


1. 서론
홍수는 전 세계적으로 인명과 재산에 가장 큰 영향을 주는 빈번한 자연재해이기 때문에 오래전부터 과학자들과 공학자들에게 관심의 대상이 되어 왔다. 이러한 관심은 인명 손실과 사회 기반시설의 비용적인 손실을 감소시키는데 도움이 되는 방어 대책과 피해 예측을 제공하도록 하는 기법을 개선하는데 집중하고 있다.
집중 호우로 인한 제내지 침수를 예측하는 것은 홍수의 발생을 예측해야 할 뿐만 아니라 홍수의 시간적 그리고 공간적분포를 포함한 복잡한 침수 형태의 예측을 요구하는 어려운 문제이기 때문에 홍수 침수 해석은 1차원 기법에 의해 주로 연구되었다. 1차원 모형들은 컴퓨터 연산 과정이 효율적이며 수문학적으로도 비교적 합리적 수면형상을 생산하였다. 그러나 1 차원 모형들에 의해 추정된 수면형상들은 2 차원 지도를 만들기 위해 디지털 수치 자료위에 중첩되어지거나 근사화되어져야 한다. 제방이나 둑, 도로 및 흐름 차단벽 등과 같이 지표면의 흐름을 제한하거나 유도하는 시설들로 인한 결과는 인위적인 보정이 없다면 1 차원 해석 결과는 적용성이 낮아질수밖에 없다. 특히 홍수터와 도시 지역의 침수와 같은 복잡한 흐름 진행 양상을 1 차원 모형에서는 분명하게 나타내는 것이 불가능할 수 있다.
2 차원 천수 방정식들을 기초로 하는 2 차원 모형들은 흐름의 속도와 방향을 나타내는데 1 차원 모형에 비해 우수한 능력을 가지고 있기 때문에 미 국립연구재단은 2 차원 모형을 홍수터 침수해석을 위해 사용되어져야 한다고 언급하였고(NRC, 2009) 2 차원 모형의 해석적 장점으로 인해 이 모형들이 침수해석 및 홍수 관련 연구를 위해 점점 더 널리 사용되어지고 있다(Beffa and Connel 2001, Bradford and Sanders 2002, Kim etc. 2014). 그러나 이런 2 차원 모형들이 양해적기법을 이용할 경우 막대한 연산 부하량으로 인해 연산 비용(processing cost)의 제약이 있다. 최근 들어 높은 고해상도의디지털 지형자료를 구축하여 내·외수 침수해석을 연구하고 있으며 GIS 와 LIDAR 와 같은 방법으로 지형자료 획득하여 넓은 범위의 영역의 연구 범위를 수행함으로써 연산 비용의 어려움은 훨씬 심화되고 있다(Neal etc. 2009).
2 차원 모형에서 연산 시간의 대부분은 격자점이나 요소에서의 수면 표고와 속도를 계산하는데 사용되기 때문에 동시적으로 여러 코어에서 연산이 수행될 수 있는 병렬기법은 연산시간 절약의 대안이 될 수 있다. 병렬연산 설계를 도입하여 개발된 초기 홍수 침수모형은 노드나 컴퓨터들이 서로 클러스터(cluster)로 구성된 전통적인 병렬 연산 구조를 이용하였다(Hervouet 2000, Rao 2005, Pau and Sanders 2006, Villanueva and Wright 2005). 이런 모형들은 메시지 전달 인터페이스(message passage interface, MPI) 체계를 이용하여 영역의 행이나 열을 기준으로 영역을 분할하여 클러스터에 부하량을 분산, 연산되어 방정식들의 동시적인 해석이 이루어지도록 하였다.
그러나 MPI를 이용하는 방법은 클러스터에서 실행하기 위해 기존의 원시 코드(code)를 병렬해석 코드로 변환하는 과정은 상당한 전문성을 요구하며 많은 시간을 요구한다. 또한 고성능 연산(high-performance computing, HPC) 클러스터들은 연구소나 정부기관에 소속되어 있어서 이러한 시스템들을 개인적인 연구자들이 이용하는 절차상의 불편함이 발생할 수 있다.
최근의 컴퓨터 발전 경향의 변화로 병렬 연산이 변화되어졌다. 주요 프로세서 생산자들은 CPU 성능을 증대시키기 위해clock speed를 올리는 것 대신에 하나의 데스크탑 컴퓨터에 연산장치의 병렬 구조를 제공하기 위해 하이퍼스레딩(hyperthreading)과 메모리를 프로세서들 사이에 공유하는 멀티코어(multi-core) 구조를 개발하는 것에 집중하였다(Sutter 2005). 멀티코어 컴퓨터들을 이용한 병렬 작업 (parallel threading)을 위한 방법은 Open Multiprocessing(OpenMP) 응용프로그램프로그래밍 인터페이스(API)이 대표적이다.
국내에서의 2 차원 범람 홍수파에 대한 연구는 주로 댐 및 제방붕괴를 중심으로 1 차원 해석이 수행되어 왔으며(Lee et al., 1995) 2 차원 침수해석으로는 Han and Park(2006)이 제방붕괴로 인한 제내지 침수해석을 수행하였다. 병렬 기법을 이용한 침수해석의 연구는 Kim et al. (2014)이 MPI 기법을 이용한 유한체적모형을 이용하여 댐 붕괴사상에 적용하여 실용성을 검증하였으며 Park (2014) 역시 MPI를 확산파 모형에 도입하여 국내의 하천에 적용하여 연산 성능의 개선을 시도하였다. 그러나 이러한 연구는 MPI를 이용하여 실제 사상에 적응코자 하는 초기적 연구이며 OpenMP를 이용하거나 병렬기법 간의 비교 등과 같이 병렬 연산을 이용한 본격적인 홍수병렬 침수해석은 미진한 실정이다.
본 연구에서는 데스크탑 컴퓨터에서의 병렬 연산 방법을 제시하고자 OpenMP 기법을 확산파 홍수모형에 도입하여 홍수침수 모의들의 연산시간을 감소하고자 한다. 또한 MPI, OpenMP 두 병렬 기법이 제내지 침수모형에 적용시 연산속도 증속 효과의 비교를 통해 병렬 기법의 상호간의 우수성을 비교하고자 한다. 이를 통해 현재의 일반적인 추세인 멀티코어개인용 컴퓨터들에서 모든 코어들을 동시적으로 연산에 이용하여 제내지 침수해석을 수행할 수 있고 이를 통해 보다 빠른시간에 정확한 홍수 해석이 가능하도록 하였다.
2. 병렬 확산파 해석 모형
댐 붕괴 흐름과 같이 완전 동역학적 방정식이 적용되어야하는 극한적인 일부 경우를 제외하면 비교적 넓고 편평한 지역에서의 홍수로 인한 침수는 확산파 방정식에 의해 모형화될 수 있는 흐름특성을 가진다(Chen et al., 2005). 확산파 해석은 완전 동역학 방정식의 관성력의 항을 무시함으로 단순화된 방정식이 유도되어 비교적 간략하게 해석되어 질 수 있다. 일반적인 경우, 단순화된 연립방정식의 사용은 빠른 계산시간으로 이어질 수 있으나 흐름 조건이 급격하게 변하고 계산요소의 수가 많은 고해상도의 지형조건의 경우 연산 안정조건(stability condition)으로 인해 효율적인 연산이 이루어지지 못한 경우가 발생할 수 있다(Hunter et al., 2008)
본 연구에서는 확산파 해석의 연산의 짧은 계산시간 단계를 사용하는 경우 오랜 연산 시간 단점을 개선하고 개인용 컴퓨터에서 비교적 쉽게 병렬 연산에 접근할 수 있도록 OpenMP 병렬 기법을 도입하였고 이를 가상 및 실제 유역에 적용하여 모형의 적용성을 입증코자 하였다.
2.1 2차원 확산파 모형
2 차원 천수방정식은 Eq. (1)~Eq. (3)과 같은 연속방정식과 운동량방정식으로 구성된다.
여기서, Sfx, Sfy는 x, y 방향에 대한 마찰경사, H는 수심, h는 수위, g는 중력가속도, qx, qy는 x, y에 대한 단위폭당 유량을 나타내고 있다. Eq. (1)~Eq. (3)에 대해 확산파 이론을 적용하여 근사화된 식은 Eq. (4)와 같다(Hromadka and Yen, 1987).
여기서 Fx와 Fy는 x, y 흐름방향에 따른 흐름 면적의 함수이다. Eq. (4)의 확산형 방정식을 해석하기 위해 Fig. 1에서와 같이 양해석법의 중앙차분법을 변형한 격자망 계산방법을 사용하며, 직사각형 격자로 구분하였고 각 격자에 대한 표고, 조도계수, 위치 등을 분포시켰다. 흐름해석은 유량을 계산하기 위하여 요소의 수심차이를 이용하여 각 방향을 유량을 계산하고 계산된 유량을 다시 격자의 수심 변동치로 환원하면 각 요소에서의 수심이 계산될 수 있다(Park, 2014).

개발된 확산파 해석 프로그램의 원시코드를 OpenMP 기법을 도입하여 병렬 프로그램으로 개선하였다. 개발된 병렬 침수모의 모형은 4 단계 주요 연산과정- 변수의 시간 단계별 초기화, 연산영역내의 요소에서의 흐름 변수 계산, 외부 유·출입량 고려, 연산 결과 출력-으로 구성되어졌다. Fig. 2는 병렬화된 확산파 침수해석 모형의 구성을 단계적으로 보여주고 있다. 언급된 4 단계의 각 과정은 매 시간 반복과정에서 발생하며 전체 연산시간의 대부분은 계산시간 단계 중 각 요소에서의 흐름 변수 즉 qx, qy, Δh를 계산하는데 소비되어진다. 또한 각 시간반복 단계 가운데 연산 영역내의 모든 요소들은 독립적으로 연산되어지기 때문에 확산파 모형은 멀티코어를 이용한 병렬 연산에 적합하였다.

기존의 순차적 해석모형을 멀티코어를 이용한 병렬 연산모형으로 변환하는 과정은 다음과 같이 3 부분으로 구성되어질 수 있다.
위의 3 단계는 시간 단계별 각 반복과정에서 반복되어진다.
Fig. 2에서 음영으로 나타난 부분이 병렬화가 도입된 부분이다. 언급된 병렬화의 3 단계 중 스fp드의 생성과 소멸로 인해 초과적인 과부하가 발생할 수 있기 때문에 연산과정 가운데 대부분의 시간을 소모하는 흐름변수의 연산과정에서만 병렬화를 도입하였다.
각 시간 단계에서 하나의 스레드에 의해 순차적 연산이 수행되다가 동시적 연산이 도입되는 병렬 부분을 만나면 병렬 스레드들이 생성되어진다. 생성된 스레드에서 흐름 변수의 연산을 위해 연산 영역의 일부가 각 스레드에 할당되어지며 각 스레드에서 흐름 변수 qx, qy, Δh는 각자 할당된 영역에서 동시적으로 연산되어진다. 각 스레드들이 할당된 소 연산구역의 흐름 변수 연산을 완료하였을 때 각 스레드들은 소멸되고 순차적인 상태로 다시 돌아가게 되고 다음 병렬 연산단계을 위 해 대기하게 되고 병렬 구간을 만나면 다시 생성되어 진다.
3. 병렬 확산파 해석모형의 가상하도 적용
기존의 순차적 프로그램들은 하나의 코어만을 이용하도록 프로그램 되었기 때문에 멀티코어의 동시적인 실행이 되지 못한다. 프로그램이 CPU 내의 모든 코어들을 사용하여 동시적으로 빠르게 실행되기 위해서 기존의 원시 코드를 병렬프로그램으로 변환하여야 한다.
본 연구에서도 기존의 순차적인 제내지 해석 프로그램인 확산파 해석모형 코드를 OpenMP병렬 해석 기법을 이용하여 병렬화 코드로 재작성하여 가상하도에 적용하였다. 병렬 기법으로써 OpenMP 기법의 제내지 침수해석 적용성을 파악하고자 분산 메모리 병렬기법인 MPI 병렬 해석 결과와 비교하고자 하였다.
3.1 병렬해석
여러 대의 컴퓨터를 이용하여 클러스터를 구축하고 높은 성능을 낼 수 있는 병렬적 하드웨어 환경을 구축하였다 하더라도 소프트웨어에서도 역시 병렬화를 도입하지 않으면 기대하는 성능을 얻을 수 없다. 이러한 병렬화를 위해서 크게 MPI, OpenMP 두 종류의 병렬 프로그래밍 기법이 현재 많이 이용되고 있다. MPI는 분산 메모리 시스템을 목적으로 하였고, OpenMP는 공유 메모리 시스템을 목적으로 하여 개발된 병렬 프로그래밍 모델이다.
MPI(Message Passing Interface)는 언어 독립적인 통신 프로토콜을 사용하는 병렬 프로그래밍 라이브러리이다. MPI를 사용하는 시스템은 일반적으로 분산 메모리 시스템(distributed memory system)을 사용한다(Fig. 3). MPI는 각 노드(Node)끼리 점대점 또는 집합 통신을 사용하여 정보를 교환하여 각노드에서 자신에게 할당된 프로세스를 처리하여 병렬 컴퓨팅환경을 구현한다. 현재 MPI는 Fortran, C, C++ 언어에 맞게 만들어진 MPI 서브루틴들을 이용하여 병렬 프로그래밍을 적용할 수 있도록 되어있다.

MPI가 가지는 장점은 분산메모리 시스템 즉, 클러스터에서 사용이 가능하다. 그러므로 클러스터의 내부에 노드(일반적으로 계산을 위해 사용되는 PC)를 추가함으로써 슈퍼컴퓨터 와같은 대형 컴퓨터 시스템에 비해 손쉽게 성능을 향상시킬 수 있다.
그러나 MPI는 분산 메모리 시스템을 사용하기 때문에 어떠한 한 노드에서 사용된 데이터가 다른 노드에서 요구된다면, 실제 클러스터에서는 다른 노드에서 사용하기 위해 요구된 데이터의 공간만큼 실제로 데이터가 중복될 수 있다. 또한 이 데이터를 주고받는 과정은 통신프로토콜을 이용하여 통신을 해야 한다. 이렇게 통신을 통하여 데이터를 교환할 경우 공유메모리 시스템을 위한 표준 프로그래밍 방식인 OpenMP에 비해서 상대적으로 큰 시간적 비용을 소비해야한다.
OpenMP는 공유메모리(shared-memory) 환경에서 프로그램을 병렬화하는 기술표준으로(Fig. 4) 컴파일러 지시자(directives), 런타임 루틴, 프로그래머가 사용할 수 있는 환경 변수 등을 제공한다. OpenMP는 현재 많은 컴파일러에서 기본적으로 제공되고 있으므로 MPI처럼 MPI를 사용하기 위해서 기본적인 환경을 설치하고 설정하는 과정을 거치지 않아도 된다. OpenMP는 사용자가 소스 코드 안에 삽입한 컴파일러 지시자(directives)를 이용하여 실행파일이 병렬 실행이 가능한 파일로 생성해준다. 또한 OpenMP는 직접 스레드를 생성하고, 관리하여 병렬프로그래밍을 더 쉽게할 수 있도록 도와준다. 또한 공유 메모리 환경에서 실행되어 서로 데이터를 교환하는 과정을 통하여 데이터 동기화를 시킬 필요가 없다. MPI에 비해 요구되는 메모리의 양이 더 적다는 점과, MPI처럼 네트워크 통신을 이용하여 데이터 교환을 하지 않으므로 병렬화 구간에 따른 오버헤드가 작다는 점이 큰 장점이 될 수 있다.

3.2 가상하도에의 적용
OpenMP 기법을 적용한 병렬 모형의 홍수 침수해석 적용성을 검토하고자 가상의 제내지를 격자망으로 구성하였으며, 계산시간 개선 효과를 입증하기 위하여 단일-코어와 멀티코어를 사용하여 MPI 병렬 기법 모형과 결과를 검토하였다. 사용된 컴퓨터는 HP Z620 workstation 기종으로 Intel Xeon 2.60GHz CPU 2 개, 내장된 전체 코어의 수는 12 개다. 설치된 메모리는 32 GB이고 MPI, OpenMP 및 포트란 컴파일러는Intel Parallel Studio 12 판에서 제공되는 프로그램들을 이용하였다. MPI 기법은 Master-Slaver 기법을 이용하였으며 본 연구모형과의 비교를 위해 같은 환경에서 적용되었다(Park, 2014).
격자망의 구성은 50×50 m 정방형 요소 450, 1500, 3000,4500 개로 이루어진 2 차원 제내지 구간을 고려하였다. 붕괴지점은 요소 45 지점에서 제방붕괴가 발생되어 제내지로 붕괴유량이 유입되도록 가정하였으며, 유입량은 최대15,000 m3/sec 적용하였다. 요소 4500 개의 대한 계산 시간 10.0 hr 에서의 순차적 해석 및 4 코어 OpenMP, MPI 를 이용한 계산결과를 침수심도, 유속 벡터도를 통하여 나타내었으며 Fig. 5~Fig. 7과 같다.
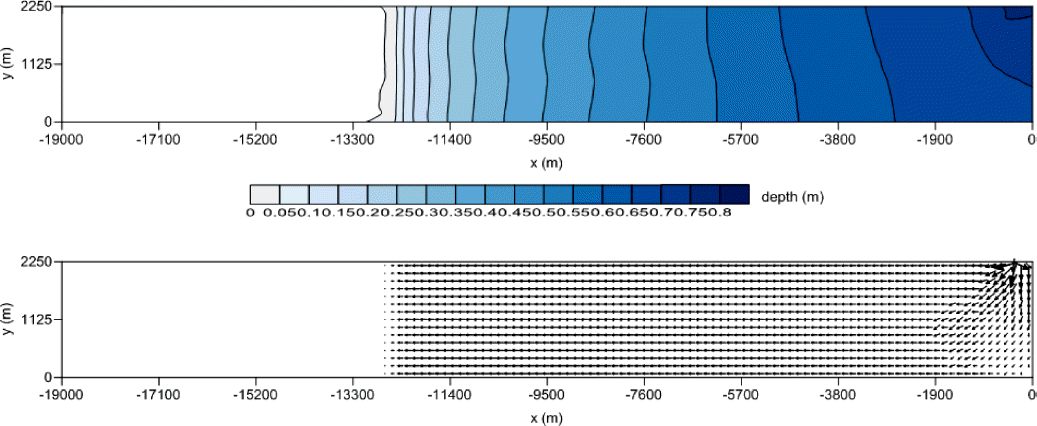


계산결과 코어 하나만을 사용한 순차적 기법과 코어 4 개를 사용한 MPI 모형, 본 OpenMP 모형의 결과가 동일하여 병렬기법 도입으로 인한 병렬화 프로그램 작성오류는 없는 것으로 판단된다.
OpenMP 병렬 모형의 침수해석 연산 특성 및 병렬 효과를 파악하기 위해 적용된 가상하도 결과를 순차적 해석 및 MPI기법과 상호 비교하여 검토하였다. 가상유역 4 가지 경우에 대해 1~4 코어에서 소모된 연산 시간이 Table 1과 Fig. 8에서 그래프로 나타내어졌다. 연산시간은 순차적 해석 결과에 비해MPI, OpenMP 병렬 모형 모두 코어의 수가 증가할수록 감소하였다. 특히 4500 개 요소의 경우 연산시간 감소폭이 커 요소의 수가 증가할수록 병렬 효과가 뚜렷이 나타남을 알 수 있었다.
Table 1
Elapsed Computing Time(sec) of Applied Models

MPI와 OpenMP의 비교는 대체로 OpenMP 기법이 MPI 보다 좀 더 우수한 결과를 나타내었고 특히 요소 4500 개의 적용에서 OpenMP 기법은 연산시간이 32.5 초 감소하였으나MPI 기법은 25.27 초 감소하였다.
MPI 기법은 2 코어 결과가 충분한 병렬효과를 나타내지 못한 경우가 있었고 이는 프로그램 구성상 코어 하나는 Master역할을 수행하고 코어 2,3,4만 연산을 실행하는 slave 역할을 하는 구조로 프로그램이 구성되어 2 코어 연산에서는 우수한 결과를 나타내지 못한 것으로 판단된다.
Fig. 9에서는 요소 450, 4500 개에 대해 연산 속도의 개선정도를 연산속도 상승효과(speed-up)로 분석하였다. 연산속도상승효과는 순차적 프로그램의 연산속도에 대한 병렬 프로그램의 연산속도비로 정의될 수 있고 n 개 코어에 대한 상승비는 Su(n)=T1/Tn으로 나타날 수 있다. 여기서 T1는 코어 하나를 이용한 순차적 해석의 연산소모 시간이고 Tn은 n 개의 코어를이용한 병렬 프로그램의 연산 소모시간이다. Fig. 9에서 보는 바와 같이 OpenMP, MPI 기법 모두 코어가 많을수록 요소의수가 작을수록 속도 상승효과는 크게 나타났으며 이는 코어에 할당된 작업량에 따라 연산속도가 결정된 당연한 결과라고 판단된다.
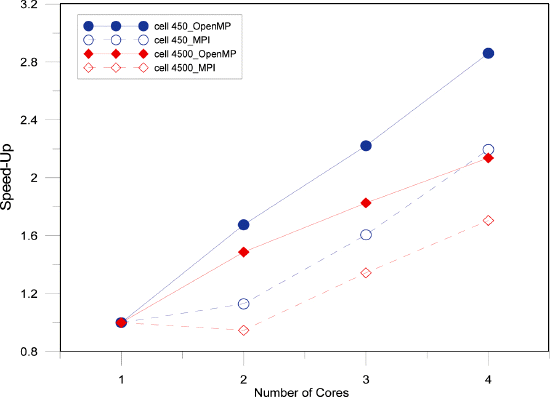
동일한 수의 요소에 대해서 OpenMP의 결과가 MPI 결과보다 좀 더 우수한 연산속도 상승 효과를 나타내어 자료 전송효과로 인한 과부하(overhead)가 좀 더 크게 발생하는 MPI에서 속도 상승효과가 작게 나타나는 것으로 판단된다.
Fig. 10은 코어 하나에 대한 연산 효율성을 나타내었다. 연산 효율성은 연산 속도 상승비를 연산에 참가한 코어의 수로 나눈 값으로 코어 하나가 얼마나 연산에 효율적으로 이용되었는지에 대한 지표값이다. Fig. 10에서 보여지듯이 코어가 증가할수록 요소의 개수가 많아질수록 코어 하나에 대한 연산효율은 감소하고 있다. 이것은 코어가 많고 요소의 수가 많을수록 물리적 동기화를 위한 대기시간 즉 모든 코어들이 동시에 같은 모의 시간의 연산을 마치기 위한 대기시간과 자료의 전송 시간이 순수 연산시간에 비해 상대적으로 크게 작용하여 연산효율이 감소하고 있는 것으로 판단된다.
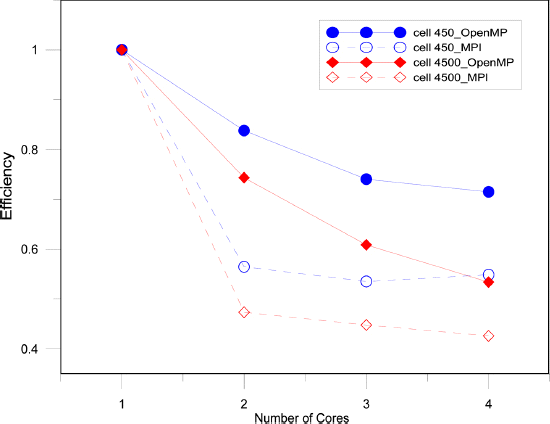
MPI와 OpenMP의 효율성의 비교는 물리적으로 전송시간이 오래 걸리는 MPI에서 효율성이 낮게 나타나고 있다. 본 연구에서 나타난 두 기법간의 효율성 비교를 통해 OpenMP 기법이 MPI 기법에 비해 좀 더 우수한 성능을 나타내는 본 연구의 결과는 기존의 연구에서 OpenMP가 좀 더 빠른 해석 결과를 나타내는 결과와 유사한 양상을 나타낸다고 할 수 있다(Chandra et al., 2014).
4. 실제 제내지 침수에 대한 개발 모형의 적용
본 연구에서 개발한 연구모형을 프랑스 Malpasset 댐에 적용하였다. 이 댐은 하류 Reyran 강 유역의 주기적인 홍수로 인한 침수 방지와 생활용수와 농업용수의 공급을 목적으로1954 년에 완공된 아치형 콘크리트 댐이었다. 그러나 이 댐은1959 년 10 월 2 일 집중적인 강우와 제방 우편에서의 누수 등으로 인해 갑자기 붕괴되어 수백명의 사상자를 발생하였다. Mapasset 댐 붕괴로 인한 홍수는 사고 이후 조사된 막대한 자료와 하류의 넓은 지역에 대해 측량된 2 차원 지형 자료 등으로 댐 붕괴 침수해석의 모형 검증을 위한 일반적이고 유용한 자료로 이용되고 있다. 본 모형에서는 이 사례를 적용하여 병렬화의 효과를 검증하고자 하였고 많은 요소를 가진 유역에 적용하고자 의도하여 11252, 45254 개의 정방형 격자를 연산영역으로 구성하였다. 홍수 추적 대상 유역의 길이는 약 14km, 격자 한 변의 길이는 각각 61, 30 m이다(Fig. 11).

지형 자료 및 조도계수 n 값은 CADAM(Garcia, 2009) 및 Hervouet(2000)의 연구에서 조사된 지형자료와 추천된 값은 사용하였으며 이용된 컴퓨터와 소프트웨어는 가상 유역에 적용된 사양과 같다. 요소의 수를 다르게 하여 작업량에 따른 OpenMP 의 적용성과 연산속도 상승효과를 순차적 프로그램과의 비교를 통해 검토하였다.
모형의 적용을 위해 요소 11352(case 1) 및 45254 개(case 2)로 구성된 계산격자에서 조도계수 n은 계산 영역의 모든 요소에서 0.033, 상류단 유입유량은 댐 붕괴유량으로 프랑스 국립 수리환경 연구소에서 수행된 값을 참고하여 추정하였고 하류단은 해안임을 감안하여 원래의 기존의 모형을 수정하여 고정단 수위로 경계조건을 도입할 수 있도록 수정하여 모의하였다. 계산된 결과를 등수심선도와 유속 벡터도로 계산 시간 0.1, 0.6에서 나타내었다(Fig. 12, 13) Fig. 12, 13에서 나타난 결과는 12 코어를 사용하여 계산된 결과로서 코어 개수에 따른 계산결과 결과값들에 오차는 발생하지 아니하였다. Fig 12, 13에서 보여지는 바와 같이 댐 붕괴로 인해 비교적 단시간에 홍수파에 하류로 전파되고 있으며 댐 붕괴 지점 직하류에서의 유속 및 수심의 크기는 매우 큰 값을 나타내고 있는 것으로 파악된다. 붕괴후 홍수 유출 시간이 지남에 따라 홍수파의 전파 범위가 넓어지고 유속 벡터 또한 홍수파의 전파 범위가 확대됨에 따라 유속이 작아져 선단부에서 벡터크기 또한 작아짐을 알 수 있어 홍수파의 전파 양상을 잘 나타내고 있다고 판단되었다.

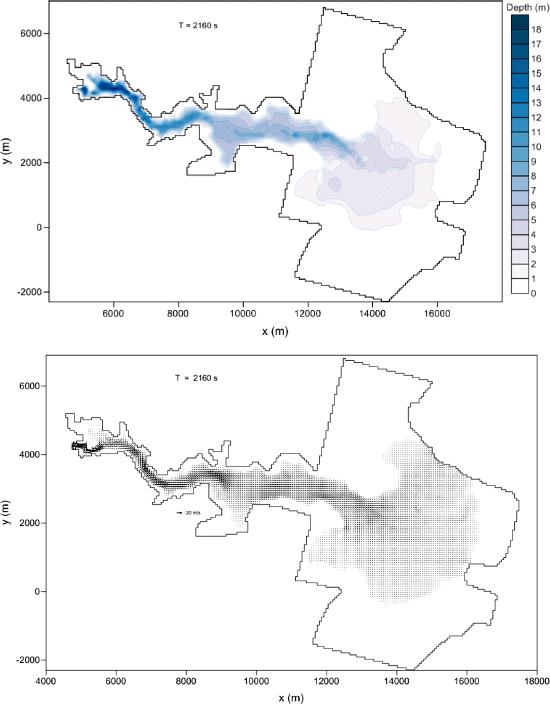
Table 2는 본 연구에서 적용된 두 사례에 대한 최대수심 결과값을 실측치 및 기존의 연구와 비교하였다. 실측값들은 프랑스 전력청 산하 국립 수리환경 연구소에서 Malpasset 댐 붕괴 사고를 댐 사고시 제방 양안의 최대 수심 흔적치를 바탕으로 1/400 모의 실험한 결과로써 각 측정 장소들은 Fig. 11에 나타나 있다. 실측치 및 기존의 연구결과들과 합리적인 수심범위 내에서 최대 수심을 잘 모의하고 있어 본 연구 결과의타당성이 있음을 판단하였다.
Table 2
Comparison of Maximum Water Level with Other Study Results Maximum water levels (m)
Fig. 14는 실측치와 본 연구 결과를 거리에 따른 수심 그래프로 나타내었다. Fig. 15에서 나타난 바와 같이 요소의 수가 적은 경우(case 1) 요소의 수가 많은 경우(case 2)보다 수면경사가 급격하게 변화하는 상류유역에서는 실제 수심보다 크게 나타났고 경사가 완만한 하류 유역에서는 최대 수심이 약간 작게 나타났다. 이것은 실제 댐 직하류의 급격하게 변화하는 하천의 실제적인 경사를 완만하게 수심을 추적하고 있다. 이것은 요소의 수가 많은 두 번째의 적용 경우(case 2)보다 요소의 평균 면적이 넓기 때문에 면적 평균수심을 해석하여 추적 유역 전체의 수심을 평균적으로 해석하는 결과로 파악된다. 그러나 두 경우 모두 전체 유역에 걸쳐 실제 수심 변화양상을 합리적으로 추적하고 있어 실제 적용에 있어서 큰 문제는 발생되지 않을 것으로 기대된다.
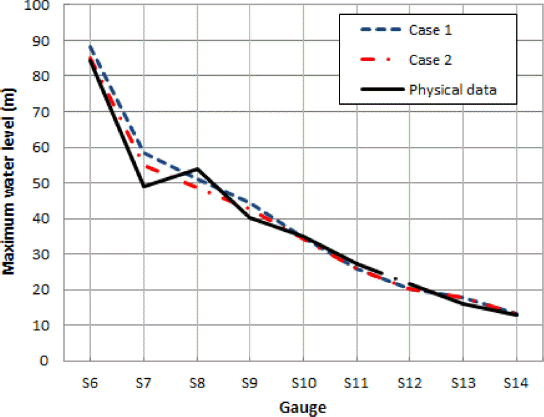

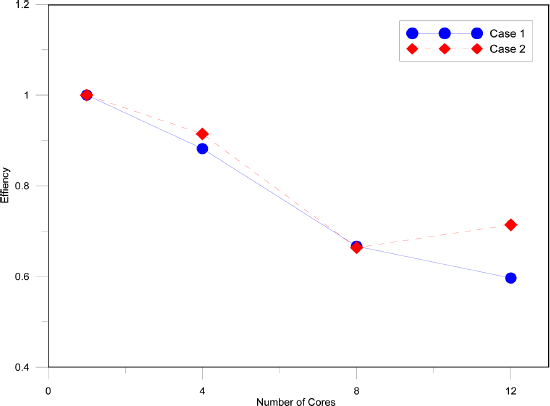
Fig. 15과 Table 3은 적용된 두 경우에 대해 사용된 코어별로 소요된 연산시간을 나타내었다. 사례 1, 2(case1,2)의 적용에서 OpenMP을 사용한 본 연구 모형의 연산 시간이 12 코어를 이용할 경우 연산시간이 0.12~0.14배 까지 감소하는 것으로 나타났다. 연산속도 상승효과는 12 코어 사용시 7.16, 8.57배 상승하여 본 모형의 병렬 효과를 확인할 수 있었다. 요소의 수에 관해서는 사례 1 보다 4 배 정도 많은 사례 2에서 연산 시간이 약 10.6~8.87 배 정도로 오래 걸렸다. 요소의 수가 증가할수록 연산시간이 기하급수적으로 증가하는 것은 필연적인 일이다. 연산속도 상승효과는 두 경우 모두 코어의 수가 증가할수록 효과가 큰 것으로 나타났으며(Fig. 16) 적용 사례1에서는 12 코어에서 7.16 배, 사례 2에서는 8.57 배로 나타나 요소의 수가 많을수록 증속효과는 큰 것으로 나타났다. MPI병렬에서는 4 개 이상의 코어가 사용될 경우 증속의 효과가 나타나지 않고 감소되는 경우가 있었으나 본 연구에서 사용된 OpenMP 기법에서는 나타나지 않았다(Kim et al., 2015).분포형 기억 방식을 사용하는 MPI 의 경우 일정량의 자료 전송량이 넘어가면 멀티코어의 병렬 연산시간보다 자료 전송시간에 따라 전체 연산 시간이 결정되는 경우가 발생하는데 OpenMP 는 공유 기억 방식을 사용하기 때문에 자료전송을 위한 물리적 시간이 MPI 만큼 필요치 않아 12 코어에서도 증속 효과가 나타나는 것으로 판단된다. 각 코어당 연산효율성은 사례 1, 2에서 12 코어인 경우 0.60, 0.71로 나타났으며 효율성 역시 요소의 수가 많을수록 우수한 것으로 나타났다. 이는 하나의 코어가 연산할 작업량이 많으면 많을수록 코어의 연산 시간에 따른 전체 연산시간이 결정되어지며 그에 따라 자료 전송에 따른 여분의 부하는 효과는 상대적으로 감소되는 것으로 판단되어진다. 그러나 전체적인 연산 성능은 Fig. 15에서 나타난 바와 같이 코어 숫자의 증가로 인해 코어당 연산 효율성 감소를 극복하고 연산 속도는 증가되어 연산 시간의 감소를 이룰 수 있었다.
Table 3
Elapsed time, Speed-Up and Efficiency of Malpasset Dam Application

5. 결론
본 연구에서는 확산파 해석 알고리듬을 데스크탑 컴퓨터의 병렬 연산 구조와 결합하여 홍수로 인한 하류 유역 침수해석시 컴퓨터 연산시간 감소를 이루고자 하였다. 이를 위해 확산파 침수 모형과 OpenMP 기법을 결합하여 프로그램을 병렬화 하였고 개발된 모형을 가상하도 및 실제 댐 붕괴 사상에 적용하여 순차적 해석 및 MPI 병렬 기법과의 연산 결과를 비교 하였다. 비교결과 개발된 모형의 적용성 및 효율성을 확인하였으며 연구를 통해 얻어진 주요결과는 다음과 같다. 개인용 컴퓨터를 이용한 확산파 해석 프로그램의 병렬화를 위해 확산파 모형을 검토하였고 이를 최대 효율을 나타낼 수 있는 병렬화된 프로그램을 작성하기 위해 병렬화가 필요한 영역과 변수들을 구분하여 OpenMP 기법과 결합하여 병렬화를 수행하였다.
병렬화된 확산파 모형의 성능향상 정도를 파악하기 위해 450, 1500, 3000, 4500 개의 요소를 가진 가상하도에 적용하여 그 결과를 순차적 모형, MPI 모형과 연산시간, 연산 속도상승효과, 효율 등과 비교하였다. 모형의 계산결과는 순차적 모형 및 MPI 모형과 침수양상, 속도 벡터 방향 및 크기 등이 일치하였고 이를 통해 결과에 대한 정확성을 확인하였다. 또한 MPI 모형과의 연산 속도, 연산 시간, 연산 효율성 등의 비교시 OpenMP를 이용한 본 모형이 공유 메모리를 사용하는 영향으로 보다 우수한 결과를 나타내고 있었다.
대규모 입력자료를 이용한 병렬 모형의 연산속도 장점을 파악하기 위해 실제 댐 붕괴 사례에 11252, 45254 개의 요소를 가진 격자망을 구성하여 본 모형을 적용하였다. 적용된 코어의 수는 1, 4, 8, 12 개를 적용하여 많은 코어 이용에 따른 연산 시간의 특성을 파악하고자 하였다. 적용결과 두 사례 모두코어의 수가 증가할수록 연산 시간은 감소하고 있었고 MPI에서 나타나는 코어의 수가 증가함에 따라 통신 부하가 증가하여 연산시간이 도리어 증가하는 현상은 나타나지 않았다. 요소의 수에 따라서는 요소의 수가 많을수록 연산 효율 및 연산 속도 상승효과가 크게 나타났으며 이를 통해 대규모 자료를 이용한 침수 해석의 경우 병렬 기법의 적용성을 확인할 수 있었다.
OpenMP 기법을 이용한 본 연구 모형의 가상 유역 및 실제댐 붕괴 사례에 적용한 결과 2 차원 홍수 침수모형의 경우 많은 연산 시간이 요구되는 유역에서의 침수해석은 병렬 해석이 보다 합리적인 연산시간으로 해석 결과를 도출할 수 있음을 알 수 있었고 Monte-Carlo 및 Ensemble 해석과 같은 많은 반복 해석을 통한 종합적 결과의 도출이 필요한 분야에서는 병렬 해석기법의 적용이 큰 도움이 될 수 있으리라 기대되었다.




