1. м„ң лЎ
кё°нӣ„ліҖнҷ”лЎң мқён•ҙ м§Җкө¬мқҳ нҸүк· кё°мҳЁмқҙ м§ҖмҶҚм ҒмңјлЎң мҰқк°Җн•ҳкі мһҲмңјл©°, мқҙлЎң мқён•ң мқҙмғҒкё°нӣ„ нҳ„мғҒмқҙ л№ҲлІҲн•ҳкІҢ л°ңмғқн•Ём—җ л”°лқј кё°нӣ„ кҙҖл Ё мһ¬н•ҙлҸ„ мҰқк°Җн•ҳкі мһҲлӢӨ. нҠ№нһҲ, нҷҚмҲҳлЎң мқён•ң мһ¬н•ҙк°Җ к°ҖмһҘ л§Һмқҙ л°ңмғқн•ҳкі мһҲмңјл©°, н”јн•ҙк·ңлӘЁлҸ„ к°ҖмһҘ нҒ¬кІҢ лӮҳнғҖлӮ¬лӢӨ. 2018л…„м—җлҸ„ мһҗм—°мһ¬н•ҙ 315кұҙ мӨ‘ нҷҚмҲҳк°Җ 127кұҙ, нғңн’Қ 95кұҙмңјлЎң мһҗм—°мһ¬н•ҙмқҳ м•Ҫ 70%лҘј м°Ём§Җн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ(CRED, 2019).
мҡ°лҰ¬лӮҳлқјм—җм„ңлҸ„ 2008л…„вҲј2017л…„к№Ңм§Җ 10л…„к°„ мЈјмҡ” мһҗм—°мһ¬лӮң н”јн•ҙм•Ўмқ„ мӮҙнҺҙліҙл©ҙ нғңн’Қкіј нҳёмҡ°лЎң мқён•ң н”јн•ҙм•Ўмқҙ м „мІҙ н”јн•ҙм•Ўмқҳ 88.4%лҘј м°Ём§Җн• л§ҢнҒј нғңн’Қкіј нҳёмҡ°лҠ” л§ҺмқҖ н”јн•ҙлҘј лҜём№ҳлҠ” мһҗм—°мһ¬лӮңмқҙлӢӨ(MOIS, 2018). мЈјмҡ”н”јн•ҙмӮ¬лЎҖлЎңлҠ” 2010л…„ 9мӣ” 21мқј м„ңмҡё л°Ҹ мқёмІңм§Җм—ӯ 집мӨ‘нҳёмҡ°лЎң мқён•ң м№ЁмҲҳ, 2011л…„ м„ңмҡё к°•лӮЁм—ӯ, мӮ¬лӢ№м—ӯ м№ЁмҲҳмҷҖ мҡ°л©ҙмӮ° мӮ°мӮ¬нғң, 2012л…„ к°•лӮЁм—ӯ мқјлҢҖ м№ЁмҲҳ, 2014л…„ л¶ҖмӮ° мҳЁмІңмІң мқјлҢҖ м№ЁмҲҳ, 2016л…„ нғңн’Қ вҖңм°Ёл°”(Chaba)вҖқ лӮҙмҠөмңјлЎң мқён•ң мҡёмӮ°м§Җм—ӯ м№ЁмҲҳ, 2017л…„ мһҘл§Ҳкё°к°„ 집мӨ‘нҳёмҡ°лЎң мқён•ң мқёмІң л°Ҹ л¶ҖмӮ° м№ЁмҲҳн”јн•ҙ л“ұмқҙ мһҲлӢӨ. мқҙмҷҖ к°ҷмқҙ лҢҖлҸ„мӢңк¶Ңм—җм„ң м№ЁмҲҳлЎң мқён•ң н”јн•ҙк°Җ нҒ° мӣҗмқёмңјлЎңлҠ” мҡ°лҰ¬ лӮҳлқјмқҳ лҢҖлҸ„мӢңлҠ” мЈјкұ° л°Ҹ мғҒк°Җмқҳ л°Җ집лҸ„мҷҖ л¶ҲнҲ¬мҲҳмңЁмқҙ лҶ’кі мң м—ӯкІҪмӮ¬к°Җ кёүн•ң м§Җнҳ•вӢ…нҷҳкІҪм Ғмқё нҠ№м§•мңјлЎң мқён•ҙ 집мӨ‘нҳёмҡ° л°ңмғқ мӢң л§Өмҡ° 짧мқҖ мӢңк°„м—җ м№ЁмҲҳк°Җ л°ңмғқн•ҳм—¬ лҢҖмқ‘н• мӢңк°„мқҙ л¶ҖмЎұн•ҳл©°, м°Ёлҹү л°Ҹ мқёкө¬к°Җ 집мӨ‘лҗҳм–ҙ мһҲм–ҙ к·ё н”јн•ҙк°Җ нҒ¬кІҢ л°ңмғқн•ҳкё° л•Ңл¬ёмқҙлӢӨ.
лҸ„мӢ¬м§Җм—җм„ң к·№н•ңк°•мҡ°лЎң мқён•ң м№ЁмҲҳн”јн•ҙ м Җк°җлҢҖмұ…мңјлЎң л°°мҲҳнҺҢн”„мһҘ м„Өм№ҳ, мҡ°мҲҳкҙҖ л°°мҲҳмҡ©лҹү нҷ•ліҙ л“ұмқҳ кө¬мЎ°м Ғмқё лҢҖмұ…мңјлЎңлҠ” н•ңкі„к°Җ мһҲмңјл©°, мӮ¬м „мҳҲліҙ л°Ҹ лҢҖн”ј л“ұ 비кө¬мЎ°м Ғмқё лҢҖмұ…мқҙ н•Ёк»ҳ мқҙлЈЁм–ҙм ём•ј н•ңлӢӨ. к·ёлҹ¬лӮҳ мҡ°лҰ¬лӮҳлқјмқҳ лҸ„мӢңм№ЁмҲҳ м Җк°җлҢҖмұ…мқҖ кө¬мЎ°м Ғ к°ңм„ л°©лІ•мқ„ мӨ‘мӢ¬мңјлЎң мқҙлЈЁм–ҙм§Җкі мһҲмңјл©°, 비кө¬мЎ°м Ғмқё лҢҖмұ…мңјлЎңлҠ” н•ҳмІңм—җм„ң мҲҳмң„кі„мёЎмһҗлЈҢлҘј нҷңмҡ©н•ң нҷҚмҲҳ мҳҲвӢ…кІҪліҙл§Ң мқҙлЈЁм–ҙм§Җкі мһҲлӢӨ.
вҖҳм§Җм—ӯлі„ мЈјмҡ” мһ¬лӮңлҢҖмқ‘ мӢңлӮҳлҰ¬мҳӨ л°Ҹ кё°мӨҖ к°ңл°ңвҖҷ м—°кө¬лҘј нҶөн•ҙ м„ңмҡё к°•лӮЁкө¬, м„ңмҙҲкө¬, кҙҖм•…кө¬, м–‘мІңкө¬, к°•м„ңкө¬м—җ лҢҖн•ң н”јн•ҙмқҙл Ҙкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мӮ°м •мӢқмқ„ к°ңл°ңн•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мҳҲвӢ…кІҪліҙлҘј мң„н•ң кё°мӨҖмқ„ м ңмӢңн•ҳмҳҖмңјл©°, вҖҳм§Җм—ӯлі„ лҸ„мӢңм№ЁмҲҳ лҢҖмқ‘мІҙкі„ кё°л°ҳ кө¬м¶•вҖҷм—°кө¬м—җм„ңлҠ” кіөк°„м Ғ лӢЁмң„лҘј 세분нҷ” н•ҳм—¬ н–үм •лҸҷ, л°°мҲҳ분кө¬ лӢЁмң„мқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ м ңмӢңн•ҳмҳҖлӢӨ. лҳҗн•ң н”јн•ҙмқҙл Ҙмқҙ м—ҶлҠ” м§Җм—ӯм—җ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳкё° мң„н•ң Neuro-Fuzzy лӘЁлҚёмқ„ нҷңмҡ©н•ң мң м—ӯнҠ№м„ұкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м •л°©лІ•мқ„ м ңмӢңн•ҳкі м¶”м • кІ°кіјмқҳ мӢңлІ” м Ғмҡ©мқ„ нҶөн•ҙ м Ғмҡ©м„ұмқ„ нҷ•мқён•ҳмҳҖлӢӨ(NDMI, 2014, 2015, 2016, 2017).
Cho et al. (2018) м—°кө¬м—җм„ңлҠ” мҙҲкё° лӘЁлҚё м„Өкі„кіјм •мңјлЎң мҙҲкё°нҷ” н•ЁмҲҳлҘј к°ңл°ңмһҗмқҳ нҢҗлӢЁмқҙ м•Ңкі лҰ¬мҰҳмқҳ кө¬мЎ° кІ°м •м—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ” Grid PartitionмңјлЎң н•ҳмҳҖмңјл©°, м„ңмҡё 25к°ң, мҡёмӮ° 2к°ң мқҚл©ҙлҸҷ, мҙқ 27к°ңмқҳ н•ҷмҠөмһҗлЈҢлҘј мӮ¬мҡ©н•ҳм—¬ лӘЁлҚёмқ„ м„Өкі„н•ҳмҳҖлӢӨ. н•ҷмҠөмһҗлЈҢлҠ” мў…мҶҚліҖмҲҳмқё н”јн•ҙмқҙл Ҙкё°л°ҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мӮ°м • кІ°кіјмҷҖ лҸ…лҰҪліҖмҲҳмқё лҸ„мӢңм§Җм—ӯмқҳ мң м¶ңм—җ мҳҒн–Ҙмқ„ мЈјлҠ” мң м—ӯнҠ№м„ұмһҗлЈҢ(мң м—ӯкІҪмӮ¬, л¶ҲнҲ¬мҲҳмңЁ, кҙҖкұ°л°ҖлҸ„, л°°мҲҳнҺҢн”„мһҘ мҲҳл°©лҠҘл Ҙ, л№—л¬јл°ӣмқҙ л°ҖлҸ„)лҘј мӮ¬мҡ©н•ҳм—¬ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқ„ к°ңл°ңн•ҳмҳҖлӢӨ. к·ёлҹ¬лӮҳ н•ҷмҠөмһҗлЈҢлЎң м„ңмҡёкіј мҡёмӮ°м§Җм—ӯмқҳ мң м—ӯнҠ№м„ұл§Ң мӮ¬мҡ©н•ҳм—¬ м Ғмҡ©лІ”мң„к°Җ мһ‘кі , м Ғмҡ©лІ”мң„лҘј лІ—м–ҙлӮң кІҪмҡ° м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎмқҙ л¶Ҳк°ҖлҠҘн•ң н•ңкі„м җлҸ„ нҷ•мқён•ҳмҳҖлӢӨ. лҳҗн•ң н•ҷмҠөмһҗлЈҢмқҳ л¶ҖмЎұмңјлЎң көҗм°ЁкІҖмҰқмқ„ нҶөн•ҙ лӘЁлҚёмқ„ кІҖмҰқн•ҳкі мӢӨм ң м№ЁмҲҳк°Җ л°ңмғқн•ң м§Җм—ӯмқҳ м№ЁмҲҳмӮ¬мғҒкіј мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳ кё°мӨҖмқ„ 비көҗн•ҳм—¬ лӘЁлҚёмқҳ м Ғмҡ©м„ұмқ„ нҷ•мқён•ҳмҳҖмңјлӮҳ, лӘЁлҚём—җ лҢҖн•ң 충분н•ң нҸүк°ҖмҷҖ кІҖмҰқмқҙ мқҙлЈЁм–ҙм§Җм§Җ м•Ҡм•ҳлӢӨ.
ліё м—°кө¬м—җм„ңлҠ” м ңмӢңлҗң мң м—ӯнҠ№м„ұкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқҳ мҙҲкё°нҷ”н•ЁмҲҳ, н•ҷмҠөмһҗлЈҢмқҳ 추к°Җ кө¬м¶• л°Ҹ м „мІҳлҰ¬ кіјм •мқ„ нҶөн•ҙ лӘЁлҚё мҳҲмёЎ кІ°кіјмқҳ м •нҷ•м„ұмқ„ н–ҘмғҒмӢңнӮӨлҠ”лҚ° лӘ©м Ғмқҙ мһҲлӢӨ.
2. м—°кө¬лӮҙмҡ© л°Ҹ л°©лІ•
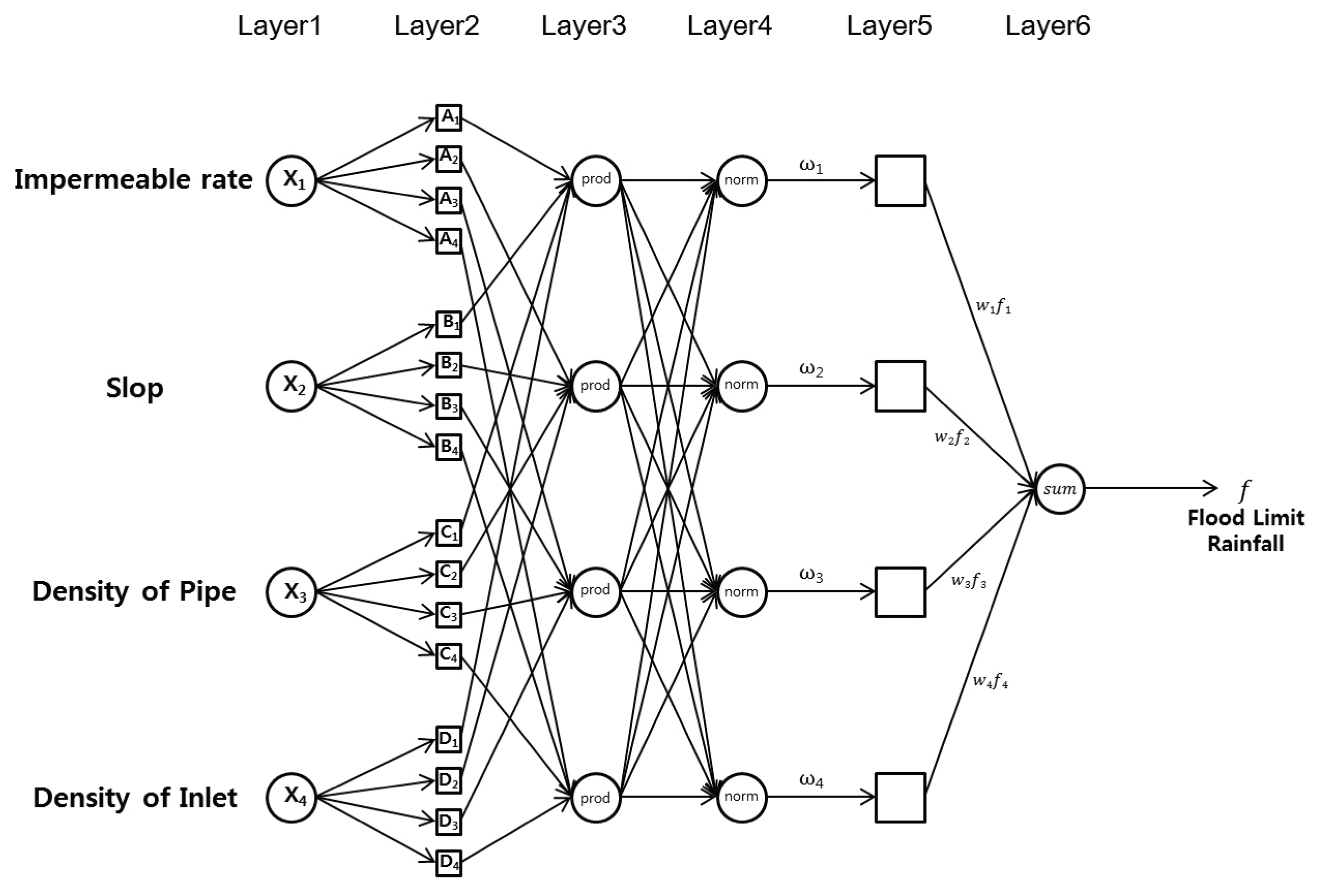
мң м—ӯнҠ№м„ұкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚём—җ мӮ¬мҡ©лҗң NeuroFuzzyлҠ” мқёк°„мқҳ м¶”лЎ лҠҘл Ҙмқ„ к·јмӮ¬н•ң нҚјм§ҖмқҙлЎ кіј н•ҷмҠө л°Ҹ м Ғмқ‘лҠҘл Ҙмқҙ мһҲлҠ” мӢ кІҪл§қмқҙ кІ°н•©лҗҳм–ҙ ліөмһЎм„ұкіј л¶Ҳнҷ•мӢӨм„ұмқ„ лӮҳнғҖлӮҙлҠ” л№„м„ нҳ• мӢңмҠӨн…ңм—җм„ң нҡЁкіјм Ғмқё м•Ңкі лҰ¬мҰҳмқҙлӢӨ. Neuro-Fuzzy лӘЁлҚёмқҳ кё°ліё кө¬мЎ°лҸ„лҠ” Fig. 1м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. мһ…л ҘліҖмҲҳлЎң л¶ҲнҲ¬мҲҳмңЁ, мң м—ӯкІҪмӮ¬, кҙҖкұ°л°ҖлҸ„, л№—л¬јл°ӣмқҙ л°ҖлҸ„лҘј мӮ¬мҡ©н•ҳмҳҖмңјл©°, кІ°кіјліҖмҲҳлЎң н”јн•ҙмқҙл Ҙкё°л°ҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м • к°’мқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ.
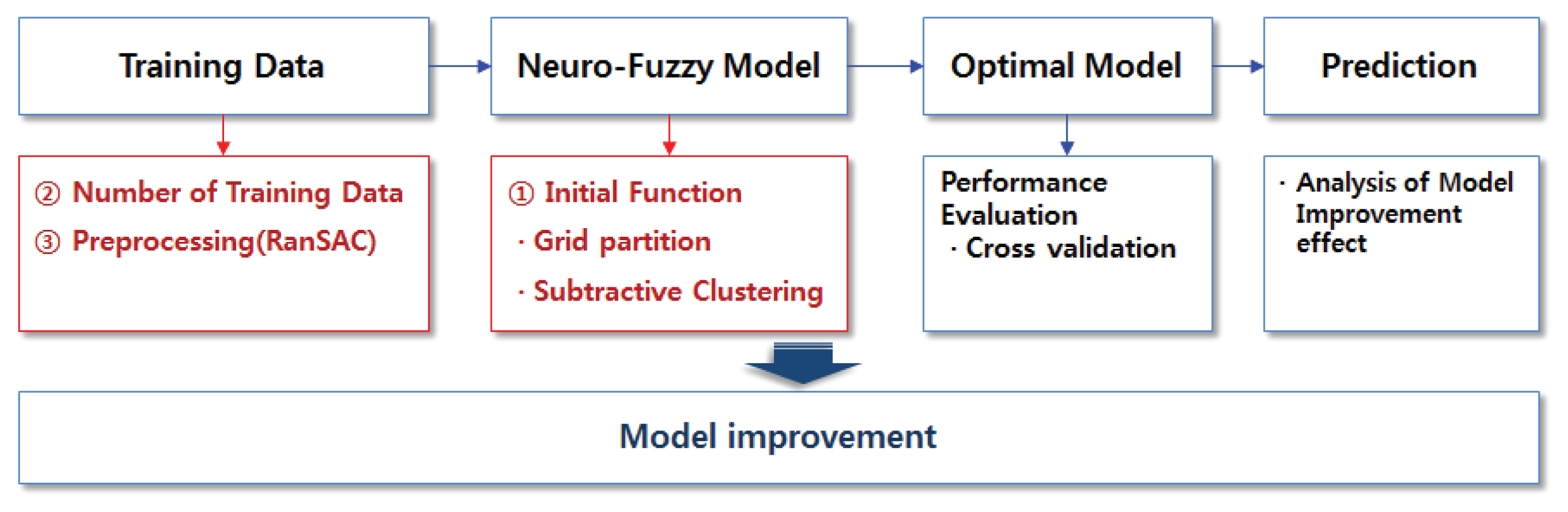
м„ н–үм—°кө¬м—җм„ң м ңмӢңлҗң мң м—ӯнҠ№м„ұкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚё к°ңм„ мқ„ мң„н•ҙ Fig. 2мҷҖ к°ҷмқҙ в‘ мҙҲкё°нҷ” н•ЁмҲҳмҷҖ в‘Ў н•ҷмҠөмһҗлЈҢмқҳ мҲҳ, в‘ў м „мІҳлҰ¬ кё°лІ• л“ұ лӘЁнҳ•мқҳ кө¬мЎ°мҷҖ н•ҷмҠөмһҗлЈҢмқҳ кө¬м„ұмқ„ лӢӨм–‘н•ҳкІҢ м Ғмҡ©н•ҳм—¬ 비көҗн•ҳмҳҖмңјл©°, лӘЁлҚё лі„ м„ұлҠҘнҸүк°ҖлҘј нҶөн•ҙ мөңм Ғ лӘЁлҚёмқ„ м ңмӢңн•ҳмҳҖлӢӨ. лҳҗн•ң кё°мЎҙ лӘЁлҚёкіј к°ңм„ лҗң лӘЁлҚёмқ„ мӢӨм ң м№ЁмҲҳл°ңмғқк°•мҡ°лҹүкіј 비көҗн•ҳм—¬ к°ңм„ нҡЁкіјлҘј 분м„қн•ҳмҳҖлӢӨ.
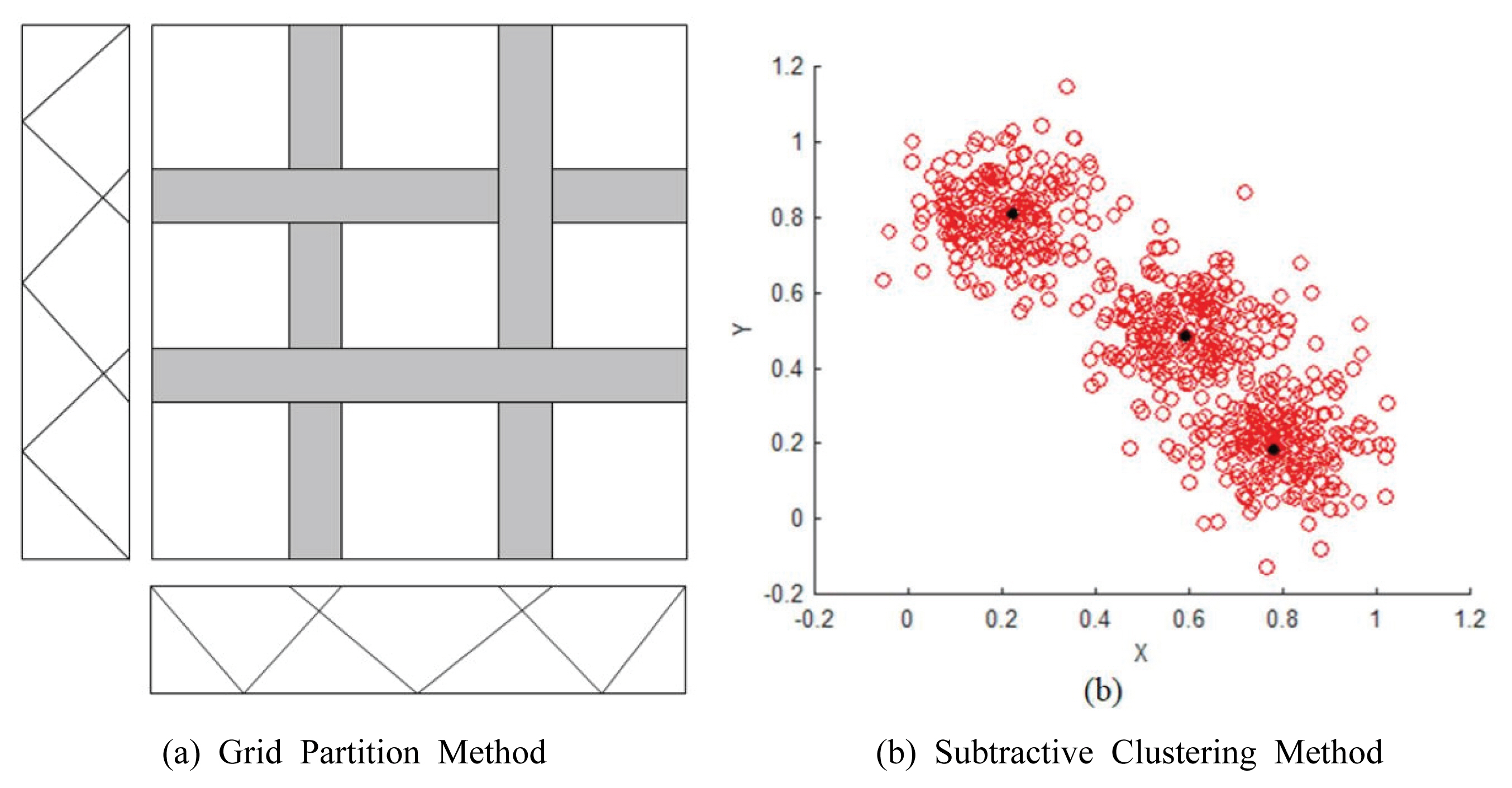
лЁјм Җ Neruo-Fuzzy м•Ңкі лҰ¬мҰҳм—җм„ң нҚјм§Җкө¬мЎ°лҘј кІ°м •н•ҳлҠ” мҡ”мҶҢмқё мҙҲкё°нҷ” н•ЁмҲҳ кө¬м„ұл°©лІ•м—җ л”°лҘё лӘЁлҚё м •нҷ•м„ұмқ„ 비көҗн•ҳкё° мң„н•ҙ м„ н–үм—°кө¬м—җм„ң м Ғмҡ©лҗң Grid Partitionкіј мғҲлЎңмҡҙ кё°лІ•мқё Subtractive Clustering л°©лІ•мқ„ м Ғмҡ©н•ҳм—¬ 비көҗн•ҳмҳҖлӢӨ.
м—¬кё°м„ң Grid Partitionкіј Subtractive ClusteringмқҖ нҚјм§Җм¶”лЎ мӢңмҠӨн…ң(Fuzzy Inference System)мқҳ мҙҲкё°нҷ” л°©лІ•мңјлЎң лҸ…лҰҪ ліҖмҲҳ(мң м—ӯкІҪмӮ¬, л¶ҲнҲ¬мҲҳмңЁ, кҙҖкұ°л°ҖлҸ„, л°°мҲҳнҺҢн”„мһҘ мҲҳл°©лҠҘл Ҙ, л№—л¬јл°ӣмқҙ л°ҖлҸ„)мҷҖ мў…мҶҚліҖмҲҳ(м№ЁмҲҳмң„н—ҳкё°мӨҖ) мӮ¬мқҙмқҳ кҙҖкі„лҘј м •мқҳн•ҳлҠ” мҙҲкё° л©ӨлІ„мүҪ н•ЁмҲҳлҘј м„Өм •н•ҳлҠ” л°©лІ•мқҙлӢӨ. Grid PartitionмқҖ к°Ғ лҸ…лҰҪліҖмҲҳмҷҖ мў…мҶҚліҖмҲҳмқҳ м „ лІ”мң„лҘј мқјм •н•ң к°„кІ©мқҳ л©ӨлІ„мүҪ н•ЁмҲҳлЎң кө¬м„ұн•ҳкі , мһ…вӢ…м¶ңл ҘліҖмҲҳ(лҸ…лҰҪліҖмҲҳ-мў…мҶҚліҖмҲҳ)лҘј Fig. 3(a)мҷҖ к°ҷмқҖ кІ©мһҗ нҳ•нғңлЎң кө¬м„ұн•ҳм—¬ к°Ғ кө¬к°„м—җ м—°кІ°лҗң лҸ…лҰҪліҖмҲҳмҷҖ мў…мҶҚліҖмҲҳмқҳ кҙҖкі„лҘј л©ӨлІ„мүҪ н•ЁмҲҳлЎң м •мқҳн•ҳлҠ” л°©лІ•мқҙлӢӨ. л°ҳл©ҙм—җ Subtractive Clustering кё°лІ•мқҳ кІҪмҡ° Fig. 3(b)мҷҖ к°ҷмқҙ к°Ғ мқёмһҗл“Өмқҙ л°Җ집лҗҳм–ҙ мһҲлҠ” лІ”мң„л§Ңмқ„ лҢҖмғҒмңјлЎң мЎ°кұҙ-кІ°кіј кҙҖкі„лҘј кө¬м„ұн•ҳлҠ” л°©лІ•мқ„ м„ нғқн•ҳкІҢ лҗңлӢӨ. нҚјм§ҖлЈ°(мЎ°кұҙ-кІ°кіј кҙҖкі„мӢқ)мқҳ мҲҳмҷҖ кІ°кіјмқҳ м •нҷ•м„ұкіјлҠ” мғҒкҙҖм„ұмқҙ м—Ҷмңјл©°, Grid Partitionмқ„ нҶөн•ҙ мһ…вӢ…м¶ңл ҘліҖмҲҳмқҳ м „ кө¬к°„м—җ лҢҖн•ң нҚјм§ҖкҙҖкі„мӢқмқ„ л§Ңл“Өкё°ліҙлӢӨлҠ” Subtractive Clustering кё°лІ•мқ„ мӮ¬мҡ©н•ҳм—¬ лӘЁнҳ•мқҳ нҡЁмңЁм„ұ л°Ҹ лё”лһҷл°•мҠӨлӘЁнҳ•мқҳ мһҘм җмқ„ мөңлҢҖн•ң нҷңмҡ©н•ҳлҠ” л°©лІ•мқҙ л§Һмқҙ мӮ¬мҡ©лҗҳкі мһҲлӢӨ.
л‘җ лІҲм§ёлЎң 161к°ң н•ҷмҠөмһҗлЈҢлҘј 추к°ҖлЎң кө¬м¶•н•ҳкі н•ҷмҠөмһҗлЈҢмқҳ мҲҳлҘј лӢӨм–‘н•ҳкІҢ м Ғмҡ©н•ҳм—¬ лӘЁлҚё м •нҷ•м„ұмқ„ 비көҗн•ҳмҳҖмңјл©°, л§Ҳм§Җл§үмңјлЎң м •мғҒлІ”мң„лҘј лІ—м–ҙлӮң н•ҷмҠөмһҗлЈҢлҘј м ңкұ°н•ҳкё° мң„н•ҙ RanSAC кё°лІ•мқ„ м Ғмҡ©н•ҳм—¬ м „мІҳлҰ¬ кіјм •мқ„ кұ°м№ң н•ҷмҠөмһҗлЈҢлҘј мӮ¬мҡ©н•ң лӘЁлҚёкіј 비көҗн•ҳмҳҖлӢӨ.
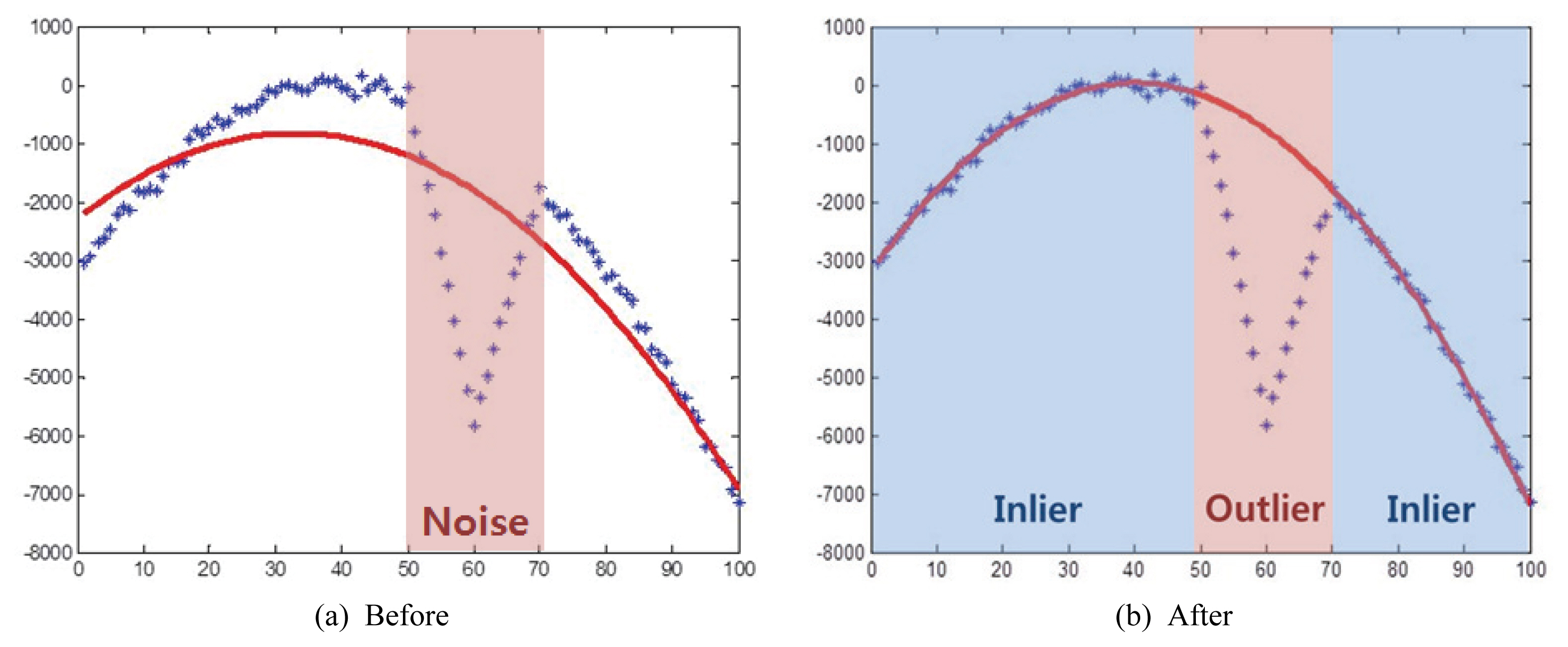
RanSAC кё°лІ•мқҖ кұ°м§“м •ліҙлҘј нҸ¬н•Ён•ҳлҠ” мқјл Ёмқҳ лҚ°мқҙн„° 집합мңјлЎң л¶Җн„° мҲҳн•ҷм Ғ лӘЁлҚё мқёмһҗл“Өмқ„ л°ҳліөм Ғмқё мһ‘м—…мңјлЎң мҳҲмёЎн•ҳм—¬ н•ҷмҠөмһҗлЈҢмқҳ мқҙмғҒм№ҳ(Outlier) мҰү, м •мғҒ분нҸ¬(Inlier)м—җм„ң лІ—м–ҙлӮң к°’мқ„ н•ҷмҠөмһҗлЈҢм—җм„ң м ңмҷёмӢңнӮӨлҠ” кё°лІ•мқҙлӢӨ. мҳҲлҘј л“Өм–ҙ Fig. 4(a)мҷҖ к°ҷмқҙ л…ёмқҙмҰҲ(Noise) лҚ°мқҙн„°лҘј нҸ¬н•Ён•ң н•ҷмҠөмһҗлЈҢ м „мІҙлҘј нҷңмҡ©н• кІҪмҡ° м •мғҒлІ”мң„мқҳ лҚ°мқҙн„°м—җм„ңлҸ„ мҳӨм°Ёк°Җ л°ңмғқн• мҲҳ мһҲлӢӨ. к·ёлҹ¬лӮҳ Fig. 4(b)мҷҖ к°ҷмқҙ RanSAC м•Ңкі лҰ¬мҰҳмқ„ нҷңмҡ©н•ҳм—¬ OutlierлҘј м ңкұ°н•ң кІҪмҡ° м •мғҒлІ”мң„мқҳ лҚ°мқҙн„°м—җм„ң м •нҷ•н•ң кІ°кіјлҘј м–»мқ„ мҲҳ мһҲлӢӨ.
л§Ҳм§Җл§үмңјлЎң мҙҲкё°нҷ” н•ЁмҲҳ л°Ҹ н•ҷмҠөмһҗлЈҢмқҳ кө¬м„ұм—җ л”°лҘё мөңм Ғ лӘЁлҚёмқ„ м ңмӢңн•ҳкі , лҜёкі„мёЎ м§Җм—ӯм—җ лҢҖн•ң м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ кІ°кіјлҘј мӢӨм ң м№ЁмҲҳмӮ¬мғҒкіј 비көҗн•ҳм—¬ лӘЁлҚёмқҳ м Ғмҡ©м„ұмқ„ нҷ•мқён•ҳмҳҖлӢӨ.
лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚё к°ңм„ нҡЁкіјлҘј 비көҗвӢ…분м„қн•ҳкё° мң„н•ҙ Table 1кіј к°ҷмқҙ мҙҲкё°нҷ” н•ЁмҲҳ, н•ҷмҠөмһҗлЈҢ мҲҳ, RanSAC кё°лІ• м Ғмҡ© м—¬л¶Җм—җ л”°лқј 9к°ңмқҳ CaseлЎң н•ҷмҠөмһҗлЈҢлҘј кө¬м„ұн•ҳмҳҖлӢӨ.
лӘЁлҚёмқҳ нҸүк°Җл°©лІ•мңјлЎңлҠ” н•ҷмҠөлҚ°мқҙн„°мқҳ мҲҳк°Җ мһ‘мқҖ кІҪмҡ°м—җлҸ„ кІҖмҰқмқҙ к°ҖлҠҘн•ң көҗм°ЁкІҖмҰқ л°©лІ•мқ„ м Ғмҡ©н•ҳмҳҖлӢӨ.
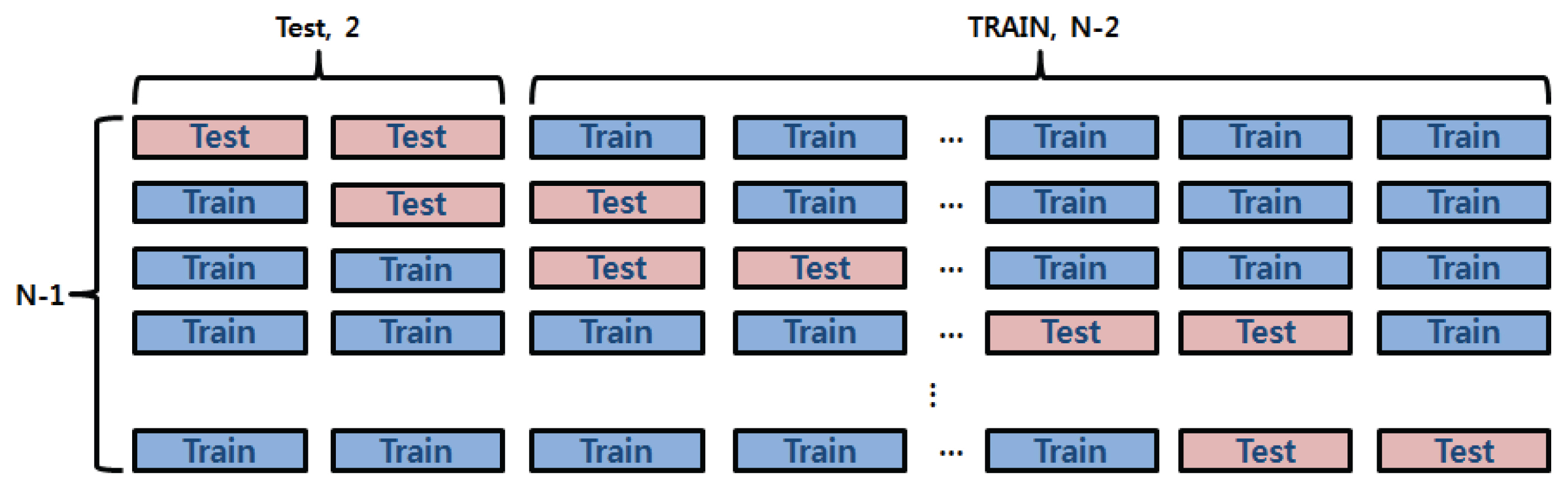
Fig. 5мҷҖ к°ҷмқҙ м „мІҙ мһҗлЈҢ мҲҳ Nк°ң мӨ‘ 2к°ң мһҗлЈҢлҘј кІҖмҰқ(Test)мһҗлЈҢлЎң мӮ¬мҡ©н•ҳкі , лӮҳлЁём§Җ N-2к°ңмқҳ мһҗлЈҢлҘј н•ҷмҠө(Train)м—җ мӮ¬мҡ©н•ҳлҠ” л°©лІ•мңјлЎң N-1к°ңмқҳ лҚ°мқҙн„° м…ӢмңјлЎң кө¬м„ұн•ҳмҳҖлӢӨ. мҳҲлҘј л“Өл©ҙ Model Aмқҳ кІҪмҡ° 27к°ң мһҗлЈҢ мӨ‘ 25к°ңлҘј н•ҷмҠөмһҗлЈҢ, н•ҷмҠөм—җ мӮ¬мҡ©лҗҳм§Җ м•ҠмқҖ 2к°ңлҘј кІҖмҰқмһҗлЈҢлЎң мӮ¬мҡ©н•ҳм—¬, мҙқ 26к°ңмқҳ лҚ°мқҙн„° м…ӢмңјлЎң кө¬м„ұн•ҳмҳҖлӢӨ.
к°Ғ лӘЁлҚёк°„мқҳ 비көҗлҘј мң„н•ҙ нҸүк· мҳӨм°ЁмҷҖ Root Mean Square Error (RMSE)лҘј 비көҗн•ҳм—¬ лӘЁлҚёмқ„ нҸүк°Җн•ҳмҳҖлӢӨ.
м—¬кё°м„ң, нҸүк· мҳӨм°ЁлҠ” Eq. (1)лЎң кі„мӮ°лҗҳл©°, Root Mean Square Error (RMSE)лҠ” нҸүк· м ңкіұк·јмҳӨм°ЁлҘј мқҳлҜён•ҳл©°, н‘ңмӨҖнҺём°ЁлҘј мқјл°ҳнҷ”мӢңнӮЁ к°’мңјлЎң мӢӨм ңк°’кіј м¶”м •к°’мқҳ м°ЁмқҙлҘј лӮҳнғҖлӮҙлҠ” мІҷлҸ„лЎң мӮ¬мҡ©лҗңлӢӨ. RMSEлҠ” Eq. (2)лҘј мқҙмҡ©н•ҳм—¬ мӮ°м •н•ҳмҳҖлӢӨ.
Eqs. (1), (2)м—җм„ң y ^
3. мҙҲкё°нҷ” н•ЁмҲҳ к°ңм„
мҙҲкё°нҷ” н•ЁмҲҳлҠ” Neuro-Fuzzy м•Ңкі лҰ¬мҰҳм—җм„ң Fuzzy кө¬мЎ°лҘј кІ°м •н•ҳлҠ” н•ЁмҲҳлЎң мЎ°кұҙм—җ л”°лқјм„ң лӘЁлҚёмқҳ мҳҲмёЎл Ҙ, н•ҷмҠөмӢңк°„ л“ұм—җ мҳҒн–Ҙмқ„ мӨ„ мҲҳ мһҲлӢӨ. м„ н–үм—°кө¬м—җм„ңлҠ” м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎмқ„ мң„н•ң Neuro-Fuzzy м•Ңкі лҰ¬мҰҳмқҳ м Ғмҡ© к°ҖлҠҘм„ұмқ„ мӢңн—ҳн•ҙліҙлҠ” мҙҲкё°лӢЁкі„м—°кө¬лЎң Fuzzy л©ӨлІ„мүҪ н•ЁмҲҳ(Membership Function)мқҳ нҳ•нғң л°Ҹ к°ңмҲҳ л“ұмқ„ к°ңл°ңмһҗк°Җ м§Ғм ‘ м§Җм •н•ҳкі лӘЁнҳ•мқҳ н•ҷмҠөм—җ мӮ¬мҡ©н•ҳлҠ” мҙҲкё° л©ӨлІ„мүҪ н•ЁмҲҳмқҳ м§Җм •м—җ кө°м§‘нҷ” кё°лІ• мӨ‘ Grid Partitionл°©лІ•мқ„ мӮ¬мҡ©н•ҳлҠ” л“ұ к°ңл°ңмһҗмқҳ нҢҗлӢЁмқҙ м•Ңкі лҰ¬мҰҳмқҳ кө¬мЎ° кІ°м •м—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ” н•ҷмҠөл°©лІ•мқ„ мӮ¬мҡ©н•ң лӘЁлҚё м—°кө¬лҘј мҲҳн–үн•ҳмҳҖлӢӨ. мҰү, м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎм—җм„ң к°ҖмһҘ мӨ‘мҡ”н•ң н”јн•ҙмқҙл Ҙкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м • кІ°кіјк°Җ л¶ҖмЎұн•ң мғҒнҷ©м—җм„ң лӘЁнҳ•мқҳ м •нҷ•м„ұ л°Ҹ м Ғмҡ©м„ұ н–ҘмғҒ л°©м•Ҳм—җ мӨ‘м җмқ„ л‘” м—°кө¬лҘј мҲҳн–үн•ҳмҳҖлӢӨ.
м„ н–ү м—°кө¬м—җм„ң мӮ¬мҡ©лҗң л©ӨлІ„мүҪ н•ЁмҲҳлҠ” Table 2мҷҖ к°ҷлӢӨ.
ліё м—°кө¬м—җм„ңлҠ” Subtractive Clustering кё°лІ•мқ„ м Ғмҡ©н•ҳм—¬ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқ„ мһ¬кө¬м„ұн•ҳмҳҖмңјл©°, Grid Partition кё°лІ•мқ„ м Ғмҡ©н•ң лӘЁлҚёкіј 비көҗн•ҳм—¬ м •нҷ•м„ұмқҙ лҶ’мқҖ кё°лІ•мқ„ лӘЁлҚём—җ м Ғмҡ©н• кІғмқҙлӢӨ. Subtractive Clustering кё°лІ•мқҳ кІҪмҡ° Influence, Quash Factor, Accept Ratio, Reject Ratio 4к°ңмқҳ нҢҢлқјлҜён„°к°Җ мһҲмңјл©°, Table 3кіј к°ҷмқҙ кё°ліёмңјлЎң м ңкіөн•ҳлҠ” к°’мқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. нҚјм§Җм¶”лЎ кё°лІ• н•ҷмҠөкіјм •м—җм„ңлҠ” кё°мЎҙ м—°кө¬мҷҖ лҸҷмқјн•ҳкІҢ Least-Square кё°лІ•кіј Back-Propagation кё°лІ•мқ„ лі‘н–үн•ҳм—¬ мӮ¬мҡ©н•ҳлҠ” Hybrid кё°лІ•мқ„ мӮ¬мҡ©н•ҳкі , 10нҡҢ л°ҳліөн•ҳм—¬ н•ҷмҠөн•ҳлҸ„лЎқ н•ҳмҳҖлӢӨ.
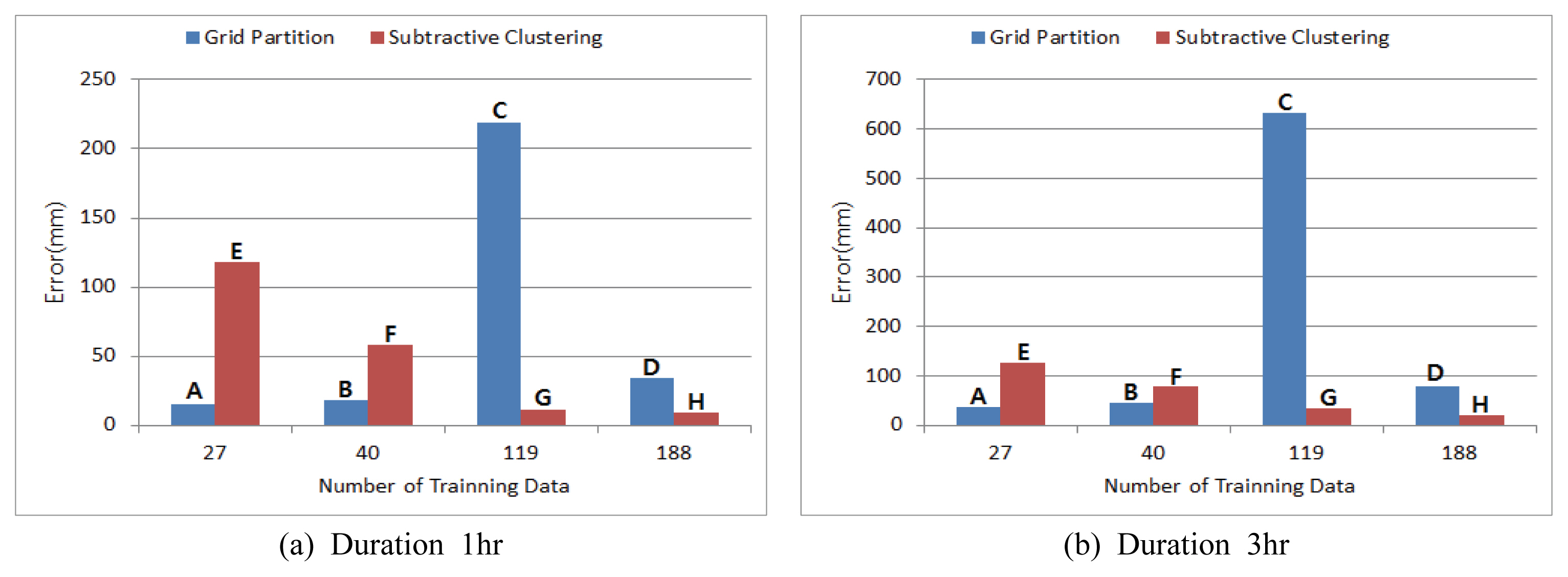
мҙҲкё°нҷ” н•ЁмҲҳм—җ л”°лҘё к°ңм„ нҡЁкіјлҘј 분м„қн•ҳкё° мң„н•ҙ н•ҷмҠөмһҗлЈҢ мҲҳлҘј лҸҷмқјн•ҳкІҢ н•ҳкі мҙҲкё°нҷ” н•ЁмҲҳлҘј Grid Partitionкіј Subtractive Clustering м Ғмҡ©н•ң Table 1мқҳ Model A, B, C, DмҷҖ Model E, F, G, Hмқ„ 비көҗн•ҳм—¬ Table 4мҷҖ Fig. 6м—җ лӮҳнғҖлӮҙм—ҲлӢӨ.
н•ҷмҠөмһҗлЈҢмқҳ мҲҳк°Җ мһ‘мқ„ кІҪмҡ° Grid Partitionмқҙ Subtractive Clustering ліҙлӢӨ м •нҷ•м„ұмқҙ лҶ’м•ҳмңјл©°, н•ҷмҠөмһҗлЈҢк°Җ мҰқк°Җн•ң кІҪмҡ° Subtractive Clustering л°©лІ•мқҙ м •нҷ•м„ұмқҙ лҶ’м•„м§ҖлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. нҠ№нһҲ н•ҷмҠөмһҗлЈҢ 119к°ңлҘј мӮ¬мҡ©н•ң мЎ°кұҙм—җм„ң Grid Partitionмқ„ мӮ¬мҡ©н•ң лӘЁлҚёмқҳ нҸүк· мҳӨм°Ёк°Җ нҒ¬кІҢ л°ңмғқн•ҳмҳҖлҠ”лҚ°, мқҙлҠ” мў…мҶҚліҖмҲҳмқё м№ЁмҲҳмң„н—ҳкё°мӨҖмқҖ лҸҷмқјн•ҳм§Җл§Ң лҸ…лҰҪліҖмҲҳк°Җ лҗҳлҠ” мң м—ӯнҠ№м„ұмһҗлЈҢмқҳ мҲҳм№ҳк°Җ лӢӨлҘё н•ҷмҠөмһҗлЈҢ мҰү, лӘЁлҚё н•ҷмҠөм—җ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ мЈјлҠ” н•ҷмҠөмһҗлЈҢк°Җ лӢӨмҲҳ нҸ¬н•Ёлҗҳм–ҙ мһҲкё° л•Ңл¬ёмқё кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ. л°ҳл©ҙм—җ Subtractive Clustering л°©лІ•мқҖ мқҙмҷҖ к°ҷмқҖ л¬ём ңлҘј мһҳ ліҙм •н•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
4. н•ҷмҠөмһҗлЈҢ 추к°Җ кө¬м¶•
н•ҷмҠөмһҗлЈҢмқҳ 추к°Җ кө¬м¶•мқ„ мң„н•ҙ мөңк·ј 5л…„(вҖҷ13вҲјвҖҷ17)к°„ м№ЁмҲҳн”јн•ҙк°Җ л§ҺмқҖ м§Җм—ӯ 123к°ң мӢңкө°кө¬ 1,784к°ң мқҚл©ҙлҸҷмқ„ 분м„қн•ҳм—¬, м„ңмҡё 8к°ң, лҢҖм „ 3к°ң, кҙ‘мЈј 1к°ң, мқёмІң 25к°ң, л¶ҖмӮ° 47к°ң, кІҪкё°лҸ„ 105к°ң, к°•мӣҗлҸ„ 1к°ң, кІҪмғҒл¶ҒлҸ„ 11к°ң, 충мІӯлӮЁлҸ„ 4к°ң л“ұ 205к°ң мқҚл©ҙлҸҷм—җ лҢҖн•ң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ м¶”м •н•ҳмҳҖлӢӨ. м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м • кІ°кіјлҠ” Table 5мҷҖ к°ҷмқҙ мҡ”м•Ҫн•ҳмҳҖлӢӨ.
м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚё к°ңл°ңмқ„ мң„н•ң н•ҷмҠөмһҗлЈҢ кө¬м¶•мқ„ мң„н•ҙ к°Ғ м§ҖмһҗмІҙм—җ мҡ”мІӯн•ҳм—¬ мөңмӢ мқҳ м§Җнҳ•кіөк°„м •ліҙмһҗлЈҢлҘј мҲҳ집н•ҳмҳҖмңјл©°, кҙҖкұ°л°ҖлҸ„, л¶ҲнҲ¬мҲҳмңЁ, мң м—ӯкІҪмӮ¬, л№—л¬јл°ӣмқҙ л°ҖлҸ„ л“ұ 4к°ңмқҳ мң м—ӯнҠ№м„ұмһҗлЈҢлҘј GIS분м„қмқ„ нҶөн•ҙ кө¬м¶•н•ҳмҳҖлӢӨ. н”јн•ҙмқҙл Ҙкё°л°ҳмңјлЎң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ м¶”м •н•ң 205к°ң мқҚл©ҙлҸҷ мӨ‘ мң м—ӯнҠ№м„ұмһҗлЈҢк°Җ кө¬м¶•лҗң м§Җм—ӯмқҖ 161к°ңлЎң м„ н–үм—°кө¬м—җм„ң мӮ¬мҡ©лҗң н•ҷмҠөмһҗлЈҢ 27к°ңлҘј нҸ¬н•Ён•ҳм—¬ мҙқ 188к°ңлҘј н•ҷмҠөмһҗлЈҢлҘј кө¬м¶•н•ҳмҳҖлӢӨ.
м„ н–үм—°кө¬м—җм„ң мЈјмҡ”л§Өк°ңліҖмҲҳлЎң мӮ¬мҡ©н–ҲлҚҳ л№—л¬јнҺҢн”„мһҘмқҳ мҲҳмһҘлҠҘл ҘмқҖ к°қкҙҖм Ғмқё мҲҳм№ҳлҘј нҷ•ліҙн• мҲҳ м—Ҷмқ„ лҝҗл§Ң м•„лӢҲлқј, л№—л¬јнҺҢн”„мһҘ мӢңм„Өмқҳ мң л¬ҙм—җ л”°лқј м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎкІ°кіјм—җ мҳҒн–Ҙмқҙ нҒ¬кІҢ лӮҳнғҖлӮҳлҜҖлЎң н•ҷмҠөмһҗлЈҢм—җ л¶Җм Ғн•© н•ҳлӢӨкі нҢҗлӢЁн•ҳм—¬ мң м—ӯнҠ№м„ұ мһҗлЈҢм—җм„ң м ңмҷён•ҳмҳҖлӢӨ.
н•ҷмҠөмһҗлЈҢмқҳ мң м—ӯнҠ№м„ұлІ”мң„лҠ” Table 6м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. мғҲлЎңмҡҙ м§Җм—ӯм—җ лҢҖн•ң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн• кІҪмҡ° мҳҲмёЎн•ҳкі мһҗ н•ҳлҠ” м§Җм—ӯмқҳ мң м—ӯнҠ№м„ұмһҗлЈҢк°Җ лӘЁлҚё н•ҷмҠөмһҗлЈҢм—җ мӮ¬мҡ©лҗң лІ”мң„лҘј лІ—м–ҙлӮ кІҪмҡ° мҳҲмёЎкІ°кіјк°Җ л°ңмӮ°н•ҳкұ°лӮҳ нҒ° мҳӨм°Ёк°Җ л°ңмғқн•ҳлҠ” л“ұ мӢ лў°н• мҲҳ м—ҶлҠ” кІ°кіјк°’мқҙ мЈјм–ҙм§Җкё° л•Ңл¬ём—җ мң м—ӯнҠ№м„ұмһҗлЈҢмқҳ лІ”мң„лҠ” л§Өмҡ° мӨ‘мҡ”н•ҳл©°, лӘЁнҳ•мқ„ нҶөн•ң м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎмӢң мӮ¬мҡ©лҗң н•ҷмҠөмһҗлЈҢмқҳ м Ғмҡ© лІ”мң„лҘј л°ҳл“ңмӢң нҷ•мқён• н•„мҡ”к°Җ мһҲлӢӨ. кҙҖкұ°л°ҖлҸ„лҠ” 0~0.5222, л¶ҲнҲ¬мҲҳмңЁмқҖ 1.2~100.0, мң м—ӯкІҪмӮ¬, 0.01~39.85%, л№—л¬јл°ӣмқҙ л°ҖлҸ„лҠ” 0~0.0055мқҳ лІ”мң„лҘј к°–лҠ” кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, кҙҖкұ°л°ҖлҸ„мҷҖ л№—л¬јл°ӣмқҙ л°ҖлҸ„мқҳ кІҪмҡ° н•ҳмҲҳмӢңм„Өмқҙ кө¬м¶•лҗҳм§Җ м•Ҡкұ°лӮҳ мң м—ӯл©ҙм ҒлҢҖ비 л§Өмҡ° мһ‘мқҖ 비мӨ‘мқ„ м°Ём§Җн•ҳлҠ” м§Җм—ӯмқҙ мһҲм–ҙ мөңмҶҢк°’мқҙ 0мқё мң м—ӯмқҙ л°ңмғқн•ҳмҳҖлӢӨ.
н•ҷмҠөмһҗлЈҢ мҲҳм—җ л”°лҘё лӘЁлҚё м •нҷ•м„ұ 비көҗлҘј мң„н•ҙ мҙҲкё°нҷ” н•ЁмҲҳлҘј Subtractive ClusteringмңјлЎң н•ҳкі н•ҷмҠөмһҗлЈҢмқҳ мҲҳлҘј к°Ғк°Ғ 27к°ң, 40к°ң, 119к°ң, 188к°ңлЎң мҰқк°ҖмӢңнӮӨл©ҙм„ң н•ҷмҠөн•ң Model E, F, G, Hмқҳ нҸүк· мҳӨм°ЁмҷҖ RMSEлҘј Table 7м—җ лӮҳнғҖлӮҙм—ҲлӢӨ.
н•ҷмҠөмһҗлЈҢк°Җ 27к°ңм—җм„ң 40к°ңлЎң мҰқк°Җн• кІҪмҡ° м§ҖмҶҚмӢңк°„ 1мӢңк°„мқҳ кІҪмҡ° нҸүк· мҳӨм°ЁлҠ” 50.3% к°җмҶҢн•ҳмҳҖмңјл©°, 119к°ңмқј кІҪмҡ° 90.7%, 188к°ңмқё кІҪмҡ° 91.8% к°җмҶҢн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. м§ҖмҶҚмӢңк°„ 3мӢңк°„м—җм„ңлҠ” к°Ғк°Ғ 38.5%, 72.2%, 84.2% к°җмҶҢн•ҳмҳҖлӢӨ. RMSEлҸ„ м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җм„ң 23.4%вҲј96.3%к№Ңм§Җ к°җмҶҢн•ҳмҳҖмңјл©°, 3мӢңк°„м—җм„ңлҸ„ 25.0%вҲј84.4% к№Ңм§Җ к°җмҶҢн•ҳмҳҖлӢӨ.
Figs. 7вҲј8мқҳ н•ҷмҠөмһҗлЈҢмқҳ мҲҳ мҰқк°Җм—җ л”°лҘё нҸүк· мҳӨм°ЁмҷҖ RMSEлҘј м§ҖмҶҚмӢңк°„лі„лЎң 비көҗн•ң к·ёлһҳн”„лҘј нҶөн•ҙ лӘЁлҚё н•ҷмҠөмһҗлЈҢмқҳ мҲҳк°Җ мҰқк°Җн•ҳл©ҙ нҸүк· мҳӨм°ЁмҷҖ RMSEлҠ” к°җмҶҢн•ҳлҠ” кІғмқ„ нҷ•мқё н• мҲҳ мһҲлӢӨ. л”°лқјм„ң н•ҷмҠөмһҗлЈҢ мҲҳк°Җ мҰқк°Җн•Ём—җ л”°лқј лӘЁлҚёмқҳ м •нҷ•м„ұмқҖ мҰқк°Җн•ҳл©°, н•ҷмҠөмһҗлЈҢмқҳ 추к°Җ кө¬м¶•мқ„ нҶөн•ҙ лӘЁлҚёмқҳ м •нҷ•лҸ„лҘј н–ҘмғҒмӢңнӮ¬ мҲҳ мһҲмқ„ кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.
5. лҚ°мқҙн„° м „мІҳлҰ¬ кё°лІ• м Ғмҡ©
м„ н–үм—°кө¬м—җм„ңлҠ” н•ҷмҠөмһҗлЈҢк°Җ 27к°ңм—җ л¶Ҳкіјн•ҳм—¬ лҚ°мқҙн„° м „мІҳлҰ¬к°Җ л¶Ҳк°ҖлҠҘ н•ҳмҳҖлӢӨ. к·ёлҹ¬лӮҳ ліё м—°кө¬м—җм„ңлҠ” н•ҷмҠөмһҗлЈҢмқҳ 추к°Җкө¬м¶•мқ„ нҶөн•ҙ мҙқ 188к°ңмқҳ н•ҷмҠөмһҗлЈҢлҘј нҷ•ліҙн•ҳмҳҖкі , мҳҲмёЎ кІ°кіјм—җ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ лҜём№ҳлҠ” н•ҷмҠөмһҗлЈҢлҘј м„ лі„н•ҳкё° мң„н•ҙ RanSACкё°лІ•мқ„ м Ғмҡ©н•ҳмҳҖлӢӨ. мҲҳн–үкіјм •мқҖ н•ҷмҠөмһҗлЈҢм—җм„ң мһ„мқҳмқҳ к°ңмҲҳлҘј м •мғҒ분нҸ¬(Inlier)лЎң к°Җм •н•ҳм—¬ нҡҢк·ҖлӘЁлҚёмқ„ кө¬н•ҳкі , лӮҳлЁём§Җ лҚ°мқҙн„°л“Өмқ„ нҡҢк·ҖлӘЁлҚёкіј 비көҗн•ҳм—¬ н—Ҳмҡ©мҳӨм°Ё лӮҙм—җ мһҲлҠ” н•ҷмҠөмһҗлЈҢлҘј InlierлЎң нҸ¬н•Ён•ҳкі мһ¬кө¬м„ұлҗң InlierлҘј мқҙмҡ©н•ҳм—¬ лӢӨмӢң нҡҢк·ҖлӘЁлҚёмқ„ кө¬н•ҳкі , нҡҢк·ҖлӘЁлҚёкіј Inlierмқҳ мҳӨм°ЁлҘј мёЎм •н•ҳм—¬ н—Ҳмҡ©мҳӨм°Ё лІ”мң„ лӮҙм—җ лҸ„лӢ¬н• л•Ңк№Ңм§Җ л°ҳліөн•ҳмҳҖлӢӨ. к·ё кІ°кіј мҙқ 188к°ң н•ҷмҠөмһҗлЈҢ мӨ‘ м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җм„ңлҠ” м •мғҒ분нҸ¬ лІ”мң„лҘј лІ—м–ҙлӮң 45к°ңлҘј м ңмҷён•ң 145к°ң, 3мӢңк°„м—җм„ңлҠ” 90к°ңлҘј м ңмҷён•ң 98к°ңлҘј н•ҷмҠөмһҗлЈҢлЎң мӮ¬мҡ©н•ҳм—¬ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқ„ м„Өкі„н•ҳмҳҖлӢӨ.
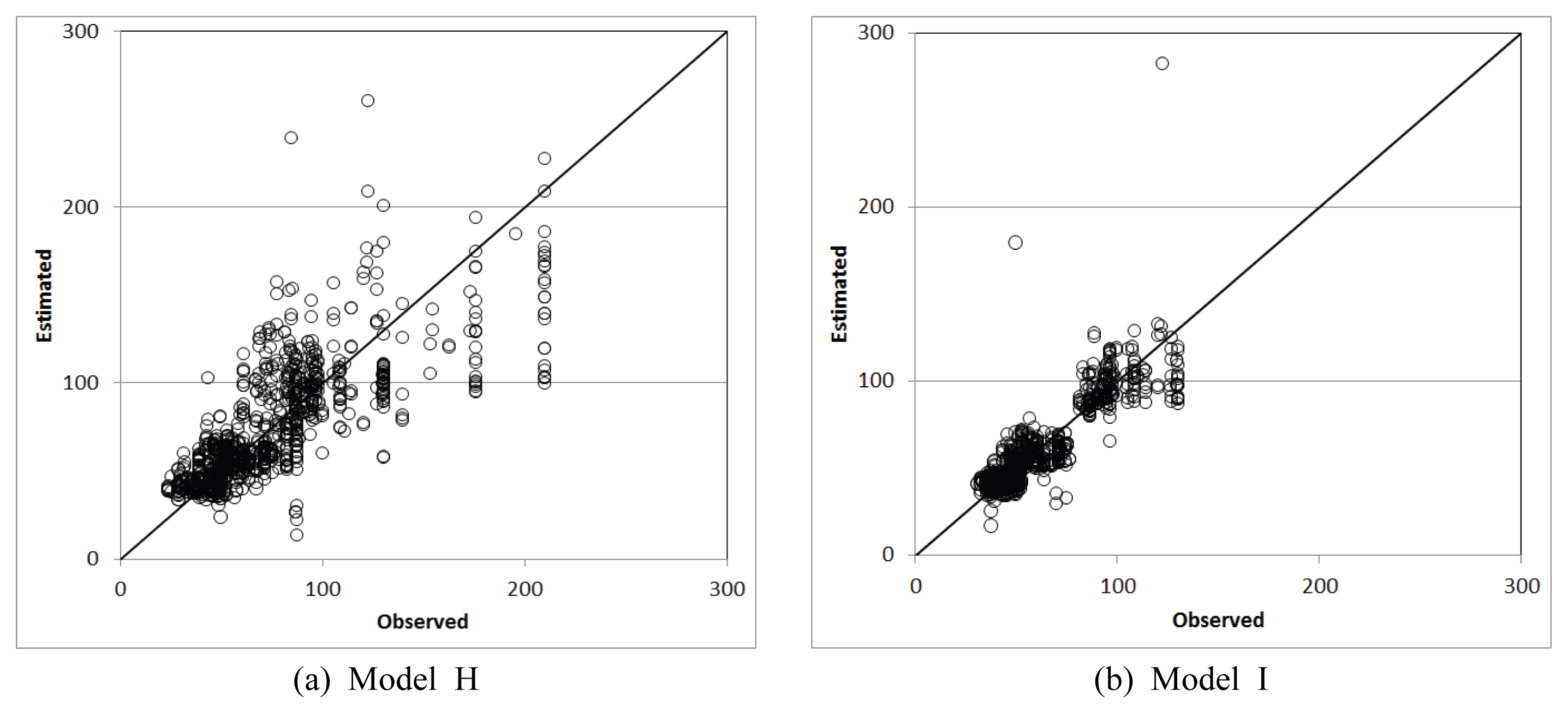
RanSAC кё°лІ•мқ„ м Ғмҡ©н•ң Model IмҷҖ 188к°ң н•ҷмҠөмһҗлЈҢлҘј лӘЁл‘җ мӮ¬мҡ©н•ң Model HлҘј 비көҗн•ҳм—¬ Table 8 л°Ҹ Fig. 9м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. нҸүк· мҳӨм°ЁлҠ” м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җм„ң 1.5 mm к°җмҶҢ, 3мӢңк°„м—җм„ңлҠ” 7.3 mm к°җмҶҢн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, RMSEлҸ„ к°Ғк°Ғ 2.5, 11.7 к°җмҶҢн•ҳм—¬ лӘЁлҚё м •нҷ•лҸ„к°Җ мҰқк°Җн•ҳлҠ” кІғмңјлЎң 분м„қлҗҳм—ҲлӢӨ.
6. лӘЁлҚё к°ңм„ нҡЁкіј 비көҗ л°Ҹ м Ғмҡ©м„ұ кІҖмҰқ
мҙқ 123к°ң мӢңкө°кө¬ 1,784к°ң мқҚл©ҙлҸҷ мӨ‘ н”јн•ҙмқҙл Ҙкё°л°ҳмқҳ м№ЁмҲҳ мң„н—ҳкё°мӨҖ м¶”м •мқҙ л¶Ҳк°ҖлҠҘн•ң 1,579к°ң мқҚл©ҙлҸҷмқҳ мң м—ӯнҠ№м„ұмһҗлЈҢлҘј мҲҳ집вӢ…분м„қн•ҳкі , Model Iм—җ м Ғмҡ©н•ҳм—¬ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳмҳҖлӢӨ. мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖ кІ°кіј мӨ‘ мқјл¶ҖлҘј Table 9м—җ м ңмӢңн•ҳмҳҖлӢӨ.
ліё м—°кө¬м—җм„ң м ңмӢңлҗң к°ңм„ лҗң м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқҳ к°ңм„ нҡЁкіј л°Ҹ м Ғмҡ©м„ұмқ„ кІҖнҶ н•ҳкё° мң„н•ҙ 2017л…„кіј 2018л…„м—җ м№ЁмҲҳн”јн•ҙк°Җ л°ңмғқн•ң м§Җм—ӯмқҳ CCTV мҳҒмғҒмһҗлЈҢлҘј мҲҳ집н•ҳмҳҖлӢӨ. 2017л…„м—җлҠ” л¶ҖмӮ° к°•м„ңкө¬ л…№мӮ°лҸҷм—җм„ң м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖмңјл©°, 2018л…„м—җлҠ” лҢҖм „ мң м„ұкө¬ м „лҜјлҸҷкіј м„ңкө¬ л‘”мӮ°лҸҷ, мҡёмӮ° л¶Ғкө¬ нҡЁл¬ёлҸҷм—җм„ң м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖлӢӨ. м№ЁмҲҳл°ңмғқм§Җм—ӯмқҳ CCTV мҳҒмғҒмқ„ мҲҳ집вӢ…분м„қн•ҳм—¬ м№ЁмҲҳл°ңмғқ мӢңк°„мқ„ нҷ•мқён•ҳмҳҖмңјл©°, 분м„қ кІ°кіјлҘј Table 10м—җ лӮҳнғҖлӮҙм—ҲлӢӨ.
н•ҙлӢ№м§Җм—ӯмқҳ AWS к°•мҡ°кҙҖмёЎ мһҗлЈҢлҘј нҶөн•ҙ м№ЁмҲҳл°ңмғқмӢңк°„ лӢ№мӢң м§ҖмҶҚмӢңк°„лі„ лҲ„м Ғк°•мҡ°лҹүмқ„ 분м„қн•ҳм—¬ мӢӨм ң м№ЁмҲҳл°ңмғқк°•мҡ°лҹүмқ„ мӮ°м •н•ҳмҳҖлӢӨ. мӢӨм ң м№ЁмҲҳл°ңмғқк°•мҡ°лҹүмқ„ м№ЁмҲҳмң„н—ҳкё°мӨҖмқҳ м°ёк°’мңјлЎң кё°мЎҙ лӘЁлҚёлЎң мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖкіј к°ңм„ лҗң лӘЁлҚёлЎң мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ 비көҗн•ҳм—¬ к°ңм„ нҡЁкіј л°Ҹ м Ғмҡ©м„ұмқ„ кІҖнҶ н•ҳмҳҖлӢӨ.
мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖмқҳ м •нҷ•м„ұмқ„ кІҖнҶ н•ҳкё° мң„н•ҙм„ңлҠ” мӢӨм ң м№ЁмҲҳлҘј л°ңмғқмӢңнӮЁ к°•мҡ°мқҳ м§ҖмҶҚмӢңк°„мқ„ нҷ•мқён•ҳм—¬ лҸҷмқјн•ң м§ҖмҶҚмӢңк°„м—җ лҢҖн•ҙм„ң 비көҗн•ҙм•ј н•ңлӢӨ. л”°лқјм„ң м№ЁмҲҳлҘј л°ңмғқк°•мҡ°мқҳ м§ҖмҶҚмӢңк°„мқ„ нҷ•мқён•ҳкё° мң„н•ҙ м§ҖмҶҚмӢңк°„ 1мӢңк°„, 3мӢңк°„ к°•мҡ°м—җ лҢҖн•ң л№ҲлҸ„분м„қмқ„ н•ҳмҳҖмңјл©°, л№ҲлҸ„к°Җ лҶ’мқҖ к°•мҡ°мӮ¬мғҒм—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ң кІғмңјлЎң нҢҗлӢЁн•ҳмҳҖлӢӨ. мӢӨм ңм№ЁмҲҳл°ңмғқк°•мҡ°лҹүмқҳ м§ҖмҶҚмӢңк°„лі„ л№ҲлҸ„분м„қкІ°кіјлҘј Table 11м—җ лӮҳнғҖлӮҙм—ҲлӢӨ.
л¶ҖмӮ° л…№мӮ°лҸҷмқҖ м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җ 2.4л…„ л№ҲлҸ„, 3мӢңк°„м—җ 1.8л…„ л№ҲлҸ„лЎң 43.0 mm/hr к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖмңјл©°, лҢҖм „ м „лҜјлҸҷкіј л‘”мӮ°лҸҷмқҖ 1мӢңк°„м—җ 5.5л…„, 4.2л…„ л№ҲлҸ„, 3мӢңк°„м—җ 2.9л…„, 3.2л…„ л№ҲлҸ„лЎң к°Ғк°Ғ 59.6 mm/hr, 55.9 mm/hr к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖлӢӨ. мҡёмӮ° нҡЁл¬ёлҸҷмқҖ м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җ 3.0л…„ л№ҲлҸ„, 3мӢңк°„м—җ 7.3л…„ л№ҲлҸ„лЎң 96.0 mm/3hr к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ң кІғмңјлЎң нҢҗлӢЁн•ҳмҳҖлӢӨ.
л¶ҖмӮ° л…№мӮ°лҸҷкіј лҢҖм „ м „лҜјлҸҷ, л‘”мӮ°лҸҷмқҖ м§ҖмҶҚмӢңк°„ 1мӢңк°„ к°•мҡ°, мҡёмӮ° нҡЁл¬ёлҸҷмқҖ м§ҖмҶҚмӢңк°„ 3мӢңк°„ к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ң кІғмңјлЎң нҷ•мқёлҗҳм—Ҳмңјл©°, кё°мЎҙ лӘЁлҚё мҳҲмёЎкІ°кіјмҷҖ к°ңм„ лҗң лӘЁлҚё мҳҲмёЎкІ°кіјлҘј 비көҗн•ҳм—¬ Table 12м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. л¶ҖмӮ° л…№мӮ°лҸҷмқҖ 43.0 mm/hr к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖмңјл©°, кё°мЎҙ лӘЁлҚёмқҖ 52.3 mm/hr, к°ңм„ лӘЁлҚёмқҖ 44.1 mm/hrмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳм—¬, к°ңм„ лӘЁлҚёмқҙ 19.1% к°ңм„ лҗҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
лҢҖм „ м „лҜјлҸҷмқҳ мӢӨм ң м№ЁмҲҳк°•мҡ°лҹүмқҖ 59.6 mm/hrмқҙл©°, кё°мЎҙ лӘЁлҚёмқҖ 52.9 mm/hr, к°ңм„ лӘЁлҚёмқҖ 60.2 mm/hrлЎң мҳӨм°Ёк°Җ 10.2% к°җмҶҢн•ҳмҳҖлӢӨ. лҢҖм „ л‘”мӮ°лҸҷмқҖ 55.9 mm/hr к°•мҡ°м—җ мқҳн•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖмңјл©°, кё°мЎҙ лӘЁлҚёмқҖ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳм§Җ лӘ»н•ҳмҳҖмңјлӮҳ, к°ңм„ лӘЁлҚёмқҖ 61.0 mm/hrмқ„ мҳҲмёЎн•ҳмҳҖмңјл©° 5.1 mm/hrмқҳ мҳӨм°Ёк°Җ л°ңмғқн•ҳмҳҖлӢӨ.
л§Ҳм§Җл§үмңјлЎң мҡёмӮ° нҡЁл¬ёлҸҷмқҳ мӢӨм ң м№ЁмҲҳк°•мҡ°лҹүмқҖ 96.0 mm/3hrлЎң кё°мЎҙ лӘЁлҚёмқҖ 95.3 mm/3hr, к°ңм„ лӘЁлҚёмқҖ мӢӨм ң м№ЁмҲҳк°•мҡ°лҹүкіј лҸҷмқјн•ң 96.0 mm/3hrмқ„ мҳҲмёЎн•ҳм—¬ 0.7% к°ңм„ лҗҳм—ҲлӢӨ.
л”°лқјм„ң 3к°ң кІҖнҶ м§Җм—ӯ лӘЁл‘җ кё°мЎҙ лӘЁлҚё ліҙлӢӨ к°ңм„ лӘЁлҚёмқҙ м •нҷ•н•ң кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, 1к°ң м§Җм—ӯмқҖ кё°мЎҙ лӘЁлҚём—җм„ң мҳҲмёЎн•ҳм§Җ лӘ»н•ҳмҳҖмңјлӮҳ к°ңм„ лҗң лӘЁлҚём—җм„ңлҠ” мҳҲмёЎ к°ҖлҠҘн•ң кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
7. кІ° лЎ
ліё м—°кө¬м—җм„ңлҠ” м„ н–үм—°кө¬м—җм„ң м ңмӢңлҗң мң м—ӯнҠ№м„ұкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқ„ к°ңм„ н•ҳкё° мң„н•ҙ мҙҲкё°нҷ” н•ЁмҲҳ, н•ҷмҠөмһҗлЈҢмқҳ мҲҳ, лҚ°мқҙн„° м „мІҳлҰ¬лҘј нҶөн•ҙ к°ңм„ нҡЁкіјлҘј 분м„қн•ҳм—¬ мөңм Ғ лӘЁлҚёмқ„ м ңмӢңн•ҳмҳҖлӢӨ. лҳҗн•ң н”јн•ҙмқҙл Ҙкё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м •мқҙ л¶Ҳк°ҖлҠҘн•ң м§Җм—ӯм—җ лҢҖн•ң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳмҳҖмңјл©°, мӢӨм ң м№ЁмҲҳк°•мҡ°лҹүкіј кё°мЎҙ лӘЁлҚё л°Ҹ к°ңм„ лӘЁлҚёмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎкІ°кіјлҘј 비көҗн•ҳм—¬ к°ңм„ нҡЁкіјлҘј 분м„қн•ҳкі м Ғмҡ©м„ұмқ„ кІҖмҰқн•ҳмҳҖлӢӨ.
Neuro-Fuzzy м•Ңкі лҰ¬мҰҳмқҳ мҙҲкё°нҷ” н•ЁмҲҳм—җ л”°лҘё к°ңм„ нҡЁкіјлҘј 분м„қн•ҳкё° мң„н•ҙ м„ н–үм—°кө¬м—җм„ң мӮ¬мҡ©н•ң Grid Partitionкіј Subtractive Clusteringкё°лІ•мқ„ лӘЁлҚё н•ҷмҠөмһҗлЈҢмқҳ к°ңмҲҳлі„лЎң 비көҗн•ҳмҳҖлӢӨ. Grid Partitionмқҳ кІҪмҡ° н•ҷмҠөмһҗлЈҢмқҳ мҲҳк°Җ м Ғмқ„ кІҪмҡ° м •нҷ•м„ұмқҙ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬мңјлӮҳ, лӘЁлҚём—җ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ лҜём№ҳлҠ” н•ҷмҠөмһҗлЈҢк°Җ нҸ¬н•Ёлҗң кІҪмҡ° мҳӨм°Ёк°Җ м»Өм§ҖлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. л°ҳл©ҙм—җ Subtractive Clustering л°©лІ•мқ„ мӮ¬мҡ©н•ң лӘЁлҚёмқҳ кІҪмҡ° н•ҷмҠөмһҗлЈҢк°Җ мҰқк°Җн•Ём—җ л”°лқј мҡ°мҲҳн•ң м„ұлҠҘмқ„ ліҙмқҙкі мһҲмңјл©°, нҠ№нһҲ н•ҷмҠөмһҗлЈҢмқҳ кө°м§‘нҷ”лҘј нҶөн•ҙ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ лҜём№ҳлҠ” н•ҷмҠөмһҗлЈҢк°Җ нҸ¬н•Ёлҗҳм–ҙ мһҲлҠ” кІҪмҡ°м—җлҸ„ 비көҗм Ғ м •нҷ•м„ұмқҙ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
ліё м—°кө¬м—җм„ң 분м„қлҗң кІ°кіјлҘј кё°мЎҙ лӘЁлҚё(Model A) лҢҖ비 к°ңм„ нҡЁкіјлҘј мў…н•©н•ҳм—¬ Table 13м—җ лӮҳнғҖлӮҙм—ҲлӢӨ.
м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м • лӘЁлҚёмқҳ м Ғмҡ©лІ”мң„ нҷ•мһҘ л°Ҹ м •нҷ•м„ұ к°ңм„ мқ„ мң„н•ҙ н•ҷмҠөмһҗлЈҢлҘј 추к°ҖлЎң кө¬м¶•н•ҳмҳҖмңјл©°, н•ҷмҠөмһҗлЈҢмқҳ мҲҳм—җ л”°лҘё лӘЁлҚё м •нҷ•м„ұмқ„ 비көҗн•ҳмҳҖлӢӨ. мҙҲкё°нҷ” н•ЁмҲҳлҘј Subtractive Clustering, 188к°ңмқҳ н•ҷмҠөмһҗлЈҢлҘј мӮ¬мҡ©н•ң лӘЁлҚёмқҖ м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җм„ң нҸүк· мҳӨм°Ёк°Җ мөңлҢҖ 38.6%, 3мӢңк°„м—җм„ң 45.2% к°җмҶҢн•ҳлҠ” кІғмқ„ нҷ•мқён•ҳмҳҖмңјл©°, RMSEлҸ„ к°Ғк°Ғ 38.8%, 34.3% к°җмҶҢн•ҳмҳҖлӢӨ. н•ҷмҠөмһҗлЈҢмқҳ мҲҳк°Җ мҰқк°Җн•ҳл©ҙм„ң лӘЁлҚёмқҳ м •нҷ•лҸ„к°Җ к°ңм„ лҗҳлҠ” кІғмқ„ нҷ•мқён•ҳмҳҖмңјл©°, мң м—ӯнҠ№м„ұмһҗлЈҢмқҳ м Ғмҡ© лІ”мң„лҸ„ мҰқк°Җн•ҳм—¬ лӢӨм–‘н•ң м§Җм—ӯм—җ м Ғмҡ©н• мҲҳ мһҲмқ„ кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.
л§Ҳм§Җл§үмңјлЎң лҚ°мқҙн„°мқҳ м „мІҳлҰ¬ мҰү, лӘЁлҚё н•ҷмҠөкіјм •м—җм„ң л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ мЈјлҠ” н•ҷмҠөмһҗлЈҢлҘј м ңкұ°н•ҳкё° мң„н•ҙ RanSAC м•Ңкі лҰ¬мҰҳмқ„ м Ғмҡ©н•ҳмҳҖлӢӨ. м§ҖмҶҚмӢңк°„лі„лЎң м •мғҒ분нҸ¬лҘј лІ—м–ҙлӮң н•ҷмҠө мһҗлЈҢлҘј м ңмҷён•ҳм—¬ лӘЁлҚёмқ„ кө¬м¶•н•ң кІ°кіј нҸүк· мҳӨм°ЁлҠ” м§ҖмҶҚмӢңк°„ 1мӢңк°„м—җм„ң 48.1%, 3мӢңк°„ 64.5% к°җмҶҢн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, RMSEлҸ„ к°Ғк°Ғ 50.7%, 60.1% к°җмҶҢн•ҳм—¬ к°ңм„ лӘЁлҚёмқҳ м •нҷ•лҸ„лҠ” мҰқк°Җн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
мҙҲкё°нҷ” н•ЁмҲҳлЎң Subtractive Clusteringмқ„ м Ғмҡ©н•ҳкі , 188к°ңмқҳ н•ҷмҠөмһҗлЈҢм—җ RanSAC кё°лІ•мқ„ нҶөн•ҙ мқҙмғҒм№ҳлҘј м ңкұ°н•ҳм—¬ н•ҷмҠөн•ң Model Iмқҳ м •нҷ•лҸ„к°Җ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. л”°лқјм„ң Model IлҘј нҷңмҡ©н•ҳм—¬ н”јн•ҙмқҙл Ҙмқҙ л¶ҖмЎұн•ҳм—¬ м№ЁмҲҳмң„н—ҳкё°мӨҖ м¶”м •мқҙ л¶Ҳк°ҖлҠҘн•ң м§Җм—ӯмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳмҳҖлӢӨ. мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖмқҳ к°ңм„ нҡЁкіј л°Ҹ м Ғмҡ©м„ұмқ„ нҷ•мқён•ҳкё° мң„н•ҙ мӢӨм ң м№ЁмҲҳк°Җ л°ңмғқн•ң 4к°ң м§Җм—ӯмқ„ лҢҖмғҒмңјлЎң мӢӨм ң м№ЁмҲҳл°ңмғқк°•мҡ°лҹүмқ„ мӮ°м • н•ҳмҳҖмңјл©°, кё°мЎҙлӘЁлҚёкіј к°ңм„ лӘЁлҚёмқ„ 비көҗн•ң кІ°кіј 0.7%~19.1% к°ңм„ лҗҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
ліё м—°кө¬м—җм„ң м ңмӢңлҗң мөңм Ғ лӘЁлҚё(Model I)мқ„ нҷңмҡ©н•ҳм—¬ н”јн•ҙмқҙл Ҙмқҙ м—ҶлҠ” м§Җм—ӯмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳкі , лҸ„мӢңм№ЁмҲҳ мҳҲвӢ…кІҪліҙлҘј мң„н•ң кё°мӨҖмңјлЎң мӮ¬мҡ©н•ңлӢӨл©ҙ лҸ„мӢңм№ЁмҲҳлЎң мқён•ң мқёлӘ… л°Ҹ мһ¬мӮ° н”јн•ҙм Җк°җм—җ кё°м—¬н• мҲҳ мһҲмқ„ кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ. лҳҗн•ң н–Ҙнӣ„ мӢӨм ң м№ЁмҲҳк°Җ л°ңмғқн•ң м§Җм—ӯмқ„ лҢҖмғҒмңјлЎң м№ЁмҲҳмң„н—ҳкё°мӨҖ мҳҲмёЎ кІ°кіјмҷҖ мӢӨм ңм№ЁмҲҳл°ңмғқ к°•мҡ°лҹү 비көҗлҘј нҶөн•ҙ м§ҖмҶҚм ҒмңјлЎң к°ңм„ н•ңлӢӨл©ҙ м •нҷ•н•ң лҸ„мӢңм№ЁмҲҳ мҳҲвӢ…кІҪліҙк°Җ к°ҖлҠҘн• кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.