



1. 서 론
연약지반이 다수 분포되어 있는 해안가를 중심으로 대규모 구조물의 축조가 증가하면서, 지반 침하에 의한 상부 구조물의 손상 등에 세심한 주의가 요구된다. 따라서 다양한 연직배수재를 이용한 연약지반 개량공법의 연구 및 현장 적용이 활발히 진행되고 있으며(Kang et al., 2014), 침하량을 예측하기 위해 Barron (1948), Mikasa (1963), Gibson et al. (1967)에 의한 다양한 압밀 침하이론이 발표되었다. 특히, 현장에서 지반의 침하량을 산정하기 위해서는 압축지수(Cc), 초기 간극비(e0), 성토고 등의 지반정수를 이용하는 Terzaghi 1차 압밀 이론을 주로 활용하므로, 정확한 압축지수의 도출하는 것은 매우 중요할 것이다.
이에 따라 압축지수의 예측을 목적으로 다양한 연구가 국⋅내외로 수행되고 있다. Yoon and Kim (2003)은 자연함수비, 초기 간극비, 비중, 액성한계, 소성지수, 압축지수 값을 통계분석을 통해 다중회귀분석을 실시하여, 압축지수에 대한 회귀식을 도출하였고, Bae and Kim (2009)은 광양항을 대상지역으로 Box-Cox 변수 변환을 수행하여 함수비, 액성한계, 초기 간극비에 대한 압축지수와의 회귀식을 도출하였다.
또한, Kim et al. (2001)은 경북지역을 중심으로 인공신경망을 활용하여 물리적 특성 값에 대한 압축지수 예측 모델을 제안하였으며, Yeo (2015)는 상관분석을 통하여 부산지역의 압축지수, 압축비, 비배수 전단강도를 예측하는 회귀식을 발표하였다. Kim and Lee (2015)는 초연약 점토지반의 압축지수 추청을 위해 원지반과 준설매립점토 사이의 압축지수에 대한 관계식을 수학적으로 증명하였으며, 이를 실제 현장에서의 계측결과와 비교해 검증하였다.
국외에서도 압축지수를 예측하기 위한 연구가 활발히 진행되고 있는 추세이며, Farzin and Afshin (2012)와 Danial et al. (2019)은 각각 인공 신경망(ANN)과 유전 알고리즘을 활용하여 이란의 Marzandaran 지방의 물리적 특성 값을 통해 압축지수를 예측하는 상관관계를 제안하였다. 또한, Talas and Kaya (2018)은 기계학습 알고리즘을 활용하여 터키 일부 지역의 압축지수 예측 모델 제안하였다. 이와 같이, 지역에 따른 지반 특성에 편차가 존재하므로 국외에서는 지역에 따른 압축지수의 예측을 위해 다양한 AI기법들이 활용되고 있으나, 국내의 경우 AI기법을 통한 압축지수 예측 모델에 관한 연구가 미진한 상태이다. 따라서 본 연구에서는 남해안 지역인 부산, 광양, 목포지역의 물리적 특성 값에 따른 압축지수 예측을 위한 기계학습 모델의 성능을 최적화하고 비교하기 위하여 대상지역의 지반정수 데이터를 수집하고 상관분석을 실시하였으며, 기계학습 모델인 Random Forest (RF), Linear Regression (LR) Ridge, Lasso, Deep Neural Network (DNN), SVM, XGBoost, LightGBM에 Hyper Parameter를 최적화하여 적용하고 그 결과를 비교하여 최적의 예측 모델을 선정하고자 하였다.
2. 기계학습 알고리즘
2.1 랜덤포레스트(RandomForest, RF)
RF 알고리즘은 회귀 및 분류 문제를 다수의 Tree로 구성되어 있으며, 이를 활용하여 최적의 결과를 도출하는 알고리즘으로 배깅(Bagging) 기법의 대표적인 모델이다(Breiman, 2001).
문제 해결을 위해 Fig. 1과 같이 Yes or False의 결정을 일반화하여 선택해 나가기 때문에 영향인자 사이의 상관성이 높지 않아도 높은 정확도의 결과를 도출하는 장점을 갖고 있는 모델이다.
2.2 Linear Regression (LR)
Linear Regression은 다중선형회귀를 의미하며, 종속 변수와 다수의 독립변수와의 관계를 설명하는 기법이다(Oh, 2020). 각각의 독립변수에 대해 기울기(가중치)와 절편을 산정하기 때문에, 유의성 및 설명력이 우수한 모델을 구축할 때 주로 활용되고, 산정된 가중치를 이용하여 변수 사이의 유의성이 높은 변수를 선택하기 유용한 특징을 갖고 있다.
2.3 Ridge와 Lasso
Ridge와 Lasso는 기존 회귀분석에서 제약조건을 주어 중요도가 낮은 독립변수의 회귀 값을 축소하여 과적합을 방지하는 기법이다. Ridge는 변수가 다수일 경우 오차를 최소화하여 간단한 모델을 구축할 수 있으며, Lasso는 유의미한 독립변수만 선정하여 모델을 구축하는 특징을 갖고 있다(Jeon, 2019).
2.4 SVM (Support Vector Machine)
SVM은 회귀(SVR)와 분류(SVC) 문제 해결에 적합한 알고리즘으로 과적합에 대해 상대적으로 자유롭다는 장점을 갖고 있으나, 학습 속도가 매우 느리며 도출된 결과의 해석이 어렵다는 단점도 존재한다. SVM은 Fig. 2와 같이 다양한 커넬(Kernel)의 Hyperplane을 활용하여 데이터의 특징을 구분하고 있으며, Hyperplane의 배치와 데이터 사이 거리의 기준점(Margin)을 적절하게 설정하는 것이 매우 중요하다(Lee, 2022).

2.5 부스팅(Boosting)
부스팅은 Tree 모델 등과 같은 단일 모델을 순차적으로 활용하여 가중치를 도출하고 모든 모델의 가중치가 결과 산출에 개입하는 기법이다. 모델을 순차적으로 학습하여 이전 모델의 오류를 보완함으로 모델의 전체적인 정확도는 높은 편이나, 데이터 이상치에 취약한 단점을 갖고 있다(Lee, 2022). 부스팅에는 Tree 모델을 기반으로 하는 XGBoost와 LightGBM 등과 같은 모델이 있으며, XGBoost는 모델의 속도가 뛰어나고 성능이 뛰어나 빅데이터의 적용이 용이하고(Ha, 2017), LightGBM은 모델의 오차가 적게 나타나지만 과적합의 위험이 크다는 특징을 갖고 있다(Lee, 2022).
3. 예측모델 데이터의 구성
3.1 연구 대상지역
본 연구는 남해안(부산, 목포, 광양)지역 점토를 채취하여 직접 현장시험(함수비, 액⋅소성한계, 압밀시험)을 실시한 결과 및 국토지반정보 포털시스템에서 획득한 지반정보 데이터를 활용하여 데이터셋을 구축하였다.
부산지역은 부산 전역에서 총 4,427개의 시추 데이터를 확보하였으며, 확보한 데이터 중 분석에 활용 가능한 데이터 562개를 추출하였다. 광양지역은 광양항을 중심으로 다수의 공구에서 총 3,401개의 시추데이터를 확보하였으며, 이 중 활용한 데이터는 609개의 데이터이다. 목포지역은 목포 신항 및 고속도로, 택지개발 사업에서 실시한 지반조사를 중심으로 총 2,201개의 데이터 중 활용가능 데이터는 339개이다. 따라서 데이터셋 구축에 사용된 데이터는 총 1,510개이다.
3.2 대상지역의 데이터 특성
3.2.1 통계적 특성
점토의 물리적 특성 값을 활용한 압축지수 예측모델의 개발을 위해 압축지수(Cc)에 영향을 미치는 특성으로는 선행연구를 참고하여 자연함수비(Wc), 액성한계(LL), 소성지수(PI), 초기 간극비(e0)를 선정하였으며(Farzin and Afshin, 2012), 토성은 고소성 무기질 점토(CH), 저소성 무기질 점토(CL)를 대상으로 하였으며, 채취 심도는 0.4~55.4 m이다.
Table 1은 대상지역의 지반 특성 값에 대한 범위를 나타낸 표이며, 광양지역의 함수비와 액성한계 및 소성지수, 초기간극비가 높게 나타나, 압축지수도 높은 경향을 나타낸 것으로 판단된다. 또한, Table 2는 종합적인 데이터의 평균 및, 표준 오차, 중앙값, 표준 편차 등을 나타낸 기술통계 표이다.
3.2.2 상관분석
영향인자와 압축지수 사이의 상관도 확인을 통해 영향인자의 유의미성에 대한 검토가 필요하다. 따라서 각 인자와 압축지수와의 상관분석을 통해 상관계수를 확인하고 Table 3에 나타냈으며, 인자에 따른 회귀식과 결정계수를 확인하고자 하였다. Table 3를 살펴보면 상관계수는 초기간극비가 0.751로 가장 높게 나타났고 소성지수가 0.628로 가장 작은 값을 나타냈으나, 가장 낮은 상관계수가 나타난 소성지수도 0.628로 압축지수에 영향을 미치는 것으로 판단되며, 유의확률은 모두 0.000으로 신뢰할 수 있는 것으로 나타났다.
Table 3
Result of Correlation Analysis
| Category | Correlation Coefficient | P-Value |
|---|---|---|
| Wc (%) | 0.740 | 0.000 |
| LL (%) | 0.642 | 0.000 |
| PI | 0.628 | 0.000 |
| e0 | 0.751 | 0.000 |
본 연구에서 선정된 영향인자와 압축지수와의 관계식을 제시한 실시한 연구는 과거부터 꾸준히 수행되고 있다. 하지만, 지반공학 특성 상 지역에 따른 관계식이 상이하기 때문에 대표적인 관계식으로 모든 지역의 지반 정수를 추측하긴 어려운 실정이다. 따라서 본 연구 대상지역의 영향인자와 압축지수 사이의 1차원 관계식과 결정계수와 인근 지역을 대상으로 연구를 수행된 기존 제안식을 비교하여 Table 4에 나타냈으며 압축지수와 영향인자 사이의 결정계수를 Fig. 3에 그래프로 나타내었다. 기존 제안식과 비교하면 본 연구에서 제시된 제안식의 결정계수가 상대적으로 낮은 것으로 나타난다. 이는 본 연구에서 선정한 대상지역의 범위가 광범위하여 나타난 현상으로 판단된다. 따라서 기계학습 알고리즘을 활용하여 압축지수 예측 모델을 개발하고자 한다.
Table 4
Comparison of Regression Equations between This Study and Previous Studies
| Category | Equation | R2 |
|---|---|---|
| Cc-Wc | Cc = 0.0146 (Wc-16.7) (Kim et al., 2001) | 0.93 |
| Cc = 0.013 (Wc-6.94) (This Paper) | 0.55 | |
| Cc-LL | Cc = 0.0134 (LL-9.65) (Kim et al., 2001) | 0.89 |
| Cc = 0.0112 (LL-0.018) (This Paper) | 0.41 | |
| Cc-PI | Cc = 0.018 + 0.092 PI (Kim et al., 2001) | 0.89 |
| Cc = 0.0136 (PI + 14.79) (This Paper) | 0.39 | |
| Cc-e0 | Cc = 0.587 (e0-0.586) (Kim et al., 2001) | 0.94 |
| Cc = 0.4832 (e0-0.225) (This Paper) | 0.56 |

4. 기계학습 알고리즘 적용 및 결과
4.1 기계학습 알고리즘 적용
본 연구에서는 Python과 Scikit-learn 라이브러리를 활용하여 RF, LR Ridge, Lasso, DNN, SVM, XGBoost, LightGBM 알고리즘에 데이터셋을 적용하여 성능이 우수한 압축지수 예측 모델을 선정하고자 하였다. 모델 평가에 사용된 지표는 RMSE와 R2이며, 과적합을 방지하기 위해 기계학습 모델에 5-Fold Cross Validation 알고리즘을 적용하였고 학습-검증 데이터 비율을 80:20으로 분할한 뒤 결과를 도출하였다.
기계학습 모델의 과적합을 방지하고 성능을 개선하기 위해서는 모델에 적절한 HyperParameter를 설정해야한다. 이러한 과정을 ‘튜닝(Tuning)’이라고 하며, 본 연구에서는 모델의 주요 HyperParameter를 시행착오법을 통하여 최적의 성능을 발휘하는 HyperParameter를 설정하였다. Table 5는 각 모델의 주요 HyperParameter와 설정된 변수 값을 나타낸 표이다.
Table 5
Summary of Hyper Parameters in the Model
DNN의 구조를 간략하게 설명하면 다음과 같다. 먼저, 3개의 Hidden Layer에 12개의 node와 activation은 ‘Relu’를 적용하였으며, Output Layer의 activation은 ‘linear’로 설정하였다. 또한, 최적화 기법은 ‘Adam’을 적용하여 결과를 도출하였다.
RF모델의 주요 Hyper parameter는 Tree의 수를 의미하는 estimators (10~500)와 Tree의 깊이를 의미하는 max depth (1~6)로 설정하였으며, XGBoost와 LightGBM도 estimators (10~500)와 max depth (1~6), 모델의 학습률을 의미하는 learning rate (0.001~0.1)을 주요 매개변수로 선정하여 시행착오법을 통해 최적의 결과를 도출하는 Hyper parameter로 Tuning하였다.
4.2 기계학습 적용 결과
최적의 Hyperparameter로 설정된 모델에 데이터셋을 적용하여 RMSE와 R2의 결과를 Table 6에 나타냈다. 부산지역의 경우 RMSE는 LR모델이 0.141로 가장 낮게 나타났으며 R2은 0.587로 나타났다. 광양지역의 경우 부산지역과 마찬가지로 LR모델이 가장 적절한 것으로 나타났으며, 타 지역과 비교하여 RMSE가 높은 경향이 나타났다. 이는 광범위한 지역에서 취득한 데이터가 다수 존재하여 나타난 결과로 판단된다. 목포지역의 경우 LightGBM 모델이 RMSE는 0.137, R2은 0.536으로 가장 우수한 성능을 나타냈으며, 타 지역과 비교하였을 때 RMSE가 낮게 나타났으나 R2의 값은 다소 감소한 것으로 나타났다. 이는 목포지역의 데이터 수가 상대적으로 적어 나타난 결과로 판단된다. 종합적인 전체지역에 대해 분석을 실시한 결과, LightGBM이 가장 적절한 모델로 판단되었으며, RMSE는 0.157, R2은 0609가 도출되었다. 또한, 전반적인 모델의 결과를 확인한 결과 단순한 구조의 DNN의 경우 예측 성능이 다소 낮은 것으로 나타났다.
Table 6
The Performances Obtained with Models
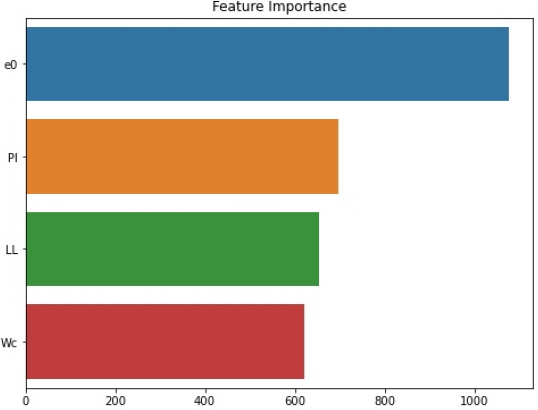
각각의 지역에 따른 모델 평가지표의 결과 비교를 통해 선정된 적절 모델은 Busan-LR (B-LR), Gwangyang-LR (G-LR), Mokpo-LightGBM (M-LGBM), Total-LightGBM (T-LGBM)로 선정되었으며, Fig. 4는 각 모델의 예측결과를 나타낸 그래프이다. Figs. 4(a), (c)는 실제 값과 예측 값 사이의 분산이 크게 나타났으며, Figs. 4(b), (d)는 상대적으로 예측이 잘 이루어진 것으로 나타났다. 또한, T-LGBM 모델을 통해 압축지수 예측에 활용된 영향인자의 중요도를 Fig. 5에 나타냈다. 중요도 도출 결과 e0, PI, LL, Wc의 순으로 중요도가 나타났으며, 초기간극비의 중요도가 가장 높게 도출된 결과는 상관분석의 결과와 동일하다.

종합적인 데이터에 대한 적절 모델(T-LGBM)의 상관계수와 상관분석 결과를 비교하였을 때, 단일 인자로 압축지수를 예측한 결과(R2 : 0.39~0.56)보다 종합적인 인자를 모두 활용하여 기계학습을 실시한 결과의 결정계수(R2 : 0.61)가 높게 나타났으며, 이를 통해 상대적으로 간단한 물성실험을 통해 도출된 결과 값을 이용하여 개략적인 압축지수를 예측할 수 있을 것으로 판단된다. 또한, 압축지수를 구하기 위한 압밀시험 시 해당 결과 값의 신뢰성에 대한 참고자료로 활용할 수 있을 것으로 기대된다. 추후 모델의 신뢰도를 향상시키기 위해서는 지역을 보다 세분화하여 양질의 데이터를 다수 확보한 뒤 모델에 학습하는 방법을 고려해야 한다.
5. 결 론
본 연구는 부산, 광양, 목포지역을 대상으로 현장 조사 및 실내 실험을 통해 취득한 Wn, LL, PI, e0, Cc 값을 활용하여 Cc를 예측하기 위한 데이터셋을 구축하고 기계학습 모델에 적용하여 그 결과를 비교하고 가장 우수한 모델을 선정하고자 하였다. 본 연구 결과를 요약하면 다음과 같다.
(1) 광양지역과 부산 및 목포지역의 지반정수를 비교한 결과, 광양지역의 자연함수비가 상대적으로 높은 경향을 나타냈으며, 이에 따라 압축지수가 타 지역에 비해 높게 나타났다.
(2) 압축지수와 지반정수 영향인자의 상관분석을 실시한 결과, 초기간극비(0.751), 자연함수비(0.740), 액성한계(0.642), 소성지수(0.628)의 순으로 높은 상관도가 나타났다.
(3) 기계학습 알고리즘에 데이터셋을 적용하여 우수한 모델을 선정한 결과, 부산지역과 광양지역은 Linear Regression, 목포지역과 종합한 지역은 LightGBM의 모델이 상대적으로 가장 낮은 RMSE (0.137~0.172)와 높은 상관계수(0.54~0.63)를 나타냈다.
(4) 단일 인자에 대한 상관분석 결과(R2 : 0.39~0.56)기계학습 모델의 결정계수(0.609)를 비교한 결과, 기계학습 예측 모델을 통해 압축지수를 예측한 결과가 우수한 것으로 나타났다.
본 연구에서 제안된 기계학습 기법을 활용한 압축지수 예측모델을 통해 상대적으로 단순한 지반정수 값으로 개략적인 압축지수를 예측할 수 있을 것으로 기대된다. 또한, 양질의 데이터를 다수 확보하고 역학적 특성 값 등을 추가하여 데이터셋을 구축한 뒤, 추가적인 학습을 수행하면, 보다 우수한 예측력과 높은 신뢰성을 발휘하는 모델이 개발 될 것으로 기대된다.




