ„н•ҳкі мһҗлЈҢмқҳ м–‘мқҙ л§Һм•„м§ҲмҲҳлЎқ м„ұлҠҘмқҙ м„ нҳ•м ҒмңјлЎң мҰқк°Җн•ҳлҠ” мһҘм җмқҙ мһҲлӢӨ(Kim, Han et al., 2022; Fig. 3).
2.4 мһҘлӢЁкё° л©”лӘЁлҰ¬
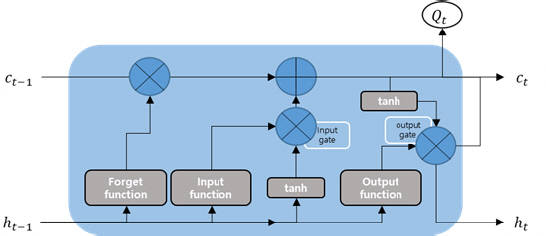
мһҘлӢЁкё° л©”лӘЁлҰ¬(long short-term memory, LSTM)лҠ” мҲңнҷҳ мӢ кІҪл§қ(recurrent neural network, RNN) кё°лІ•мқҳ н•ҳлӮҳлЎң м…Җ(cell), мһ…л Ҙ кІҢмқҙнҠё(input gate), м¶ңл Ҙ кІҢмқҙнҠё(output gate), л§қк°Ғ кІҢмқҙнҠё(forget gate)лҘј мқҙмҡ©н•ҙ кё°мЎҙ мҲңнҷҳ мӢ кІҪл§қ(RNN)мқҳ лӢЁм җмқё кё°мҡёкё° мҶҢл©ё л¬ём ң(vanishing gradient problem)лҘј л°©м§Җн•ҳлҸ„лЎқ к°ңл°ңлҗҳм—ҲлӢӨ(Hochreiter and Schmidhuber, 1997; Agmls et al., 2009). мһҘлӢЁкё° л©”лӘЁлҰ¬лҠ” мҲңнҷҳ мӢ кІҪл§қмқҳ мқјмў…мқҙм§Җл§Ң лӢЁм җмқ„ ліҙмҷ„н•ҳм—¬, мһ…л Ҙ мһҗлЈҢм—җ лҢҖн•ң м •ліҙлҘј лҚ”мҡұ мһҘкё°м ҒмңјлЎң кё°м–өн•ҳкё° мң„н•ҙ, мқҖлӢүмёөм—җ м…Җ мғҒнғң(cell state)кө¬мЎ°лҘј 추к°Җн•ң кІғмқҙлӢӨ(Han et al., 2019; Le et al., 2019; Fig. 4).
2.5 лһңлҚӨнҸ¬л ҲмҠӨнҠё
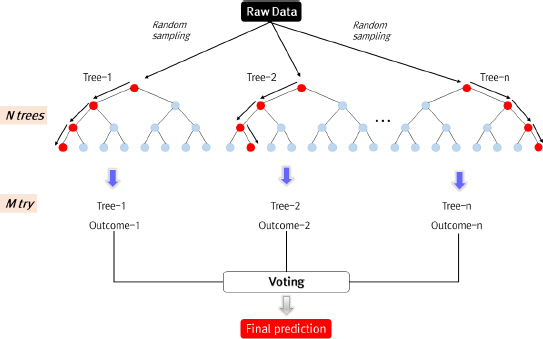
лһңлҚӨнҸ¬л ҲмҠӨнҠё(random forest, RF)лҠ” м•ҷмғҒлё”(ensemble) кё°л°ҳ лӘЁнҳ•мңјлЎң м—¬лҹ¬ к°ңмқҳ мқҳмӮ¬кІ°м •лӮҳл¬ҙ(decision tree, Tree) лӘЁнҳ•м—җ л°°к№…(bagging)мқҳ мӣҗлҰ¬мҷҖ мһ„мқҳм„ұмқ„ лҚ”н•ң 분лҘҳ м•Ңкі лҰ¬мҰҳмқҙлӢӨ. кІ°м • нҠёлҰ¬лҘј мқҙмҡ©н•ң л°©лІ•мқҳ кІҪмҡ°, м„ұлҠҘмқҳ ліҖлҸҷ нҸӯмқҙ нҒ¬лӢӨлҠ” лӢЁм җмқ„ к°Җм§Җкі мһҲлӢӨ. нҠ№нһҲ, н•ҷмҠө мһҗлЈҢм—җ мқҳн•ҙ мғқм„ұлҗҳлҠ” кІ°м • нҠёлҰ¬к°Җ л¬ҙмһ‘мң„м—җ л”°лқј кІ°кіјлҠ” л§Өмҡ° мғҒмқҙн•ҳлӢӨ. л”°лқјм„ң, кІ°м • нҠёлҰ¬лҘј мқјл°ҳнҷ”н•ҳм—¬ мӮ¬мҡ©н•ҳкё°м—җ м–ҙл ӨмӣҖмқҙ л”°лҘёлӢӨ(Amit and Geman, 1997). мқҙлҹ¬н•ң л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ л°°к№…(bagging) лҳҗлҠ” лһңлҚӨ л…ёл“ң мөңм Ғнҷ”(randomized node optimization)мҷҖ к°ҷмқҖ лһңлҚӨнҷ” кё°мҲ мқҖ кІ°м • нҠёлҰ¬к°Җ к°Җ진 лӢЁм җмқ„ к·№ліөн•ҳкі мўӢмқҖ м„ұлҠҘмқ„ к°–лҸ„лЎқ н•ңлӢӨ(Ho, 1998; Breiman, 2001; Fig. 5).
2.6 XGBoost
XGBoostлҠ” Gradient Boosting м•Ңкі лҰ¬мҰҳмқ„ 분мӮ°нҷҳкІҪм—җм„ңлҸ„ мӢӨн–үн• мҲҳ мһҲлҸ„лЎқ кө¬нҳ„н•ҙлҶ“мқҖ лқјмқҙлёҢлҹ¬лҰ¬(library)мқҙлӢӨ. нҡҢк·Җ(regression), 분лҘҳ(classification) л¬ём ңлҘј лӘЁл‘җ м§Җмӣҗн•ҳл©°, мҳҲмёЎ м„ұлҠҘмқҙ мҡ°мҲҳн•ҳм—¬ мһҗлЈҢмқҳ 분лҘҳм—җ мһҲм–ҙ л§Һмқҙ мӮ¬мҡ©лҗҳлҠ” м•Ңкі лҰ¬мҰҳмқҙлӢӨ. XGBoostлҠ” м—¬лҹ¬к°ңмқҳ мқҳмӮ¬кІ°м •лӮҳл¬ҙлҘј мЎ°н•©н•ҙм„ң мӮ¬мҡ©н•ҳлҠ” м•ҷмғҒлё”(ensemble) м•Ңкі лҰ¬мҰҳмқҙлӢӨ(Chen and Guestrin, 2016). XGBoostмқҳ мөңлҢҖ мһҘм җмқҖ кё°мЎҙ л¶ҖмҠӨнҢ… м•Ңкі лҰ¬мҰҳкіј лӢ¬лҰ¬ лі‘л ¬мІҳлҰ¬к°Җ к°ҖлҠҘн•ҳм—¬, мһҗлЈҢмқҳ мІҳлҰ¬мҶҚлҸ„лҘј лҶ’мқј мҲҳ мһҲкі к·ңлӘЁк°Җ нҒ° мһҗлЈҢлҘј л°”нғ•мңјлЎң 분лҘҳ лӘЁнҳ•м—җ м Ғмҡ©н• л•Ң м•Ҳм •м„ұкіј мӢ мҶҚм„ұмқ„ нҷ•ліҙн•ҳкі мһҲлӢӨ(Fig. 6).
2.7 мҳҲмёЎл Ҙ нҸүк°Җ
мҳҲмёЎл Ҙ нҸүк°ҖлҘј мң„н•ң м§Җн‘ң лҳҗлҠ” лӘ©м Ғн•ЁмҲҳ(object function)м—җ л”°лқј мҳҲмёЎл Ҙ нҸүк°Җ л°©лІ•мқҖ лӢ¬лқјм§„лӢӨ. мҳҲлҘј л“Өм–ҙ кҙҖмёЎмҶҢм—җм„ң мёЎм •лҗҳкі мһҲлҠ” кҙҖмёЎ мһҗлЈҢмҷҖ мҳҲмёЎ лӘЁнҳ•мқ„ нҶөн•ҙ мҳҲмёЎлҗң мһҗлЈҢк°„мқҳ мғҒкҙҖкҙҖкі„лҘј лӮҳнғҖлӮҙлҠ” мғҒкҙҖкҙҖкі„ 분м„қ(correlation analysis)мқҖ л‘җ ліҖмҲҳ к°„м—җ м„ нҳ•м Ғ кҙҖкі„лҘј к°–кі мһҲлҠ”м§Җ нҢҢм•…н•ҳлҠ” л°©лІ•мқҙлӢӨ(Kim, Kim et al., 2022; Kim, Lee et al., 2022). мғҒкҙҖкҙҖкі„ 분м„қмқҖ лӢӨмқҢкіј к°ҷмқҙ лӮҳнғҖлӮёлӢӨ.
м—¬кё°м„ң, мғҒкҙҖкҙҖкі„лҘј кі„мӮ°н•ҳкё° мң„н•ҳм—¬ мІ«м§ёxмҷҖyмқҳ нҺём°Ё, мҰү, к°ҒxiмҷҖyiм—җ лҢҖн•ңxi -ВҜxмҷҖyi -ВҜyлҘј кі„мӮ°н•ңлӢӨ.
мҳҲмёЎмҳӨм°ЁлҠ” м–‘мҲҳмҷҖ мқҢмҲҳлЎң лӮҳнғҖлӮҳкё° л•Ңл¬ём—җ, мқҙлҘј к·ёлҢҖлЎң н•©мӮ°н• кІҪмҡ°м—җ м •нҷ•н•ң мҳӨм°ЁлҘј мӮ°м •н•ҳкё° м–ҙл өлӢӨ. л”°лқјм„ң, мҳӨм°ЁлҘј м ңкіұн•ҳм—¬ nмңјлЎң лӮҳлҲҲ к°’мқҙ нҸүк· м ңкіұ мҳӨм°Ё(mean squared error, MSE)лҘј лӢӨмӢң м ңкіұк·ј мӢңнӮЁ м§Җн‘ңк°Җ нҸүк· м ңкіұк·ј мҳӨм°Ё(root mean squared errors, RMSE)мқҙлӢӨ. нҸүк· м ңкіұк·ј мҳӨм°ЁмҷҖ нҸүк· м ңкіұк·ј мҳӨм°ЁлҘј н‘ңмӨҖнҷ”н•ң NRMSE (normalized root mean squared error)лҘј лӢӨмқҢкіј к°ҷмқҙ н‘ңнҳ„лҗңлӢӨ(Kim, Kim et al., 2022; Kim, Lee et al., 2022).
м—¬кё°м„ң, yiлҠ” iлІҲм§ё мӢӨм ң к°’мқ„ мқҳлҜён•ҳл©°y i ^
мқҙ진 분лҘҳлҘј мҲҳн–үн•ҳлҠ” лӘЁлҚёмқҳ кІҖмҰқмқҖ нҳјлҸҷ н–үл ¬(confusion matrix)лҘј мһ‘м„ұн•ҳм—¬ лӢӨм–‘н•ң м§Җн‘ңлЎң кІҖмҰқмқ„ мҲҳн–үн• мҲҳ мһҲкі мӢӨм ң л°ңмғқн•ң кІғмқ„ 1, л°ңмғқн•ҳм§Җ м•ҠмқҖ кІғмқ„ 0мңјлЎң лӮҳнғҖлӮёлӢӨ(Fawcett, 2006; Lee et al., 2021). мҰү, нҳјлҸҷ н–үл ¬мқҖ кҙҖмёЎ к°’ 1, лӘЁнҳ• 1лЎң мҳҲмёЎн•ң кІғмқ„ True Positive (TP), кҙҖмёЎ к°’ 1, лӘЁнҳ• 0мңјлЎң мҳҲмёЎн•ң кІғмқ„ False Negative (FN), кҙҖмёЎ к°’ 0, лӘЁнҳ• 1лЎң мҳҲмёЎн•ң кІғмқ„ False Positive (FP), кҙҖмёЎ к°’ 0, лӘЁнҳ• 0мңјлЎң мҳҲмёЎн•ң кІғмқ„ True Negative (TN)мқҙлқј н•ңлӢӨ. мӮ°м •лҗң нҳјлҸҷ н–үл ¬мқҳ мЎ°н•©мңјлЎң м •нҷ•лҸ„(accuracy), мҳӨлҘҳмңЁ(error rate), лҜјк°җлҸ„(sensitivity), м •л°Җм„ұ(precision), нҠ№мқҙлҸ„(specificity) л“ұмқ„ мӮ°м •н• мҲҳ мһҲлӢӨ(Table 1).
TableВ 1
Equation for Each Evaluation Index
| Classification | Equation |
|---|---|
| Accuracy |
|
| Error Rate |
|
| Sensitivity |
|
| Precision |
|
| Specificity |
|
F1-scoreлҠ” мһ„кі„к°’(threshold)мқ„ мқҙлҸҷмӢңнӮӨл©° лӘЁл“ мһ„кі„к°’м—җ н•ҙлӢ№н•ҳлҠ” м •л°Җм„ұ(precision)кіј лҜјк°җлҸ„(recall) л°Ҹ мқҙл“Өмқҳ мЎ°нҷ”нҸүк· мқ„ кі„мӮ°н•ҳм—¬ н•ҙлӢ№ ThresholdмҷҖ performanceм—җ лҢҖн•ң мўҢн‘ңлЎң мқҙлЈЁм–ҙ진 кіЎм„ мқҙлӢӨ(Fawcett, 2006; Lee et al., 2021). F1-scoreлҠ” м •л°Җм„ұкіј лҜјк°җлҸ„лҘј мқҙмҡ©н•ҳм—¬ лӢӨмқҢкіј к°ҷмқҙ мӮ°м •н• мҲҳ мһҲмңјл©°, мқјл°ҳм ҒмңјлЎң ОІлҠ” 1лЎң н‘ңкё°н•ңлӢӨ.
3. м ҖлҘҳн•ЁмҲҳ л°Ҹ AI кё°л°ҳмқҳ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ• к°ңл°ң
3.1 к°•мҡ°мӮ¬мғҒ м„ м •
к°•мҡ°мӮ¬мғҒ(event)мқ„ м„ м •н•ҳкё° мң„н•ҙ, лӮЁм–‘мЈјмӢң(진кҙҖкөҗ)мқҳ 2008л…„ 1мӣ” 1мңҢл¶Җн„° 2020л…„ 12мӣ” 31мқјк№Ңм§Җ нҷҚмҲҳкё°м—җ н•ҙлӢ№н•ҳлҠ” 6мӣ”л¶Җн„° 9мӣ”к№Ңм§Җмқҳ мҲҳмң„к°Җ 1 m мқҙмғҒмқј л•ҢлҘј нҷ•мқён•ҳмҳҖлӢӨ. нҷҚмҲҳнҶөм ңмҶҢм—җм„ңлҠ” нҷҚмҲҳм •ліҙм ңкіөмӢңмҠӨн…ңмқ„ нҷңмҡ©н•ҳм—¬ нҠ№лі„м§Җм •мҲҳмң„ л°Ҹ кҙҖлҰ¬мҲҳмң„ мҙҲкіјмӢң SNS м „мҶЎмқ„ нҶөн•ң мӢӨмӢңк°„ мҲҳмң„м •ліҙлҘј м ңкіөн•ҳкі мһҲлӢӨ(Ministry of Environment, 2020). мҷ•мҲҷмІң нҮҙкі„мӣҗ м§Җм җмқҳ м§Җм •мҲҳмң„лҠ” 1 mмқҙлӢӨ.
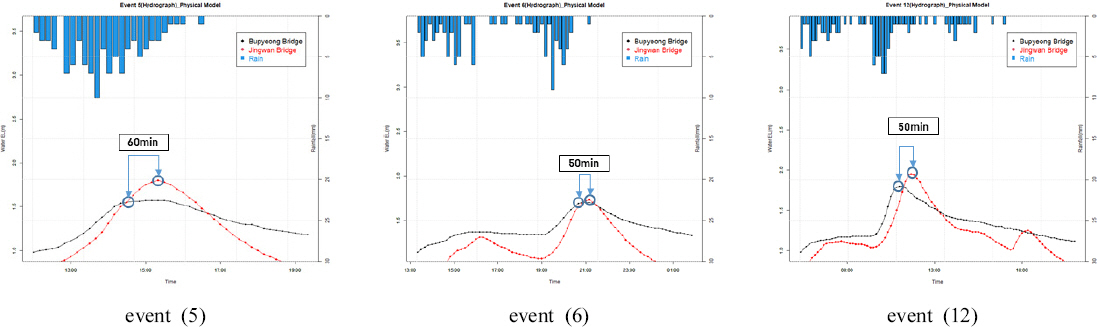
к·ёлҰ¬кі мң лҹүмқҙ мң м—ӯмқҳ мғҒлҘҳм—җм„ң н•ҳлҘҳк№Ңм§Җ лҸ„лӢ¬н•ҳлҠ” мӢңк°„ к°„кІ©мқ„ кі л Өн•ҳкё° мң„н•ҙ, к°•мҡ°мӮ¬мғҒлі„ мғҒлҘҳм—җ мң„м№ҳн•ң лӮЁм–‘мЈјмӢң(л¶ҖнҸүкөҗ)мқҳ мөңкі мҲҳмң„к°Җ лҸ„лӢ¬н•ң мӢңк°„кіј н•ҳлҘҳм—җ мң„м№ҳн•ң лӮЁм–‘мЈјмӢң(진кҙҖкөҗ)мқҳ мөңкі мҲҳмң„мқҳ мӢңк°„ к°„кІ©мқ„ нҢҢм•…н•ҳмҳҖлӢӨ. к°•мҡ°мӮ¬мғҒлі„ мӢңк°„ к°„кІ©мқҖ 50분м—җм„ң 90분 к°„кІ©мңјлЎң нҢҢм•…лҗҳм—ҲлӢӨ(Fig. 7). л”°лқјм„ң, м„ н–үмӢңк°„ кі л Өн•ң к°•мҡ°мӮ¬мғҒмқ„ мҙқ 40к°ң мӮ¬мғҒмқ„ м„ м •н•ҳмҳҖлӢӨ. м„ м •лҗң к°•мҡ°мӮ¬мғҒмқҖ Table 2мҷҖ к°ҷлӢӨ.
Fig.В 7
The Time Interval between the Peak of the Upstream Water Level Observatory and the Downstream Water Level Observatory
TableВ 2
Rainfall Event Selection Considering the Preceding Time
3.2 м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҳ л§Өк°ңліҖмҲҳ кө¬м„ұ
м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ к°•мҲҳлҹүмңјлЎңл¶Җн„° мң м¶ңлҹүмқ„ кі„мӮ°н•ҳкі кі„мӮ°лҗң нҷҚмҲҳлҹүмқ„ мҲҳмң„-мң лҹү кҙҖкі„лЎңл¶Җн„° мҲҳмң„лЎң нҷҳмӮ°н•ҳм—¬ нҷҚмҲҳнҠ№ліҙ м—…л¬ҙлҘј мҲҳн–үн•ҳкі мһҲлӢӨ. м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ 4лҢҖк°• мӮ¬м—… кө¬к°„кіј мЈјмҡ” м§ҖлҘҳмқҳ мң м¶ңкө¬мЎ°лҘј ліҙмҷ„н•ҳкі , л§Өк°ңліҖмҲҳлҘј мһ¬мӮ°м •н•ҳм—¬ нҷңмҡ©н•ҳкі мһҲлӢӨ. нҷҚмҲҳнҶөм ңмҶҢм—җм„ңлҠ” мҲҳл¬ён•ҷм Ғ мҳҲмёЎлӘЁнҳ•мқҳ м „л©ҙм Ғмқё ліҙмҷ„ лҢҖмӢ мЈјмҡ” м§Җм җм—җ лҢҖн•ң л¶Җ분м Ғмқё ліҙмҷ„мқ„ мҲҳн–үн•ҳмҳҖлӢӨ(Kim, Lee et al., 2022). м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ кё° кө¬м¶•лҗң лӘЁнҳ•м—җ мң м—ӯмқҳ м ҖлҘҳмғҒмҲҳ(K, P, Tl) л°Ҹ мң м¶ңлҘ (f1, fsa, Rsa)мқ„ мЎ°м •н•ҳм—¬м•ј н•ңлӢӨ. мҷ•мҲҷмІң мң м—ӯм—җ л§һкІҢ мң м¶ңмғҒмҲҳ л°Ҹ м ҖлҘҳмғҒмҲҳлҘј мЎ°м •н•ҳм—¬ лӮЁм–‘мЈјмӢң(진кҙҖкөҗ)мқҳ нҷҚмҲҳлҹүмқ„ мӮ°м •н•ҳмҳҖлӢӨ. лҳҗн•ң, мӮ°м •лҗң нҷҚмҲҳлҹүмқ„ мҲҳмң„-мң лҹү кҙҖкі„ кіЎм„ мӢқмқ„ нҷңмҡ©н•ҳм—¬ мҲҳмң„лЎң ліҖнҷҳн•ҳмҳҖкі л№„көҗ 분м„қмқ„ мң„н•ҙ, event 28л¶Җн„° 40к№Ңм§ҖлҠ” кІҖвӢ…ліҙм •н•ҳм§Җ м•ҠмқҖ л§Өк°ңліҖмҲҳлҘј м Ғмҡ©н•ҳмҳҖлӢӨ. мҙҲкё°мң м¶ңлҘ , нҸ¬нҷ”мң м¶ңлҘ , нҸ¬нҷ”мҡ°лҹүмқҖ кі м • к°’мқ„ нҷңмҡ©н•ҳмҳҖмңјл©°, м ҖлҘҳмғҒмҲҳ(K, P, Tl)мқҖ к°Ғ к°•мҡ° мӮ¬мғҒлі„ мӮ°м •н•ҳмҳҖлӢӨ. Table 3м—җм„ңлҠ” к°Ғ к°•мҡ° мӮ¬мғҒлі„ мӮ°м •лҗң л§Өк°ңліҖмҲҳлҘј лӮҳнғҖлӮҙм—ҲлӢӨ.
TableВ 3
Estimation of Optimal Parameters for Each Rainfall Event of the Storage Function Model
3.3 AI кё°л°ҳ лӘЁнҳ•мқҳ мһ…л ҘмһҗлЈҢ
AI кё°л°ҳ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳкё° мң„н•ҙ, мў…мҶҚліҖмҲҳлЎң лӮЁм–‘мЈјмӢң(진кҙҖкөҗ, A) мҲҳмң„ мһҗлЈҢлҘј 10분 лӢЁмң„лЎң мқҙмҡ©н•ҳмҳҖлӢӨ. лҸ…лҰҪліҖмҲҳ(independent variable)лЎң лӮЁм–‘мЈјмӢң(л¶ҖнҺ‘көҗ, B) мҲҳмң„ мһҗлЈҢ л°Ҹ лӮЁм–‘мЈјмӢң(кёҲкіЎмҙҲкөҗ, C), лӮЁм–‘мЈјмӢң(진кҙҖкөҗ, D), нҸ¬мІңмӢң(진лӘ©лҰ¬, E), нҸ¬мІңмӢң(лӮҙмҙҢл©ҙмӮ¬л¬ҙмҶҢ, F), лӮЁм–‘мЈјмӢң(м§„м ‘мқҚмӮ¬л¬ҙмҶҢ, G)мқҳ к°•мҡ° мһҗлЈҢлҘј 10분 лӢЁмң„лЎң мқҙмҡ©н•ҳмҳҖлӢӨ(Table 4).
TableВ 4
Basic Statistics of Input Data of AI-based Model
3.4 нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ• к°ңл°ң л°Ҹ м Ғмҡ© кІ°кіјмқҳ 비көҗ
нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳкі мһҗ көӯлӮҙ нҷҚмҲҳ мҳҲвӢ…кІҪліҙлҘј мң„н•ҙ мЈјлЎң мқҙмҡ©н•ҳкі мһҲлҠ” м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқ„ к°Ғ eventлі„ мөңм Ғмқҳ л§Өк°ңліҖмҲҳлҘј мӮ°м •н•ҳмҳҖлӢӨ. мқҙлҘј л°”нғ•мңјлЎң нҷҚмҲҳлҹүмқ„ мӮ°м •н•ҳмҳҖмңјл©°, мҲҳмң„-мң лҹүкҙҖкі„ кіЎм„ мӢқмқ„ м Ғмҡ©н•ҳм—¬ мҲҳмң„лЎң ліҖнҷҳн•ҳкі мҳҲмёЎл Ҙ нҸүк°ҖлҘј мӢӨмӢңн•ҳмҳҖлӢӨ. м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ кіјкұ° к°•мҡ°мӮ¬мғҒм—җ л§һ추м–ҙ л§Өк°ңліҖмҲҳлҘј мЎ°м •н•ЁмңјлЎңмҚЁ кіјкұ° мһҗлЈҢлҘј кё°мӨҖмңјлЎң м •нҷ•лҸ„ мёЎл©ҙм—җм„ңлҠ” мҡ°мҲҳн•ң лӘЁнҳ•мһ„мқ„ нҷ•мқён• мҲҳ мһҲм—ҲлӢӨ. к·ёлҹ¬лӮҳ м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ мғҲлЎңмҡҙ к°•мҡ° л°Ҹ мҲҳмң„ мһҗлЈҢм—җ л§һ추м–ҙ мғҲлЎӯкІҢ л§Өк°ңліҖмҲҳлҘј мһ¬ мЎ°м •н•ҙм•ј н•ңлӢӨлҠ” лӢЁм җмқҙ мһҲлӢӨ.
AI кё°л°ҳ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳкі мһҗ лӘЁнҳ•мқҳ н•ҷмҠөкө¬к°„мқҖ 2008л…„л¶Җн„° 2018л…„к№Ңм§Җ 1,765к°ң мһҗлЈҢлҘј нҷңмҡ©н•ҳмҳҖкі нҸүк°Җкө¬к°„мқҖ 2019л…„л¶Җн„° 2020л…„к№Ңм§Җ 927к°ң мһҗлЈҢлҘј нҷңмҡ©н•ҳмҳҖлӢӨ. м ҒмқҖ мһҗлЈҢмқҳ мҲҳ л°Ҹ кі м •лҗң н•ҷмҠөкө¬к°„мқҳ мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ л°ңмғқн•ҳлҠ” кіјм Ғн•©мқ„ л°©м§Җн•ҳкё° мң„н•ҙ 10 k-fold cross validation л°©лІ•мқ„ м Ғмҡ©н•ҳмҳҖлӢӨ. мҰү, DNN, LSTM мҙқ 2к°Җм§Җ лӘЁнҳ•мқ„ мқҙмҡ©н•ҳм—¬ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ к°ңл°ңн•ҳмҳҖлӢӨ. DNN лӘЁнҳ•мқҖ лӢӨм–‘н•ң лҸ…лҰҪліҖмҲҳлҘј мқҙмҡ©н•ҳм—¬ мҳҲмёЎмқ„ мҲҳн–үн• кІҪмҡ° мҳҲмёЎл Ҙ нҸүк°Җ кІ°кіјк°Җ мҡ°мҲҳн•ҳкІҢ лӮҳнғҖлӮ¬лӢӨ. LSTM лӘЁнҳ•мқҖ лӢӨм–‘н•ң лҸ…лҰҪліҖмҲҳлҘј мқҙмҡ©н•ҳм—¬ мҳҲмёЎмқ„ мҲҳн–үн• кІҪмҡ° м •нҷ•лҸ„к°Җ лӮ®м•„м§җмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ.
DNN лӘЁнҳ•мқҖ лӢЁмқј мһ…л ҘмһҗлЈҢлҘј нҷңмҡ©н•ҳм—¬ мҳҲмёЎ лӘЁнҳ•мқ„ кө¬м„ұн•ҳлҠ” кІғ ліҙлӢЁ, лӢӨм–‘н•ң мһ…л ҘмһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ мһҗлЈҢк°„мқҳ м—°кІ°м„ұмқ„ кі л Өн•ҳм—¬ кө¬м¶•н•ҳм—¬м•ј н•ҳлҠ” лӘЁнҳ•мқҙлӢӨ. LSTM лӘЁнҳ•мқҖ лӢЁмқј мһ…л Ҙ мһҗлЈҢлҘј нҷңмҡ©н•ҳм—¬ мһҗкё° лҚ°мқҙн„°лҘј мқҙмҡ©н•ң мҳҲмёЎм—җ мһҲм–ҙ мҡ°мҲҳн•ң нҸүк°Җ кІ°кіјлҘј лҸ„м¶ңн•ҳлҠ” лӘЁнҳ•мқҙлӢӨ. л”°лқјм„ң, мҳ¬л°”лҘё мһ…л Ҙ мһҗлЈҢмҷҖ лӘЁнҳ•мқҳ мһҘм җмқ„ кі л Өн•ңлӢӨл©ҙ, мҳҲмёЎл Ҙмқҙ мҡ°мҲҳн•ң лӘЁнҳ•мқ„ к°ңл°ңн• мҲҳ мһҲлӢӨ. Figs. 8, 9лҠ” нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ• кІ°кіјлҘј мҳҲмӢңлЎң лӮҳнғҖлғҲлӢӨ.
Fig.В 8
Comparison of Flood Water Level Predictions Using Observed Values and Storage Function Models
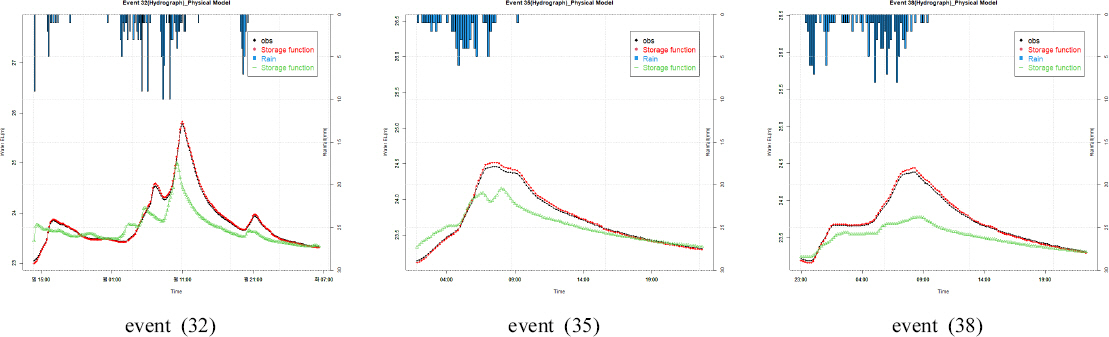
Fig.В 9
Comparison of Flood Water Level Predictions Using Observed Values and Storage Function Models

DNN л°Ҹ LSTM лӘЁнҳ•мңјлЎңл¶Җн„° мҳҲмёЎлҗң нҷҚмҲҳмң„лҠ” кҙҖмёЎ мҲҳмң„мҷҖ кІҪн–Ҙм„ұмқҙ 비мҠ·н•ң кІ°кіјлҘј ліҙмҳҖлӢӨ. м „л°ҳм ҒмңјлЎң нҷҚмҲҳмң„мқҳ ліҖлҸҷм„ұмқ„ мһҳ лӘЁмқҳн•ҳмҳҖмқ„ лҝҗл§Ң м•„лӢҲлқј мҙқ мң м¶ңлҹү(мҲҳмң„)м—җ лҢҖн•ң лӘЁмқҳ кІ°кіјлҸ„ лҶ’мқҖ мҳҲмёЎ м„ұлҠҘмқ„ нҷ•мқён• мҲҳ мһҲм—ҲлӢӨ(Table 5).
4. мҷ•мҲҷмІңмқҳ нҷҚмҲҳн”јн•ҙ мҳҲвӢ…кІҪліҙ кё°лІ• к°ңл°ң
көӯлӮҙ мһ¬лӮң лҢҖ비вӢ…лҢҖмқ‘ м—…л¬ҙлҠ” мң„кё°кІҪліҙлҘј л°”нғ•мңјлЎң мқҙлЈЁм–ҙм§ҖлҠ”лҚ°, нҷҚмҲҳ кҙҖл Ё мң„кё°кІҪліҙлҠ” нҷҚмҲҳнҠ№ліҙ(нҷҚмҲҳнҶөм ңмҶҢ кҙҖн• )мҷҖ нҳёмҡ°нҠ№ліҙ(кё°мғҒмІӯ кҙҖн• )лЎң кө¬л¶„лҗңлӢӨ. көӯлӮҙ нҷҚмҲҳ мҳҲкІҪліҙлҠ” лҢҖн•ҳмІң мң„мЈјлЎң кө¬м¶•лҗҳм–ҙ мһҲмңјлӮҳ нҷҚмҲҳн”јн•ҙлҠ” мӨ‘вӢ…мҶҢн•ҳмІң лӢЁмң„лЎң л°ңмғқн•ңлӢӨ. лҳҗн•ң, кё°мЎҙм—җ мҡҙмҳҒлҗҳм—ҲлҚҳ нҷҚмҲҳнҠ№ліҙлҠ” мқјкҙҖлҗң кё°мӨҖмңјлЎң мқён•ҙ, нҷҚмҲҳ мЈјмқҳліҙ(кі„нҡҚнҷҚмҲҳлҹүмқҳ 50% мқҙмғҒ, кі„нҡҚнҷҚмҲҳмң„мқҳ 60% мҳҲмғҒлҗ л•Ң) л°Ҹ нҷҚмҲҳ кІҪліҙ(кі„нҡҚнҷҚмҲҳлҹүмқҳ 70% мқҙмғҒ, кі„нҡҚнҷҚмҲҳмң„мқҳ 80% мҳҲмғҒлҗ л•Ң)к°Җ л°ңл №лҗҳм§Җ м•Ҡм•„лҸ„ н”јн•ҙк°Җ л°ңмғқн•ҳлҠ” мӮ¬лЎҖк°Җ л№ҲлІҲн•ҳлӢӨ. нҳёмҡ°нҠ№ліҙлҠ” нҷҚмҲҳ л°Ҹ м№ЁмҲҳм—җ лҢҖмқ‘н•ҳкі мһҗ мҙқк°•мҡ°лҹүмқ„ кё°мӨҖмңјлЎң мҡҙмҳҒлҗҳкі мқјкҙҖлҗң кё°мӨҖмқ„ м Ғмҡ©н•ҳкі мһҲлӢӨ. нҳёмҡ°м—җ мқҳн•ң н”јн•ҙ к°ҖлҠҘм„ұмқ„ лҜёлҰ¬ мҳҲмғҒн•ҳкі нҠ№ліҙлҘј л°ңнҡЁн•ҙм•ј н•ҳлҠ” кІҪмҡ°, кё°мЎҙмқҳ нҠ№ліҙ кё°мӨҖмқҖ к°•мҡ° лҲ„м Ғ мӢңк°„мқҙ нҳёмҡ°нҠ№ліҙ кё°мӨҖм—җ лҸ„лӢ¬н• л•Ңк№Ңм§Җ кё°лӢӨл Өм•ј н•ңлӢӨ. л”°лқјм„ң, ліё м—°кө¬м—җм„ңлҠ” мӢӨмӢңк°„мңјлЎң нҷҚмҲҳмң„лҘј мҳҲмёЎн•ҳкі мҳҲмёЎлҗң нҷҚмҲҳмң„лҘј мқҙмҡ©н•ҳм—¬ мң„н—ҳ мҲҳмӨҖмқ„ л°ңл №н• мҲҳ мһҲлҠ” кё°мӨҖмқ„ м„Өм •н•ҳкі мһҗ н•ңлӢӨ. м„Өм •лҗң кё°мӨҖмқ„ к·јкұ°лЎң нҷҚмҲҳн”јн•ҙ мҳҲвӢ…кІҪліҙ кё°лІ•мқ„ к°ңл°ңн•ҳкі м ңм•Ҳн•ҳкі мһҗ н•ңлӢӨ.
4.1 нҷҚмҲҳн”јн•ҙ кі„кёүкө¬к°„ 분лҘҳ мҳҲмёЎ лӘЁнҳ• к°ңл°ңмқ„ мң„н•ң мһҗлЈҢ кө¬м¶•
мҲҳмң„ л°Ҹ к°•мҡ° мһҗлЈҢлҘј м—°кі„н•ҳм—¬ нҷҚмҲҳн”јн•ҙ кі„кёүкө¬к°„ 분лҘҳ кё°мӨҖмқ„ м„Өм •н•ҳкі мһҗ к°Ғ eventлі„ мөңкі мҲҳмң„, лҲ„м Ғк°•мҡ°лҹү, көӯк°Җмһ¬лӮңкҙҖлҰ¬м •ліҙмӢңмҠӨн…ң(national disaster management system, NDMS) мһҗлЈҢлҘј мқҙмҡ©н•ҳмҳҖлӢӨ. мөңкі мҲҳмң„, лҲ„м Ғк°•мҡ°лҹү, NDMS мһҗлЈҢм—җ лҢҖн•ң нҷ•лҘ л°ҖлҸ„ н•ЁмҲҳf(x)мҷҖ кө¬к°„[a,b]м—җ лҢҖн•ҙм„ң нҷ•лҘ ліҖмҲҳXк°Җ нҸ¬н•Ёлҗ нҷ•лҘ P(aвүӨXвүӨb)лҘј мӮ°м •н•ңлӢӨ. мқҙлҘј л°”нғ•мңјлЎң мЈјм–ҙ진 нҷ•лҘ ліҖмҲҳк°Җ нҠ№м • к°’ліҙлӢӨ мһ‘кұ°лӮҳ к°ҷмқҖ нҷ•лҘ мқ„ мӮ°м •н•ҳкі мһҗ лҲ„м Ғ 분нҸ¬ н•ЁмҲҳлҘј мқҙмҡ©н•ҳмҳҖлӢӨ. мқҙлҘј л°”нғ•мңјлЎң нҷҚмҲҳн”јн•ҙ мӣҗмқё 분лҘҳлҘј мң„н•ң мҲҳмң„ л°Ҹ к°•мҡ° кё°мӨҖмқ„ м„Өм •н•ҳмҳҖлӢӨ. Class 1мқҖ мҲҳмң„, к°•мҡ° л°Ҹ NDMS мһҗлЈҢк°Җ 0%л¶Җн„° 25% мӮ¬мқҙмқҳ кө¬к°„мқ„ мқҳлҜён•ҳл©°, Class 2лҠ” мҲҳмң„, к°•мҡ° л°Ҹ NDMS мһҗлЈҢк°Җ 26%л¶Җн„° 50%, Class 3мқҖ 51%л¶Җн„° 75%, Class 4лҠ” 76%л¶Җн„° 100%к№Ңм§ҖлҘј мқҳлҜён•ңлӢӨ(Table 6).
TableВ 6
Set Standards for Classification of Flood Damage Class Sections
| Classification | Highest water level (EL.m) | Accumulation rainfall (mm) | Flood damage (1,000 won) |
|---|---|---|---|
| 75% | 25.15 | 70 | 1,000,000 |
| 50% | 24.25 | 50 | 100,000 |
| 25% | 23.85 | 30 | 1,000 |
н•ҳлҘҳм—җ мң„м№ҳн•ң лӮЁм–‘мЈјмӢң(진кҙҖкөҗ)мқҳ мҲҳмң„лҠ” мғҒлҘҳм—җ мң„м№ҳн•ң лӮЁм–‘мЈјмӢң(л¶ҖнҸүкөҗ) мҲҳмң„м—җ мҳҒн–Ҙмқ„ л°ӣмңјл©°, мЈјліҖ к°•мҡ° кҙҖмёЎмҶҢмқҳ к°•мҡ°лҹүм—җ мҳҒн–Ҙмқ„ л°ӣлҠ”лӢӨ. мң м—ӯм—җ лӮҙлҰ¬лҠ” к°•мҡ°лҠ” мң м—ӯ нҶ м–‘м—җ нқЎмҲҳлҗҳм–ҙ н•ҳлҘҳлЎң нқҳлҹ¬к°„лӢӨ. лҳҗн•ң, мғҒлҘҳмқҳ мҲҳмң„к°Җ лҶ’м•„м§Җкұ°лӮҳ лӮ®м•„진лӢӨл©ҙ, мқҙ мҳҒн–ҘмқҖ н•ҳлҘҳм—җ мң„м№ҳн•ң мҲҳмң„ кҙҖмёЎмҶҢм—җ мҳҒн–Ҙмқ„ мЈјкё° л•Ңл¬ём—җ мң м—ӯм—җм„ң л°ңмғқн•ҳлҠ” мң м¶ң л°Ҹ к°•мҡ°лҠ” н•ҳлҘҳм—җ м§Ғм ‘м Ғмқё мҳҒн–Ҙмқ„ мӨҖлӢӨ. мқҙлҹ¬н•ң мҳҒн–Ҙмқ„ кі л Өн•ҳм—¬, к°Ғ eventлі„ кҙҖмёЎ мҲҳмң„ л°Ҹ к°•мҡ°кҙҖмёЎмҶҢ мһҗлЈҢлҘј 2008л…„л¶Җн„° 2020л…„к№Ңм§Җ 10분лӢЁмң„лЎң кө¬м¶•н•ҳмҳҖлӢӨ. AI кё°л°ҳ лӘЁнҳ•мқ„ мқҙмҡ©н•ң нҷҚмҲҳмң„ мҳҲмёЎ кІ°кіјлҘј н‘ңкі мҲҳмң„лЎң нҷҳмӮ°н•ҳмҳҖмңјл©°, мҙқ 5к°ңмқҳ к°•мҡ°кҙҖмёЎмҶҢмқҳ к°•мҡ°лҹү мһҗлЈҢлҘј мқҙмҡ©н•ҳмҳҖлӢӨ.
4.2 нҷҚмҲҳн”јн•ҙ кі„кёүкө¬к°„ 분лҘҳ мҳҲмёЎ лӘЁнҳ• к°ңл°ң
분лҘҳ(classification) л¬ём ңлҠ” лҸ…лҰҪліҖмҲҳм—җ л”°лқј к°ҖмһҘ м—°кҙҖм„ұмқҙ нҒ° мў…мҶҚліҖмҲҳ(кі„кёүкө¬к°„)лҘј мҳҲмёЎн•ҳлҠ” л¬ём ңмқҙлӢӨ. мҰү, м–ҙл–Ө н‘ңліём—җ лҢҖн•ң лҚ°мқҙн„°к°Җ мЈјм–ҙмЎҢмқ„ л•Ң, н‘ңліёмқҙ м–ҙл–Ө кі„кёүкө¬к°„м—җ мҶҚн•ҳлҠ”м§ҖлҘј м•Ңм•„лӮҙлҠ” л°©лІ•мқҙлӢӨ. ліё м—°кө¬м—җм„ңлҠ” мҲҳмң„ л°Ҹ к°•мҡ°лЎң мқён•ҙ к°Җк№Ңмҡҙ лҜёлһҳм—җ л°ңмғқн• мҲҳ мһҲлҠ” н”јн•ҙмқҳ к·ңлӘЁлҘј к°ңлһөм ҒмңјлЎң нҢҢм•…н•ҳкі мһҗ н•ңлӢӨ. л”°лқјм„ң, XGBoost, лһңлҚӨнҸ¬л ҲмҠӨнҠё лӘЁнҳ•мқ„ м Ғмҡ©н•ҳкі мһҗ н•ҳмҳҖлӢӨ.
нҷҚмҲҳн”јн•ҙ кі„кёүкө¬к°„ 분лҘҳ мҳҲмёЎ лӘЁнҳ•мқҳ н•ҷмҠөкө¬к°„мқҖ 2008л…„л¶Җн„° 2016л…„к№Ңм§Җ 1,312к°ң мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ 10 Fold Cross Validationмқ„ м Ғмҡ©н•ҳмҳҖкі нҸүк°Җкө¬к°„мқҖ 2017л…„л¶Җн„° 2019л…„к№Ңм§Җ 547к°ң мһҗлЈҢлҘј нҷңмҡ©н•ҳмҳҖлӢӨ. мһ…л ҘмһҗлЈҢм—җ л§һ추м–ҙ XGBoost лӘЁнҳ•мқҳ л§Өк°ңліҖмҲҳлҘј мөңм Ғнҷ”н•ҳкі лӘЁнҳ•мқҳ мҳҲмёЎ м„ұлҠҘмқ„ нҸүк°Җн•ҳкё° мң„н•ҙ, 2017л…„л¶Җн„° 2019л…„к№Ңм§Җмқҳ мһ…л ҘмһҗлЈҢлҘј л°”нғ•мңјлЎң лӘЁнҳ•мқҳ мҳҲмёЎ м„ұлҠҘмқ„ нҸүк°Җн•ҳмҳҖлӢӨ(Table 7).
TableВ 7
Flood Damage Classification Prediction Model Performance Evaluation using XGBoost (Evaluation Section)
| XGBoost | Observation | ||||
|---|---|---|---|---|---|
|
|
|||||
| 1 | 2 | 3 | 4 | ||
| Prediction | 1 | 430 | 5 | 0 | 0 |
| 2 | 3 | 27 | 10 | 0 | |
| 3 | 0 | 4 | 57 | 0 | |
| 4 | 0 | 0 | 1 | 10 | |
Confusion MatrixлҘј мӮҙнҺҙліҙл©ҙ, Class 1, Class 3, Class 4м—җм„ң лҶ’мқҖ мҳҲмёЎл Ҙмқ„ ліҙмҳҖмңјл©°, Class 2м—җм„ңлҠ” мғҒлҢҖм ҒмңјлЎң лӮ®мқҖ мҳҲмёЎл Ҙмқ„ ліҙмҳҖлӢӨ. лӘЁл“ Classм—җ лҢҖн•ң мҳҲмёЎл Ҙ кІ°кіј, F1-scoreк°Җ 0.89лЎң мҡ°мҲҳн•ң мҳҲмёЎл Ҙмқ„ лӮҳнғҖлғ„мқ„ м•Ң мҲҳ мһҲлӢӨ. Table 8мқҖ XGBoostлҘј нҷңмҡ©н•ң нҷҚмҲҳн”јн•ҙ 분лҘҳ мҳҲмёЎ лӘЁнҳ•мқҳ м •нҷ•лҸ„лҘј лӮҳнғҖлғҲлӢӨ.
TableВ 8
Flood Damage Classification Prediction Model Accuracy Evaluation Using XGBoost (Evaluation Section)
| Class | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Sensitivity | 0.99 | 0.75 | 0.83 | 1.00 |
| Specificity | 0.95 | 0.97 | 0.99 | 0.99 |
| Precision | 0.99 | 0.75 | 0.84 | 1.00 |
| Recall | 0.99 | 0.68 | 0.93 | 0.91 |
| F1-score | 0.89 | |||
мһ…л ҘмһҗлЈҢм—җ л§һ추м–ҙ лһңлҚӨнҸ¬л ҲмҠӨнҠёмқҳ л§Өк°ңліҖмҲҳлҘј мөңм Ғнҷ”н•ҳкі лӘЁнҳ•мқҳ мҳҲмёЎ м„ұлҠҘмқ„ нҸүк°Җн•ҳкё° мң„н•ҙ, лӘЁнҳ•мқ„ кө¬м„ұн• л•Ң мӮ¬мҡ©н•ҳм§Җ м•ҠмқҖ мһ…л ҘмһҗлЈҢлҘј л°”нғ•мңјлЎң лӘЁнҳ•мқҳ мҳҲмёЎ м„ұлҠҘмқ„ нҸүк°Җн•ҳмҳҖлӢӨ. Table 9лҠ” лһңлҚӨнҸ¬л ҲмҠӨнҠёлҘј нҷңмҡ©н•ң нҷҚмҲҳн”јн•ҙ 분лҘҳ лӘЁнҳ•мқҳ нҸүк°Җкө¬к°„м—җ лҢҖн•ң кІ°кіјмқҙлӢӨ.
TableВ 9
Flood Damage Classification Prediction Model Performance Evaluation Using Random Forest (Evaluation Section)
| Random forest | Observation | ||||
|---|---|---|---|---|---|
|
|
|||||
| 1 | 2 | 3 | 4 | ||
| Prediction | 1 | 430 | 3 | 0 | 0 |
| 2 | 3 | 29 | 5 | 0 | |
| 3 | 0 | 4 | 62 | 2 | |
| 4 | 0 | 0 | 1 | 8 | |
Confusion MatrixлҘј мӮҙнҺҙліҙл©ҙ, Class 1, Class 2, Class 3, Class 4м—җм„ң лҶ’мқҖ мҳҲмёЎл Ҙмқ„ ліҙмҳҖлӢӨ. лӘЁл“ Classм—җ лҢҖн•ң мҳҲмёЎл Ҙ кІ°кіј, F1-scoreк°Җ 0.89лЎң мҡ°мҲҳн•ң мҳҲмёЎл Ҙмқ„ лӮҳнғҖлғ„мқ„ м•Ң мҲҳ мһҲлӢӨ. Table 10мқҖ лһңлҚӨнҸ¬л ҲмҠӨнҠёлҘј нҷңмҡ©н•ң нҷҚмҲҳн”јн•ҙ 분лҘҳ мҳҲмёЎ лӘЁнҳ•мқҳ м •нҷ•лҸ„лҘј лӮҳнғҖлғҲлӢӨ.
4.3 нҷҚмҲҳн”јн•ҙ мҳҲвӢ…кІҪліҙ кё°лІ• м Ғмҡ©м„ұ нҸүк°Җ
ліё м—°кө¬м—җм„ңлҠ” мҙқ 4к°Җм§Җ лӘЁнҳ•мқ„ к°ңл°ңн•ЁмңјлЎңмҚЁ мҲҳмң„ л°Ҹ к°•мҡ°к°Җ мҰқк°Җн• л•Ң нҷҚмҲҳн”јн•ҙм—җ лҢҖн•ң кі„кёүкө¬к°„ 분лҘҳ мҳҲмёЎ кё°мҲ мқ„ м ңмӢңн•ҳмҳҖлӢӨ. нҷҚмҲҳн”јн•ҙ 분лҘҳ мҳҲмёЎ кё°мҲ мқҳ м Ғмҡ©м„ұмқ„ кІҖнҶ н•ҳкё° мң„н•ҙ, лӘЁнҳ•мқ„ кө¬м¶•н• л•Ң н•ҷмҠөм—җ нҷңмҡ©лҗҳм§Җ м•ҠмқҖ 2020л…„ мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ лӘЁнҳ•лі„ мҳҲмёЎ м„ұлҠҘмқ„ 비көҗн•ҳмҳҖлӢӨ.
Class 1м—җм„ң 2к°Җм§Җ лӘЁнҳ•мқ„ 비көҗ нҸүк°Җ н•ҳмҳҖмқ„ л•Ң, мҳ¬л°”лҘҙкІҢ мҳҲмёЎн•ң к°’мқҖ лӢӨмқҢкіј к°ҷлӢӨ. XGBoost : 699, лһңлҚӨнҸ¬л ҲмҠӨнҠё : 699мқҙл©°, мӢӨм ң мһҗлЈҢмқҳ к°ңмҲҳлҠ” 701к°ңлЎң 2к°Җм§Җ лӘЁнҳ•мқҳ мҳҲмёЎл Ҙмқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқё н•ҳмҳҖлӢӨ. Class 2м—җм„ң 2к°Җм§Җ лӘЁнҳ•мқ„ 비көҗ нҸүк°Җ н•ҳмҳҖмқ„ л•Ң, мҳ¬л°”лҘҙкІҢ мҳҲмёЎн•ң к°’мқҖ лӢӨмқҢкіј к°ҷлӢӨ. XGBoost : 48, лһңлҚӨнҸ¬л ҲмҠӨнҠё : 48мқҙл©°, мӢӨм ң мһҗлЈҢмқҳ к°ңмҲҳлҠ” 57к°ңлЎң 2к°Җм§Җ лӘЁнҳ•мқҳ мҳҲмёЎл Ҙмқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқё н•ҳмҳҖлӢӨ. Class 3м—җм„ң 2к°Җм§Җ лӘЁнҳ•мқ„ 비көҗ нҸүк°Җ н•ҳмҳҖмқ„ л•Ң, мҳ¬л°”лҘҙкІҢ мҳҲмёЎн•ң к°’мқҖ лӢӨмқҢкіј к°ҷлӢӨ. XGBoost : 56, лһңлҚӨнҸ¬л ҲмҠӨнҠё : 46мқҙл©°, мӢӨм ң мһҗлЈҢмқҳ к°ңмҲҳлҠ” 61к°ңлЎң XGBoost лӘЁнҳ•мқҳ мҳҲмёЎл Ҙмқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқё н•ҳмҳҖлӢӨ. Class 4м—җм„ң 2к°Җм§Җ лӘЁнҳ•мқ„ 비көҗ нҸүк°Җ н•ҳмҳҖмқ„ л•Ң, мҳ¬л°”лҘҙкІҢ мҳҲмёЎн•ң к°’мқҖ лӢӨмқҢкіј к°ҷлӢӨ. XGBoost : 13, лһңлҚӨнҸ¬л ҲмҠӨнҠё : 13мқҙл©°, мӢӨм ң мһҗлЈҢмқҳ к°ңмҲҳлҠ” 15к°ңлЎң 2к°Җм§Җ лӘЁнҳ•мқҳ мҳҲмёЎл Ҙмқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқё н•ҳмҳҖлӢӨ. лӘЁнҳ•мқ„ кө¬м¶•н• л•Ң н•ҷмҠөм—җ нҷңмҡ©лҗҳм§Җ м•ҠмқҖ 2020л…„ мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬, нҷҚмҲҳн”јн•ҙ 분лҘҳ мҳҲмёЎ кё°мҲ мқҳ м Ғмҡ©м„ұмқ„ нҢҢм•…н•ҳмҳҖлӢӨ. лӘЁнҳ•лі„ Classм—җ лҢҖн•ң мҳҲмёЎ м„ұлҠҘмқҖ XGBoost лӘЁнҳ•мқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқён•ҳмҳҖлӢӨ(Tables 11, 12).
5. кІ° лЎ
кё°нӣ„ліҖнҷ”лЎң мқён•ң 집мӨ‘нҳёмҡ°, лҸҢл°ң нҷҚмҲҳ л“ұмңјлЎң мқён•ҙ мқёлӘ… л°Ҹ мһ¬мӮ°н”јн•ҙк°Җ м җм җ лҚ” мӢ¬к°Ғн•ҙм§Җкі мһҲлӢӨ. нҷҚмҲҳмқҳ к·ңлӘЁ л°Ҹ л°ңмғқл№ҲлҸ„к°Җ кёүмҰқн•Ём—җ л”°лқј мқёлӘ… л°Ҹ мһ¬мӮ° н”јн•ҙлҘј мөңмҶҢнҷ” н• мҲҳ мһҲлҠ” көӯк°ҖнҷҚмҲҳ мҳҲліҙ мӢңмҠӨн…ң кө¬м¶•мқҳ н•„мҡ”м„ұлҸ„ лҢҖл‘җлҗҳкі мһҲлӢӨ. н•ҳм§Җл§Ң, нҷҚмҲҳнҶөм ңмҶҢм—җм„ң мҡҙмҳҒн•ҳкі мһҲлҠ” нҷҚмҲҳ мҳҲвӢ…кІҪліҙ мӢңмҠӨн…ңмқҖ к°•мҡ°-мң м¶ң лӘЁнҳ•мқ„ кё°л°ҳмңјлЎң мЈјмҡ” н•ҳмІң мӨ‘мӢ¬(лҢҖн•ҳмІң)мқҳ мӢңмҠӨн…ңмқҙкё°м—җ мӨ‘вӢ…мҶҢн•ҳмІңм—җ м Ғн•©н•ң лӘЁнҳ•мқ„ к°ңл°ңн•ҳкё° мң„н•ҙ, ліё м—°кө¬м—җм„ңлҠ” к°•мҡ°-мң м¶ң лӘЁнҳ•кіј AI кё°л°ҳ нҷҚмҲҳмң„ мҳҲмёЎ лӘЁнҳ•мқ„ 비көҗ л°Ҹ 분м„қн•ҳкі мһҗ н•ҳмҳҖлӢӨ.
лҜёлһҳмқҳ нҷҚмҲҳмң„лҘј мҳҲмёЎн•ҳкё° мң„н•ҙ көӯлӮҙм—җм„ңлҠ” кіјкұ°мқҳ к°•мҡ° л°Ҹ нҷҚмҲҳлҹүмқ„ нҷңмҡ©н•ҳм—¬ мҡҙмҳҒмӨ‘м—җ мһҲлӢӨ. к·ёлҹ¬лӮҳ нҳ„мһ¬ м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҖ мғҲлЎңмҡҙ мһ…л ҘмһҗлЈҢм—җ л§һ추м–ҙ л§ӨлІҲ м „л¬ёк°Җмқҳ кІҪн—ҳм—җ мқҳмЎҙн•ҳм—¬ л§Өк°ңліҖмҲҳ мЎ°м •мқ„ нҶөн•ң мң м¶ң лӘЁнҳ•мқ„ мЎ°м •н•ҳкі мһҲлӢӨ. лҳҗн•ң, м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҳ л§Өк°ңліҖмҲҳлҘј мЎ°м Ҳн•ҳлҠ” кІҪмҡ° л§Өк°ңліҖмҲҳмқҳ мЎ°м •лІ”мң„ лӮҙм—җм„ң мЎ°м •н•ҳм—¬ нҷҚмҲҳлҹүмқ„ мҳҲмёЎн•ҳм—¬м•ј н•ҳм§Җл§Ң, мқёмң„м ҒмңјлЎң мЎ°м •лІ”мң„ мқҙмғҒмқҳ к°’мқ„ нҷңмҡ©н•ҳлҠ” кІҪмҡ°к°Җ мЎҙмһ¬н•ңлӢӨ. мҰү, кіјкұ° мһҗлЈҢм—җ лҢҖн•ҳм—¬ л§Өк°ңліҖмҲҳмқҳ к°’мқҙ кі м •лҗҳм–ҙ мғҲлЎңмҡҙ мһ…л ҘмһҗлЈҢм—җ лҢҖн•ҳм—¬ мғҲлЎӯкІҢ мЎ°м Ҳн•Ём—җ л”°лқј нҳ„н–ү нҠ№ліҙм—җ лҢҖн•ң м •нҷ•лҸ„ л°Ҹ мӢӨнҡЁм„ұ мёЎл©ҙм—җ лҢҖн•ң л¬ём ңк°Җ м ңкё°лҗҳкі мһҲлӢӨ. кіјкұ° мӮ¬мғҒм—җ л§һ추м–ҙ л§Өк°ңліҖмҲҳлҘј м Ғмҡ©н•ҳм—¬ мЎ°м Ҳн•ҳмҳҖмқ„ кІҪмҡ° м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҙ м „мІҙм ҒмңјлЎң мҳҲмёЎмқҳ м„ұлҠҘмқҖ мўӢм•„ ліҙмқј мҲҳ мһҲмңјлӮҳ, м ҖлҘҳн•ЁмҲҳ лӘЁнҳ•мқҳ л¬ём ңм җ л°Ҹ н•ңкі„м җмқ„ кі л Өн•ңлӢӨл©ҙ AI кё°л°ҳ лӘЁнҳ•мқҳ мҳҲмёЎ м„ұлҠҘмқҙ мҡ°мҲҳн•ҳлӢӨлҠ” кІғмқ„ нҢҢм•…н• мҲҳ мһҲлӢӨ.
нҷҚмҲҳнҠ№ліҙлҠ” кі„нҡҚнҷҚмҲҳлҹүмқ„ кё°мӨҖ, нҳёмҡ°нҠ№ліҙлҠ” лҲ„м Ғк°•мҡ°лҹүмқ„ кё°мӨҖмңјлЎң мң„кё° кІҪліҙ лӢЁкі„к°Җ м„Өм •лҗҳм–ҙ мһҲм–ҙ мӢӨм ң нҷҚмҲҳ л°Ҹ нҳёмҡ°лЎң мқён•ң н”јн•ҙк°Җ л°ңмғқн•ҳкі мһҲм§Җл§Ң, нҠ№ліҙк°Җ л°ңл №лҗҳм§Җ м•ҠлҠ” кІҪмҡ°к°Җ л§ҺмқҖ мӢӨм •мқҙлӢӨ. мң м—ӯмқҳ нҠ№м„ұм—җ л§һ추м–ҙ кё°мӨҖмқ„ м„Өм •н•ҳкі мң„кё°л°ңмғқмқҙ мҳҲмғҒлҗҳлҠ” кІҪмҡ°, мң„н—ҳ мҲҳмӨҖм—җ л¶Җн•©н•ҳлҠ” мЎ°м№ҳлҘј н• мҲҳ мһҲлҸ„лЎқ мӮ¬м „м—җ м •ліҙлҘј м ңкіөн•ҳкі кІҪкі н•ҳкё° мң„н•ҙ, нҷҚмҲҳн”јн•ҙ нҸүк°Җ кё°лІ•мқҙ н•„мҡ”н•ҳлӢӨ.
ліё м—°кө¬м—җм„ң м ңмӢңн•ң AI кё°л°ҳ лӘЁнҳ•мқ„ мқҙмҡ©н•ң нҷҚмҲҳмң„ мҳҲмёЎ л°Ҹ нҷҚмҲҳн”јн•ҙ мң„н—ҳлҸ„ мҳҲвӢ…кІҪліҙ кё°лІ•мқ„ нҷңмҡ©н•ңлӢӨл©ҙ, мҲҳл¬ё м „л¬ёк°Җ л¶Җмһ¬мӢңм—җлҸ„ мӢ мҶҚн•ҳкі м •нҷ•н•ң нҷҚмҲҳ мҳҲвӢ…кІҪліҙ мқҳмӮ¬кІ°м • кіјм •м—җ л§ҺмқҖ лҸ„мӣҖмқҙ лҗ кІғмқҙлӢӨ. лӢӨл§Ң, лӘЁл“ мһҗлЈҢл“Өмқҙ мҲҳл¬ё/кё°мғҒ мһҗлЈҢлҘј кё°л°ҳмңјлЎң кө¬лҸҷлҗҳкё° л•Ңл¬ём—җ л¶Ҳнҷ•мӢӨм„ұмқҙ мЎҙмһ¬н•ңлӢӨ. мқҙлҹ¬н•ң л¶Ҳнҷ•мӢӨм„ұмқ„ мӨ„мқҙкё° мң„н•ҙ мӢ лў°н• л§Ңн•ң мһҗлЈҢмқҳ нҷ•ліҙ л°Ҹ м§ҖмҶҚм Ғмқё м—°кө¬к°Җ мҲҳн–үлҗ н•„мҡ”к°Җ мһҲлӢӨ.




