1. ņä£ ļĪĀ
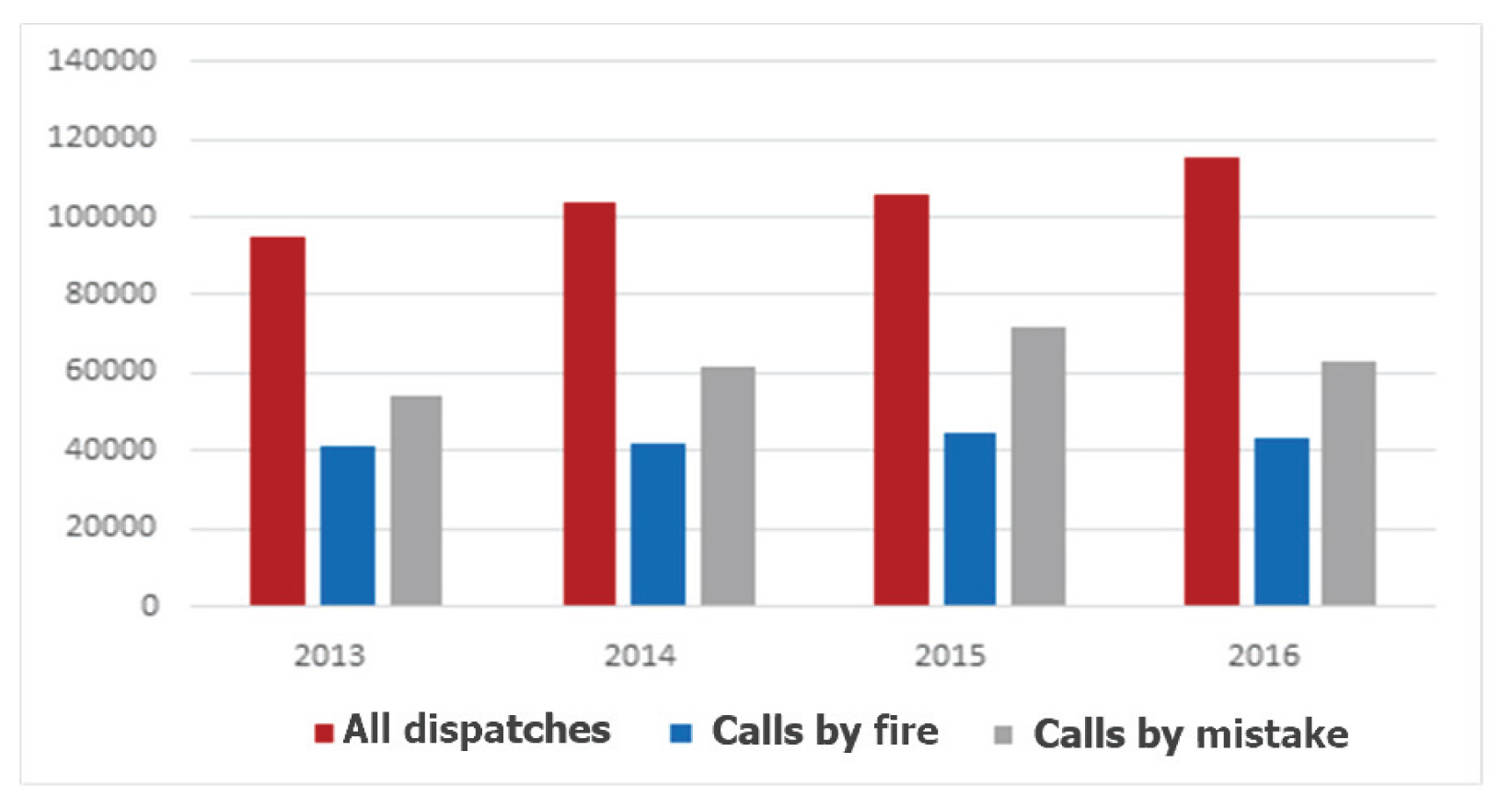
ņĄ£ĻĘ╝ ļōżņ¢┤ ļīĆĒśĢĒÖöņ×¼ņØś ļ░£ņāØ ļ╣łļÅäĻ░Ć ĻŠĖņżĆĒ׳ ņ”ØĻ░ĆĒĢśļ®░, ĒÖöņ×¼ņÖĆ ņĢłņĀäņŚÉ ļīĆĒĢ£ ĻĄŁļ»╝ņĀü Ļ┤Ćņŗ¼ņØ┤ ļåÆņĢäņ¦ĆĻ│Ā ņ׳ļŗż. ņ¦Ćļé£ ņé¼ļĪĆļĪ£ļŖö 2017ļģä 12ņøö ņĀ£ņ▓£ ņŖżĒżņĖĀņä╝Ēä░ ĒÖöņ×¼ļĪ£ 29ļ¬ģņØ┤ ņé¼ļ¦ØĒĢśĻ│Ā 40ļ¬ģņØ┤ ļČĆņāüļŗ╣ĒĢśņśĆņ£╝ļ®░, 2018ļģä 1ņøö Ļ▓Įļé© ļ░Ćņ¢æ ņäĖņóģļ│æņøÉ ĒÖöņ×¼ļĪ£ 150ņŚ¼ ļ¬ģņØ┤ ņé¼ņāüĒĢśļŖö ļō▒ ņØĖļ¬ģĒö╝ĒĢ┤Ļ░Ć ļŗżņłś ļ░£ņāØĒĢśņśĆļŗż. ĒŖ╣Ē׳ ĒÖöņ×¼ļ░£ņāØ ņŗ£ Ļ│©ļōĀĒāĆņ×äņØä ņ¦ĆĒéżļŖö Ļ▓āņØĆ ļ¦żņÜ░ ņżæņÜöĒĢ£ ņÜöņåīļĪ£ ņĀüņÜ®ļÉśņ¦Ćļ¦ī ņĄ£ĻĘ╝ ņØĖļ¬ģĒö╝ĒĢ┤Ļ░Ć ļ░£ņāØĒĢ£ ĒÖöņ×¼ ņé¼ļĪĆņŚÉņä£ļŖö ņŖżĒöäļ¦üĒü┤ļ¤¼Ļ░Ć ņ×æļÅÖĒĢśņ¦Ć ņĢŖĻ▒░ļéś ņ┤łĻĖ░ ņŗĀĻ│Ā ļ░Å ļīĆņØæņØ┤ ļŖ”ņ¢┤ņĀĖ ļīĆĒśĢĒÖöņ×¼ļĪ£ ņØ┤ņ¢┤ņĪīļŗżļŖö Ļ│ĄĒåĄņĀÉņØ┤ ņ׳ļŗż. ļśÉĒĢ£ ņŚ¼ļ”äņ▓Ā ņŚ┤Ļ░Éņ¦ĆĻĖ░ņØś ņśżņ×æļÅÖ ļ░Å ĒÖöņ×¼ņłśņŗĀļ░śņŚÉ ļīĆĒĢ£ Ļ┤Ćļ”¼ņ×ÉņØś ņØśņŗØ ļČĆņĪ▒ņ£╝ļĪ£ ņØĖĒĢśņŚ¼ ĒÖöņ×¼ņłśņŗĀĻĖ░ļź╝ Ļ║╝ļåōļŖö ņé¼ļĪĆĻ░Ć ļ╣łļ▓łĒ׳ ļ░£ņāØĒĢśĻ│Ā ņ׳ļŗż. Fig. 1ņØś Ļ▓ĮņÜ░ ņåīļ░®ņ▓ŁņŚÉņä£ Ļ│ĄĻ░£ĒĢ£ 2013ļģäļČĆĒä░ 2016ļģäĻ╣īņ¦Ć ĒÖöņ×¼ ņČ£ļÅÖ Ļ▒┤ņłśņÖĆ ņśżņØĖņČ£ļÅÖ Ļ▒┤ņłśļź╝ ļ│┤ņŚ¼ņŻ╝Ļ│Ā ņ׳ļŖöļŹ░ ļ¦żĒĢ┤ ĻĘĖ ļ░£ņāØ Ļ▒┤ņłśĻ░Ć ņ”ØĻ░ĆĒĢśĻ│Ā ņ׳ļŖö ņČöņäĖņØ┤ļ®░, ĒŖ╣Ē׳ ĒÖöņ×¼ ņČ£ļÅÖ Ļ▒┤ņłśņŚÉ ļ╣äĒĢ┤ ņśżņØĖņČ£ļÅÖ Ļ▒┤ņłśņØś ņ”ØĻ░Ć ĒÅŁņØ┤ ļŹö Ēü░ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż. ļśÉĒĢ£ ņĀäņ▓┤ ņČ£ļÅÖ Ļ▒┤ņłś ņżæņŚÉ 60% ņĀĢļÅäĻ░Ć ņśżņØĖņČ£ļÅÖņ£╝ļĪ£ ņĀĢņ×æ ņåīļ░®ļĀźņØä ĒĢäņÜöļĪ£ ĒĢśļŖö ĒśäņןņŚÉ ņČ£ļÅÖĒĢśņ¦Ć ļ¬╗ĒĢśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ░£ņāØĒĢĀ ņłś ņ׳ļŗż. ļö░ļØ╝ņä£ Ļ░Éņ¦ĆĻĖ░ņØś ņśżņ×æļÅÖņØä ņżäņØ┤Ļ│Ā ĒÖöņ×¼ņŗ£ ĒÖöņ×¼Ļ░Éņ¦ĆĻĖ░ņØś ĻĖ░ļŖźņØä ņĀĢņāüņĀüņ£╝ļĪ£ ļ░£Ē£śĒĢĀ ņłś ņ׳ļÅäļĪØ ņ£Āņ¦ĆĻ┤Ćļ”¼ņÖĆ ņĀÉĻ▓ĆņØ┤ ņĀĢĒÖĢĒĢśĻ▓ī ņØ┤ļŻ©ņ¢┤ņĀĖņĢ╝ ĒĢśņ¦Ćļ¦ī, ņŗżņĀ£ ĒÖöņ×¼ļ░£ņāØņŗ£ ņŚ░ĻĖ░Ļ░Éņ¦ĆĻĖ░ņØś ņ×æļÅÖņ¦ĆņŚ░ ļ░Å ļČĆņ×æļÅÖ ļō▒ ņŗĀļó░ņä▒ ņĀĆĒĢśļĪ£ ņØĖĒĢśņŚ¼ ņØĖļ¬ģ ļ░Å ņ×¼ņé░ Ēö╝ĒĢ┤Ļ░Ć ņżäņ¢┤ļōżņ¦Ć ņĢŖĻ│Ā ņ׳ļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņØ┤ļ¤¼ĒĢ£ ĻĖ░ņĪ┤ Ļ░Éņŗ£ņŗ£ņŖżĒģ£ņØ┤ Ļ░¢Ļ│Ā ņ׳ļŖö ņŗĀļó░ņä▒ ļ░Å ņåŹņØæņä▒ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻ│Āņ×É ņśüņāü ņĀäņ▓śļ”¼ ļ░Å ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØä ņØ┤ņÜ®ĒĢ£ ĒÖöņ×¼Ļ░Éņ¦Ć ņĀæĻĘ╝ļ░®ļ▓ĢņØä ĻĄ¼ņāüĒĢśņśĆļŗż. ņØ┤ļĢī ĒÖöņ×¼ ņØ┤ļ»Ėņ¦Ćļź╝ ĒÖöņŚ╝, ņŚ░ĻĖ░, ņŚ░ļ¼┤ ņäĖ Ļ░Ćņ¦ĆļĪ£ ļéśļłäņ¢┤ņä£ ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢ£ļŗż. ĻĘĖļ”¼Ļ│Ā ņØ┤ļĀćĻ▓ī ĒĢÖņŖĄļÉ£ ļ¬©ļŹĖņŚÉ ļīĆĒĢ┤ ĒģīņŖżĒŖĖ ņśüņāüņ£╝ļĪ£ļČĆĒä░ ņśüņāü ņĀäņ▓śļ”¼Ļ│╝ņĀĢņØä Ļ▒░ņ│É ņśüņāü ļé┤ņŚÉņä£ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ ņśüņŚŁņØä Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņŚ¼ ĒÖöņ×¼ ņŚ¼ļČĆņŚÉ ļīĆĒĢ┤ ņČöļĪĀĒĢśĻ▓ī ļÉ£ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ ĒÖöņ×¼ ņŗ£ ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ļź╝ Ļ░Éņ¦ĆĒĢśĻ▓ī ļÉśĻ│Ā, ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉ£ ņŗżļé┤ ņØ┤ļ»Ėņ¦Ćļź╝ ĒĢÖņŖĄĒĢ£ ļ¬©ļŹĖņØĆ ņŗżļé┤ ņĀäņ▓┤ ņśüņŚŁņŚÉ ļīĆĒĢ┤ ņŚ░ļ¼┤ ĒśĢņä▒ ņŚ¼ļČĆļź╝ Ļ░Éņ¦ĆĒĢĀ ņłś ņ׳ļÅäļĪØ ĒĢ©ņ£╝ļĪ£ņŹ© ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ņØś ņøĆņ¦üņ×äĻ│╝ ļŗ¼ļ”¼ Ļ░Øņ▓┤ļź╝ Ļ░Éņ¦ĆĒĢśĻĖ░ ņ¢┤ļĀżņÜ┤ ņŚ░ļ¼┤ ĒśĢĒā£ņØś ĒÖöņ×¼Ļ░Ć ļ░£ņāØĒĢśņŚ¼ļÅä ĒÖöņ×¼ļź╝ Ļ░Éņ¦ĆĒĢĀ ņłś ņ׳ļÅäļĪØ ĒĢśņśĆļŗż.
2. ĻĖ░ņĪ┤ ĒÖöņ×¼Ļ░Éņ¦ĆĻĖ░ ļ░Å ņ╗┤Ēō©Ēä░ ļ╣äņĀäļČäņĢ╝ņŚÉņä£ņØś Ļ┤ĆļĀ© ņŚ░ĻĄ¼ļÅÖĒ¢ź
Ēśäņ×¼ ņØ╝ļ░śņĀüņ£╝ļĪ£ ņé¼ņÜ®ĒĢśļŖö ĒÖöņ×¼Ļ░Éņ¦ĆĻĖ░ļŖö Ēü¼Ļ▓ī 3Ļ░Ćņ¦ĆļĪ£ ņŚ┤Ļ░Éņ¦ĆĻĖ░ņÖĆ ņŚ░ĻĖ░Ļ░Éņ¦ĆĻĖ░ ĻĘĖļ”¼Ļ│Ā ļČłĻĮāĻ░Éņ¦ĆĻĖ░Ļ░Ć ņ׳ļŗż. ņŚ┤Ļ░Éņ¦ĆĻĖ░ņØś Ļ▓ĮņÜ░ ļīĆĒæ£ņĀüņ£╝ļĪ£ ņ░©ļÅÖņŗØņŖżĒżĒŖĖĒśĢĻ░Éņ¦ĆĻĖ░Ļ░Ć ņé¼ņÜ®ļÉśĻ│Ā ņ׳ņ£╝ļ®░, ĻĖēĻ▓®ĒĢ£ ņś©ļÅä ņāüņŖ╣ ņŗ£ ņ×æļÅÖĒĢśļŖö Ļ▓āņ£╝ļĪ£ ņØ╝ĻĄŁņåīņŚÉņä£ņØś ņŚ┤ĒÜ©Ļ│╝ņŚÉ ņØśĒĢ┤ ņ×æļÅÖļÉśļŖö Ļ░Éņ¦ĆĻĖ░ņØ┤ļŗż. ņ░©ļÅÖņŗØņØĆ ņÖäļ¦īĒĢ£ ņś©ļÅä ņāüņŖ╣ ņŗ£ ņ×æļÅÖĒĢśņ¦Ć ņĢŖĻĖ░ ļĢīļ¼ĖņŚÉ ļ╣äĒÖöņ×¼ļ│┤ ļ░®ņ¦Ć ĻĖ░ļŖźņØ┤ ņ׳ņ¦Ćļ¦ī ĒøłņåīĒÖöņ×¼ņŚÉ ņĀüņØæņä▒ņØ┤ ņŚåļŗżļŖö ļŗ©ņĀÉņØ┤ ņ׳ļŗż.
ņŚ░ĻĖ░Ļ░Éņ¦ĆĻĖ░ņØś Ļ▓ĮņÜ░ ļīĆĒæ£ņĀüņ£╝ļĪ£ Ļ┤æņĀäņŗØņŚ░ĻĖ░Ļ░Éņ¦ĆĻĖ░Ļ░Ć ņé¼ņÜ®ļÉśĻ│Ā ņ׳ņ£╝ļ®░, ļ╣øņØä ļ░£ĒĢśļŖö ņåĪĻ┤æļČĆņÖĆ ņØ┤ļź╝ ņłśņŗĀĒĢśļŖö ņłśĻ┤æļČĆļĪ£ ĻĄ¼ņä▒ļÉśņ¢┤ņ׳ļŗż. ļ╣øņØś Ļ░Éņćä ņøÉļ”¼ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļäōņØĆ Ļ│ĄĻ░äņØ┤ļéś ĻĖ┤ Ļ│ĄĻ░äņŚÉ ņé¼ņÜ®ĒĢśĻĖ░ ņĀüĒĢ®ĒĢśĻ│Ā, ņØ╝ņŗ£ņĀüņØĖ ņŚ░ĻĖ░ ļō▒ņŚÉ ļÅÖņ×æĒĢśņ¦Ć ņĢŖņĢä ļ╣äĒÖöņ×¼ļ│┤ ļ░®ņ¦Ć ĒÜ©Ļ│╝Ļ░Ć ņ׳ņ¦Ćļ¦ī ĒŖ╣ņłśņןņåīņŚÉ ņäżņ╣śļÉśņ¢┤ ņ£Āņ¦ĆĻ┤Ćļ”¼ņŚÉ ņ¢┤ļĀżņøĆņØ┤ ņ׳ņ£╝ļ®░, ļ░£Ļ┤æļČĆ ļ░Å ņłśĻ┤æļČĆņØś ņśżņŚ╝ ņŗ£ ļ╣äĒÖöņ×¼ļ│┤ņØś ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢĀ ņłś ņ׳ļŗż.
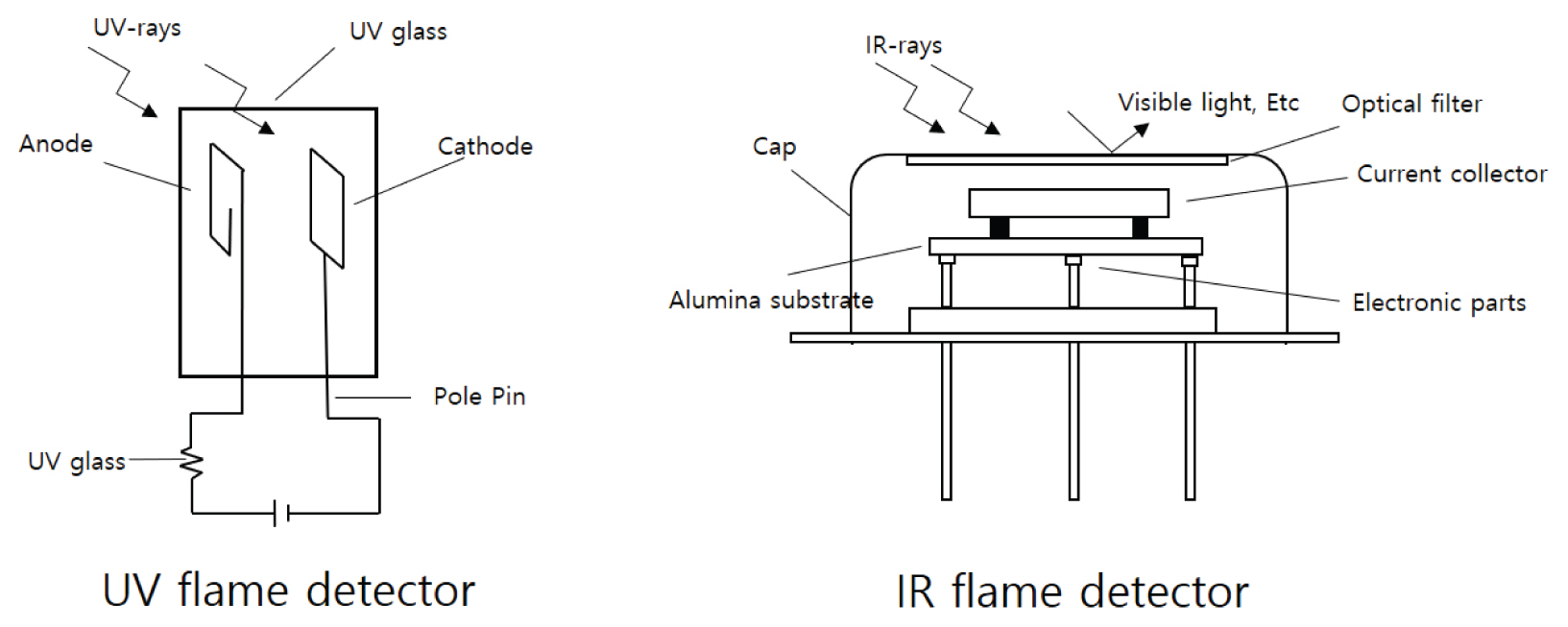
ļČłĻĮāĻ░Éņ¦ĆĻĖ░ļŖö Fig. 2ņÖĆ Ļ░ÖņØ┤ ņ×ÉņÖĖņäĀ(ultra violet, UV)Ļ│╝ ņĀüņÖĖņäĀ(infra red, IR) Ļ░Éņ¦Ćļ░®ņŗØņ£╝ļĪ£ ļéśļłäņ¢┤ņ¦Ćļ®░ ņ×ÉņÖĖņäĀļČłĻĮā Ļ░Éņ¦ĆĻĖ░ņØś Ļ▓ĮņÜ░ 0.09~0.38 ŃÄøņØś ļ░®ņé¼ņŚÉļäłņ¦Ćļź╝ Ļ▓ĆņČ£ĒĢśļŖö Ļ░Éņ¦ĆĻĖ░ļĪ£ ļ¼╝ņ▓┤ņŚÉ ļ╣øņØ┤ ņĪ░ņé¼ļÉĀ ļĢī ņŚ¼ĻĖ░ņĀäņ×É(excitation electron)ļź╝ ņ¦äĻ│Ą ņżæņ£╝ļĪ£ ļ░®ņČ£ņŗ£ĒéżļŖö Ļ┤æņĀäņ×É ļ░®ņé¼ ņøÉļ”¼ļź╝ ņØ┤ņÜ®ĒĢ£ļŗż. ĒĢśņ¦Ćļ¦ī ņ×ÉņÖĖņäĀļ░®ņŗØņØś ļČłĻĮāĻ░Éņ¦ĆĻĖ░ļŖö ĒīīņןņØ┤ ņ¦¦ņØĆ ņ×ÉņÖĖņäĀņØä Ļ░Éņ¦ĆĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņŚ░ĻĖ░ļéś Ļ│ĄĻĖ░ ņżæ ļČĆņ£Āļ¼╝ņŚÉ ņØśĒĢ┤ņä£ļÅä ņ×ÉņÖĖņäĀņØ┤ ĒØĪņłśļÉśļ»ĆļĪ£ Ļ░ÉļÅäņŚÉ ļīĆĒĢ£ ņŗĀļó░ņä▒ņØ┤ ļ¢©ņ¢┤ņ¦ĆļŖö ļ¼ĖņĀ£ņĀÉņØ┤ ņ׳ļŗż. ļśÉĒĢ£ ņĢäĒü¼, ņŖżĒīīĒü¼ ļō▒ ļŗ©ĒīīņןņŚÉ ļ╣äĒÖöņ×¼ļ│┤Ļ░Ć ļ░£ņāØĒĢĀ ņłś ņ׳Ļ│Ā, ņŚ░ĻĖ░ ļåŹļÅäĻ░Ć ļåÆņØäņłśļĪØ ļÅÖņ×æņŚÉ ņ¢┤ļĀżņøĆņØ┤ ņ׳ļŗż.
ņĀüņÖĖņäĀļČłĻĮāĻ░Éņ¦ĆĻĖ░ņØś Ļ▓ĮņÜ░ļŖö 0.78~5 ŃÄøņØś ļ│Ąņé¼ņŚÉļäłņ¦Ćļź╝ Ļ░Éņ¦ĆĒĢśņŚ¼ ļÅÖņ×æĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£ Ļ░Éņ¦Ćņä╝ņä£ļĪ£ ņ┤łņĀäņ▓┤ļź╝ ļ¦ÄņØ┤ ņé¼ņÜ®ĒĢ£ļŗż. Ļ┤æĒĢÖ ĒĢäĒä░ļź╝ ņé¼ņÜ®ĒĢśļŖö Ļ▓ĮņÜ░ ņŚ░ņåīņāØņä▒ļ¼╝ņØś ņØ┤ņé░ĒÖöĒāäņåīņŚÉņä£ ļ░£ņāØĒĢśļŖö 4.4 ŃÄø ļČĆĻĘ╝ņØś ņØ┤ņé░ĒÖöĒāäņåī Ļ│Ąļ¬ģļ░®ņé¼ļź╝ ņØ┤ņÜ®ĒĢ£ļŗż. ļö░ļØ╝ņä£ ĻĖ┤ ĒīīņןļīĆļź╝ ņØ┤ņÜ®ĒĢśļŖö ĒŖ╣ņä▒ņ£╝ļĪ£ ņØĖĒĢśņŚ¼ Ļ│ĄĻĖ░ ņżæ ļČĆņ£Āļ¼╝ņŚÉ ļīĆĒĢ┤ Ļ▒░ņØś ņśüĒ¢źņØä ļ░øņ¦Ć ņĢŖļŖö ņןņĀÉņØ┤ ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ļ░śļīĆļĪ£ ņØ┤ņé░ĒÖöĒāäņåīĻ░Ć ļ░£ņāØĒĢśņ¦Ć ņĢŖļŖö ĒÖöņ×¼ ņŗ£ņŚÉļŖö ļ╣ä ņĀüņØæņä▒ņØä Ļ░¢Ļ│Ā ņ׳ļŗż. ņØ┤ņÖĖņŚÉļÅä ņśżļ│┤ļź╝ ņżäņØ┤ĻĖ░ņ£äĒĢ£ UV/IR Ēś╝ĒĢ®ĒśĢ ļČłĻĮāĻ░Éņ¦ĆĻĖ░Ļ░Ć ņĪ┤ņ×¼ĒĢśņ¦Ćļ¦ī ņ×ÉņÖĖņäĀ ļ░®ņŗØņØś ļŗ©ņĀÉņØĖ ņśżņŚ╝ņ£╝ļĪ£ļČĆĒä░ ņĢĮĒĢśļŗżļŖö ļ¼ĖņĀ£Ļ░Ć Ļ░£ņäĀļÉśņ¢┤ņĢ╝ ĒĢ£ļŗż. ļö░ļØ╝ņä£ ņĄ£ĻĘ╝ņŚÉļŖö 3Ļ░Ćņ¦Ć ĒīīņןņØä Ļ░Éņ¦ĆĒĢśļŖö ņä╝ņä£ļź╝ ņןņ░®ĒĢ£ IR3ņä╝ņä£ļź╝ ņé¼ņÜ®ĒĢśĻ│Ā ņ׳Ļ│Ā, ņóĆ ļŹö ņŗĀļó░ņä▒ Ļ░£ņäĀņØä ņ£äĒĢ┤ IR4, IR5 ļō▒Ļ│╝ Ļ░ÖņØĆ ĒśĢĒā£ļĪ£ļÅä ņĀ£ņ×æņØ┤ Ļ░ĆļŖźĒĢśņ¦Ćļ¦ī ļ╣äņÜ®ņØś ļ¼ĖņĀ£Ļ░Ć ņ׳ļŗż(Baek, 2014).
ņØ┤ļ¤¼ĒĢ£ ĻĖ░ņĪ┤ņØś ĒÖöņ×¼Ļ░Éņ¦Ć ņŗ£ņŖżĒģ£ņØś ĒĢ£Ļ│äļź╝ ļ│┤ņÖäĒĢśĻ│Āņ×É ņ╗┤Ēō©Ēä░ ļ╣äņĀäļČäņĢ╝ņŚÉņä£ņØś ĒÖöņ×¼Ļ░Éņ¦ĆņŚÉ Ļ┤ĆĒĢ£ ĻĖ░ņĪ┤ņŚ░ĻĄ¼ļĪ£ļŖö Wang et al. (2016)ņØ┤ ņŚ░ĻĄ¼ ļ░£Ēæ£ĒĢ£ Ļ┤æĒĢÖ ĒØÉļ”ä(optical flow)Ļ│╝ ņØ┤ļ»Ėņ¦ĆņØś ņ¦łĻ░É ĒŖ╣ņä▒ņŚÉ ĻĖ░ņ┤łĒĢ£ ĒÖöņ×¼ņŚ░ĻĖ░ Ļ░Éņ¦Ć ņĢīĻ│Āļ”¼ņ”śņØä ņĀ£ņĢłĒĢśņśĆļŗż. ņśüņāüņŚÉ ļīĆĒĢ┤ Ļ░ĆņÜ░ņŗ£ņĢł Ēś╝ĒĢ® ļ¬©ļŹĖļ¦ü(Gaussian mixture model)Ļ│╝ ļ░░Ļ▓Įņ░©ļČäņØä ĒåĄĒĢ┤ ņ£ĀļÅÖĒĢśļŖö ļ¼╝ņ▓┤ļź╝ Ļ▓ĆņČ£Ēøäļ│┤ļĪ£ ņČöņČ£ĒĢśĻ▓ī ļÉśĻ│Ā, ņØ┤ļ¤¼ĒĢ£ ņŚ░ĻĖ░ ĒŖ╣ņä▒ņČöņČ£ņØä ĒåĄĒĢ┤ ņŚ░ņé░ļČĆĒĢśļź╝ Ēü¼Ļ▓ī Ļ░Éņåīņŗ£Ēé¼ ņłś ņ׳Ļ▓ī ļÉśņŚłļŗż. ļśÉĒĢ£ Ļ▓ĆņČ£ļÉ£ Ēøäļ│┤ņśüņŚŁņŚÉ ļīĆĒĢ┤ Local binary pattern (LBP) ļ░Å Local binary pattern variance (LBPV) ĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ĒĢ┤ļŗ╣ ņśüņŚŁņØś ņ¦łĻ░É ĒŖ╣ņä▒ņØä ņČöņČ£ĒĢśĻ│Ā, ņØ┤ļ»Ėņ¦Ć Ēö╝ļØ╝ļ»Ėļō£ņŚÉ ĻĖ░ņ┤łĒĢ£ Ļ┤æĒĢÖ ĒØÉļ”äĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ņøĆņ¦üņ×ä ĒŖ╣ņä▒ņØä ņČöņČ£ĒĢśĻ▓ī ļÉ£ļŗż. ņØ┤ļĀćĻ▓ī ņČöņČ£ļÉ£ ļæÉ Ļ░Ćņ¦Ć ĒŖ╣ņä▒ņØä ņĄ£ņóģņĀüņ£╝ļĪ£ Support vector machine (SVM)ņØä ĒåĄĒĢ┤ ņŚ░ĻĖ░ņØĖņ¦Ć ĒīÉļŗ©ĒĢśĻ▓ī ļÉ£ļŗż.
ļśÉ ļŗżļźĖ ņŚ░ĻĄ¼ļĪ£ Kong et al. (2016)ņØ┤ ļ░£Ēæ£ĒĢ£ ņśüņāü ļé┤ņŚÉņä£ ņāēņāüņØś ņä▒ļČäļ╣äņ£©Ļ│╝ ņøĆņ¦üņ×ä ĒŖ╣ņä▒ņØä ņĀüņÜ®ĒĢ┤ ĒÖöņ×¼ļź╝ Ļ▓ĆņČ£ĒĢśļŖö ņŚ░ĻĄ¼ļź╝ ĒĢśņśĆļŗż. ņśüņāü ņØ┤ļ»Ėņ¦ĆņØś YCbCr ņāēĻ│ĄĻ░äņØś ņāēņāü ņä▒ļČäļ╣äņ£©ņØä ļĪ£ņ¦ĆņŖżĒŗ▒ ĒÜīĻĘĆļČäņäØņØä ĒåĄĒĢ┤ ĒÖöņ×¼ņØ╝ ĒÖĢļźĀņØä ļČäņäØĒĢśĻ│Ā ņäżņĀĢļÉ£ ņ×äĻ│äĻ░ÆņØä ļäśĻ▓ī ļÉĀ Ļ▓ĮņÜ░ ĒÖöņ×¼ļĪ£ ļČäļźśĒĢśļŖö ļ░®ļ▓ĢņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņØ┤ ļ¬©ļŹĖņØĆ ĒÖöņ×¼ļ░£ņāØ Ēøä ĒÅēĻĘĀ ĒāÉņ¦Ćņŗ£Ļ░äņØ┤ 1.81ņ┤ł ņĀĢļÅäļĪ£ ļ╣Āļź┤Ļ│Ā ĻĖ░ņĪ┤ņŚÉ ņŚ░ĻĄ¼ļÉ£ ņ╗┤Ēō©Ēä░ ļ╣äņĀäļČäņĢ╝ņŚÉņä£ņØś ĒÖöņ×¼Ļ░Éņ¦Ć ļ¬©ļŹĖļōżļ│┤ļŗż Ļ░Éņ¦ĆņåŹļÅäļīĆļ╣ä ņśżņ×æļÅÖļ╣äņ£©ņØ┤ ņāüļŗ╣Ē׳ ņżäņ¢┤ļōżņŚłļŗż.
3. ņØ┤ļĪĀņĀü ļ░░Ļ▓Į
3.1 ĻĖ░Ļ│äĒĢÖņŖĄ ņĢīĻ│Āļ”¼ņ”ś
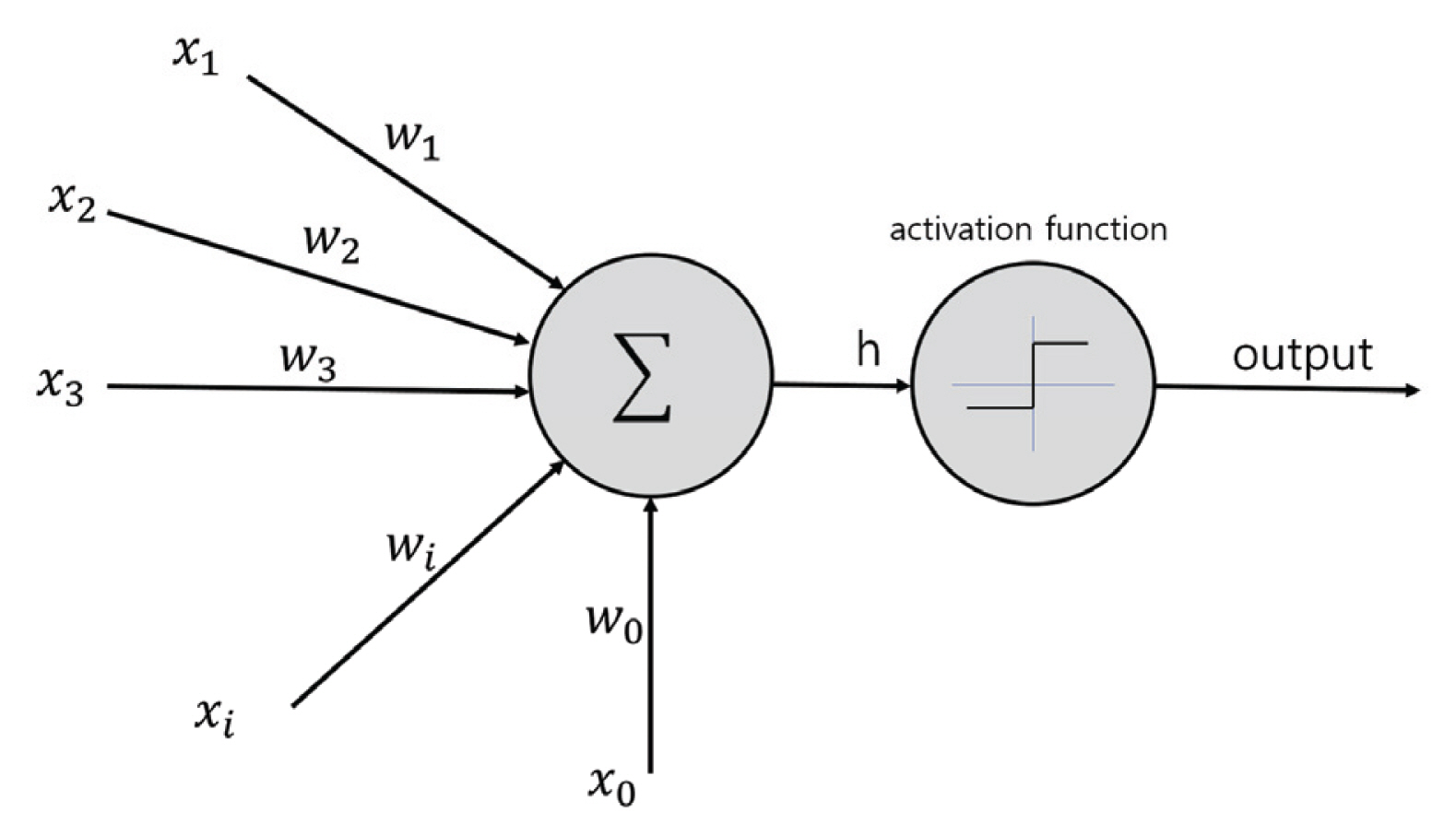
ĒŹ╝ņģēĒŖĖļĪĀņØĆ ļÅÖļ¼╝ņØś ļē┤ļ¤░ņØä ļ│Ėļ¢Ā ļ¦īļōĀ ņØ┤ļĪĀņ£╝ļĪ£ ļŗżņłśņØś ņŗĀĒśĖļź╝ ņ×ģļĀźļ░øņĢä ņØ╝ņĀĢ ņ×äĻ│äĻ░ÆņŚÉ ņØśĒĢ£ ĒĢśļéśņØś ņČ£ļĀźņŗĀĒśĖļź╝ ļé┤ļ│┤ļéĖļŗż. Fig. 3ņØä ĒåĄĒĢ┤ ĒŹ╝ņģēĒŖĖļĪĀņØś ļÅÖņ×æņØä ņäżļ¬ģĒĢśļ®┤ ļ©╝ņĀĆ ņ×ģļĀźĻ░Æ(x1, x2, x3, ..., xn)Ļ│╝ Ļ░ĆņżæĻ░Æ(w1, w2;, w3, ..., wn)ņØä ņÜöņåīļ│äļĪ£ Ļ│▒ĒĢ£ Ļ░ÆļōżņØś ĒĢ®ņØĖ hļź╝ ņĢäļלņØś Eq. (1)Ļ│╝ Ļ░ÖņØ┤ Ļ│äņé░ĒĢ£ļŗż.
ļŗżņØīņ£╝ļĪ£ ĒÖ£ņä▒ĒÖöĒĢ©ņłś(activation function)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņČ£ļĀźĻ░ÆņØä ĻĄ¼ĒĢśĻ▓ī ļÉśĻ│Ā, Eq. (2)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ hļź╝ ņ×äĻ│äĻ░Æ(╬Ė)Ļ│╝ ļ╣äĻĄÉĒĢśņŚ¼ ņ×äĻ│äĻ░ÆņØä ļäśņØä Ļ▓ĮņÜ░ ņČ£ļĀźĻ░ÆņØ┤ ĒÖ£ņä▒ĒÖöļÉśĻ▓ī ļÉ£ļŗż.
ņØ┤ļ¤¼ĒĢ£ ĒŹ╝ņģēĒŖĖļĪĀņØś ļÅÖņ×æ ņøÉļ”¼ļŖö ļ©╝ņĀĆ ņ┤łĻĖ░ Ļ░ĆņżæĻ░ÆņØä 0 ļśÉļŖö ņ×äņØśņØś ņ×æņØĆ ņł½ņ×ÉļĪ£ ņ┤łĻĖ░ĒÖöĒĢśņŚ¼ ņŗ£ņ×æĒĢ£ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ ņČ£ļĀźļÉśļŖö ļ¬©ļŹĖņØś Ļ░Ćņäż Ļ░ÆĻ│╝ ņŗżņĀ£ ņĀĢļŗĄ ņé¼ņØ┤ņØś ņåÉņŗżņØä Ļ│äņé░ĒĢśņŚ¼ ņĄ£ņóģņĀüņ£╝ļĪ£ ņśżņ░©ņŚÉ ļö░ļźĖ ņåÉņŗżņØ┤ ņ×æņĢäņ¦ĆļŖö ļ░®Ē¢źņ£╝ļĪ£ ņłśļĀ┤(convergence)ĒĢśĻ▒░ļéś ņĄ£ļīĆ ļ░śļ│Ą ņłśņŚÉ ļÅäļŗ¼ĒĢĀ ļĢīĻ╣īņ¦Ć Ļ░ĆņżæĻ░ÆņØä ņŚģļŹ░ņØ┤ĒŖĖĒĢśļŖö Ļ│╝ņĀĢņØä ļ░śļ│ĄĒĢ£ļŗż.
ĻĖ░Ļ│äĒĢÖņŖĄņØĆ ĻĖ░ņĪ┤ņØś ļ¬ģņŗ£ņĀü ĒöäļĪ£ĻĘĖļלļ░Ź(limitations of explicit programming)ņ£╝ļĪ£ ņśłņĖĪĒĢśĻĖ░ ĒלļōĀ ĒĢ£Ļ│äļź╝ ĻĘ╣ļ│ĄĒĢĀ ņłś ņ׳ņŚłņ£╝ļ®░, ĻĖ░Ļ│ä ņŖżņŖżļĪ£ ļ¦ÄņØĆ ļŹ░ņØ┤Ēä░ļĪ£ļČĆĒä░ Ēī©Ēä┤ ļČäņäØņØä ĒåĄĒĢ┤ ļČäļźśļéś ĒÜīĻĘĆ, ĻĄ░ņ¦æ ĒĢÖņŖĄņØä ĒĢśĻ▓ī ļÉśņŚłļŗż(Tang, 2015; Lim, 2017).
3.2 ļöźļ¤¼ļŗØ
ļöźļ¤¼ļŗØņØĆ ņ╗┤Ēō©Ēä░Ļ░Ć ņŖżņŖżļĪ£ ļ░śļ│Ą ĒĢÖņŖĄņØä ĒåĄĒĢ┤ ļŹ░ņØ┤Ēä░ļź╝ ņĀĢņØśĒĢśļŖö ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø(artificial neural network, ANN) ĻĖ░ļ░śņØś ĻĖ░Ļ│äĒĢÖņŖĄ ļČäņĢ╝ ņżæ ĒĢśļéśņØ┤ļŗż. ņŗĀĻ▓Įļ¦Ø Ļ│äņĖĄņØ┤ ļŗżņĖĄĻĄ¼ņĪ░ļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņŗ¼ņĖĄņŗĀĻ▓Įļ¦Ø(deep neural network, DNN)ņØ┤ļØ╝Ļ│ĀļÅä ĒĢśļ®░, ņ×ģļĀźņĖĄ(input layer)Ļ│╝ ņČ£ļĀźņĖĄ(output layer) ņé¼ņØ┤ņŚÉļŖö ĒĢ£ Ļ░£ ņØ┤ņāüņØś ņØĆļŗēņĖĄ(hidden layer)ņØä ĒżĒĢ©ĒĢ£ļŗż. ņØ╝ļ░śņĀüņØĖ ņŗ¼ņĖĄņŗĀĻ▓Įļ¦ØņØś ņśłņŗ£ļŖö Fig. 4ņÖĆ Ļ░Öļŗż.
Ļ│╝Ļ▒░ņØś ļöźļ¤¼ļŗØņØĆ Ļ│╝ņĀüĒĢ®(overfitting)ļ¼ĖņĀ£ļéś ĒĢÖņŖĄ ņŚ░ņé░ņŚÉ ĒĢäņÜöĒĢ£ ļ¦ÄņØĆ ņŗ£Ļ░ä ļō▒ņ£╝ļĪ£ ņØĖĒĢ┤ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ņĖĄņØä Ļ╣ŖĻ▓ī ņīōĻĖ░ņŚÉļŖö ļ╣äņÜ®ņĀü ņĀ£ņĢĮņØ┤ ņ╗ż ĒÖ£ņÜ®ļÅäĻ░Ć ļåÆņ¦Ć ņĢŖņĢśņ£╝ļéś, Ēśäņ×¼ļŖö ĒĢśļō£ņø©ņ¢┤ņØś ņä▒ļŖźļīĆļ╣ä Ļ░ĆĻ▓®ĒĢśļØĮĻ│╝ ĻĘĖļלĒöĮņ▓śļ”¼ņןņ╣śņØś ļ│æļĀ¼ņ▓śļ”¼ ĻĖ░ļ▓ĢņØś Ļ░£ļ░£ņØä ĒåĄĒĢ┤ ņŗ¼ņĖĄņŗĀĻ▓Įļ¦ØĒśĢĒā£ņØś Ļ╣ŖņØĆ ĒĢÖņŖĄņØä ņŗżĒ¢ēĒĢśĻĖ░ņŚÉ ņÜ®ņØ┤ĒĢ┤ņĪīļŗż.
ĒŖ╣Ē׳ ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ņÖĆ Ļ░ÖņØ┤ ņ╗┤Ēō©Ēä░ ļ╣äņĀäļČäņĢ╝ņŚÉņä£ņØś ņĀüņÜ®ņØä ņ£äĒĢ┤ ņśüņāü ļ░Å ņØ┤ļ»Ėņ¦ĆļĪ£ļČĆĒä░ ņĀäņ▓śļ”¼ ļČäņäØ ļ░Å ĒĢÖņŖĄņØä ņ£äĒĢ┤ņä£ļŖö Ļ│Āņä▒ļŖźņØś ĒĢśļō£ņø©ņ¢┤Ļ░Ć ĒĢäņłśņĀüņ£╝ļĪ£ ņÜöĻĄ¼ļÉśņŚłņ£╝ļéś, Ēśäņ×¼ļŖö Ļ░£ņØĖņÜ® ņ╗┤Ēō©Ēä░ ņłśņżĆņØś ņé¼ņ¢æņ£╝ļĪ£ļÅä ņČ®ļČäĒ׳ ĻĄ¼ļÅÖņØ┤ Ļ░ĆļŖźĒĢ┤ņĪīļŗż(Kim, 2016; Jung et al., 2018).
3.3 ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø
ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØĆ ļöźļ¤¼ļŗØ ļČäņĢ╝ņŚÉņä£ ņØ┤ļ»Ėņ¦ĆņØĖņŗØļ┐Éļ¦ī ņĢäļŗłļØ╝ ņØīņä▒ņØĖņŗØ ļō▒ ļŗżņ¢æĒĢ£ Ļ││ņŚÉņä£ ņé¼ņÜ®ļÉśĻ│Ā ņ׳ļŗż. ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØĆ ņØ┤ļ»Ėņ¦ĆļĪ£ļČĆĒä░ ņČöņāüĒÖöļÉ£ ĒŖ╣ņ¦ĢņØä ņČöņČ£ĒĢśļŖö ņĄ£ņĀüņØś ļ░®ļ▓Ģņ£╝ļĪ£ 2012ļģäņŚÉ ILSVRC (imagenet large scale visual recognition challenge)ļź╝ ĒåĄĒĢ┤ ĻĖ░ņĪ┤ ņØĖĻ│Ąņ¦ĆļŖź ļ¬©ļŹĖļōżņØś ņä▒ļŖźņØä ņĢĢļÅäņĀüņ£╝ļĪ£ ļø░ņ¢┤ļäśņ£╝ļ®░ ĻĘĖ ņä▒ļŖźņØä Ļ▓Ćņ”ØĒĢśņśĆļŗż. ĻĖ░ņĪ┤ņŚÉ ņé¼ņÜ®ļÉ£ ņŗĀĻ▓Įļ¦ØņØĆ ņØĖņĀæĒĢśļŖö Ļ│äņĖĄņØś ļ¬©ļōĀ ļē┤ļ¤░ņØ┤ Ļ▓░ĒĢ®ļÉ£ Affine Ļ│äņĖĄņØ┤ļØ╝ļŖö ņØ┤ļ”äņ£╝ļĪ£ ĻĄ¼ĒśäļÉ£ ņÖäņĀäņŚ░Ļ▓░(fully connected) ĒśĢĒā£ņØ┤ņŚłļŗż. Affine Ļ│äņĖĄĻĄ¼ņĪ░ļŖö 1ņ░©ņøÉ ļŹ░ņØ┤Ēä░ļ¦īņØä ņ×ģļĀźļ░øĻĖ░ ļĢīļ¼ĖņŚÉ 3ņ░©ņøÉ ļŹ░ņØ┤Ēä░ļź╝ 1ņ░©ņøÉņ£╝ļĪ£ ļ│ĆĒÖśĒĢśņŚ¼ ņ×ģļĀźĒĢ┤ņĢ╝ ĒĢ£ļŗż. ņØ┤ļĢī 3ņ░©ņøÉ ļŹ░ņØ┤Ēä░ņØś Ļ│ĄĻ░äņĀü ĒŖ╣ņ¦ĢņĀĢļ│┤Ļ░Ć ņåīņŗżļÉśļŖö ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢśĻ▓ī ļÉśĻ│Ā, ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØĆ ņØĖņĀæĒĢ£ ĒöĮņģĆ Ļ░äņØś ĒŖ╣ņ¦ĢņØä ņ£Āņ¦ĆĒĢśļ®░ 3ņ░©ņøÉ ņĀĢļ│┤ļź╝ ĻĘĖļīĆļĪ£ ņ▓śļ”¼ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ĒöĮņģĆņØś Ļ│ĄĻ░äņĀü ĒŖ╣ņ¦ĢņØä ņ£Āņ¦ĆĒĢĀ ņłś ņ׳Ļ▓ī ļÉ£ļŗż. ĒĢ®ņä▒Ļ│▒ ņŚ░ņé░ņØĆ ņØ┤ļ»Ėņ¦Ć ļé┤ņØś ļ¬©ļōĀ ĒöĮņģĆņŚÉ ļīĆĒĢ┤ ļ░śļ│ĄņØä ĒåĄĒĢ┤ ņ▓śļ”¼ĒĢśĻ▓ī ļÉśļ®░ ĒĢ®ņä▒Ļ│▒ ĒĢäĒä░ņØś Ļ░£ņłśĻ░Ć ļ¦ÄņĢäņ¦łņłśļĪØ ļŗżņ¢æĒĢ£ ĒŖ╣ņ¦ĢņØä ņČöņČ£ĒĢĀ ņłś ņ׳ļŗż. ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņØĆ Fig. 5ņÖĆ Ļ░ÖņØ┤ ņ×ģļĀźļÉ£ ņØ┤ļ»Ėņ¦ĆļĪ£ļČĆĒä░ ĒĢ®ņä▒Ļ│▒ņØä ņłśĒ¢ēĒĢśņŚ¼ Ļ│äņĖĄņØś ĒŖ╣ņ¦ĢņØä ņČöņČ£ĒĢ£ļŗż. ĒĢ®ņä▒Ļ│▒ ņŚ░ņé░ņØä ĒåĄĒĢ┤ ņČöņČ£ļÉ£ ĒŖ╣ņ¦ĢņØĆ ļŗżņŗ£ ĒŖ╣ņ¦Ģļ¦Ą(feature map) ņ£äņŚÉ ņś¼ļĀżņ¦ĆĻ▓ī ļÉ£ļŗż.
ĻĘĖļ”¼Ļ│Ā ĒÆĆļ¦ü Ļ│äņĖĄņØä ĒåĄĒĢ┤ ĒŖ╣ņ¦Ģļ¦ĄņØś Ēü¼ĻĖ░ļź╝ ņżäņØ┤ļŖö ļŗżņÜ┤ ņāśĒöīļ¦ü(down sampling)Ļ│╝ņĀĢņØä Ļ▒░ņ╣śĻ▓ī ļÉ£ļŗż. 2ņ░©ņøÉ ņØ┤ļ»Ėņ¦Ć(H ├Ś W)ņŚÉ ļīĆĒĢ┤ņä£ FH ├Ś FW Ēü¼ĻĖ░ņØś ĒĢäĒä░ļź╝ ļ¬©ļōĀ ņ£äņ╣śņŚÉņä£ ĒĢ®ņä▒Ļ│▒ņŚ░ņé░ņØ┤ ļÉĀ ņłś ņ׳ļÅäļĪØ ņØ┤ļÅÖņŗ£ĒéżĻ│Ā, ņŖżĒŖĖļØ╝ņØ┤ļō£(S)ņÖĆ Ēī©ļö®(P)ņØä ņĀüņÜ®ĒĢśņŚ¼ ņČ£ļĀźļÉśļŖö ĒŖ╣ņ¦Ģļ¦ĄņØś Ēü¼ĻĖ░(OH ├Ś OW)ļŖö Eq. (3)Ļ│╝ Ļ░ÖņØ┤ ņŻ╝ņ¢┤ņ¦äļŗż.
3.4 Faster R-CNN
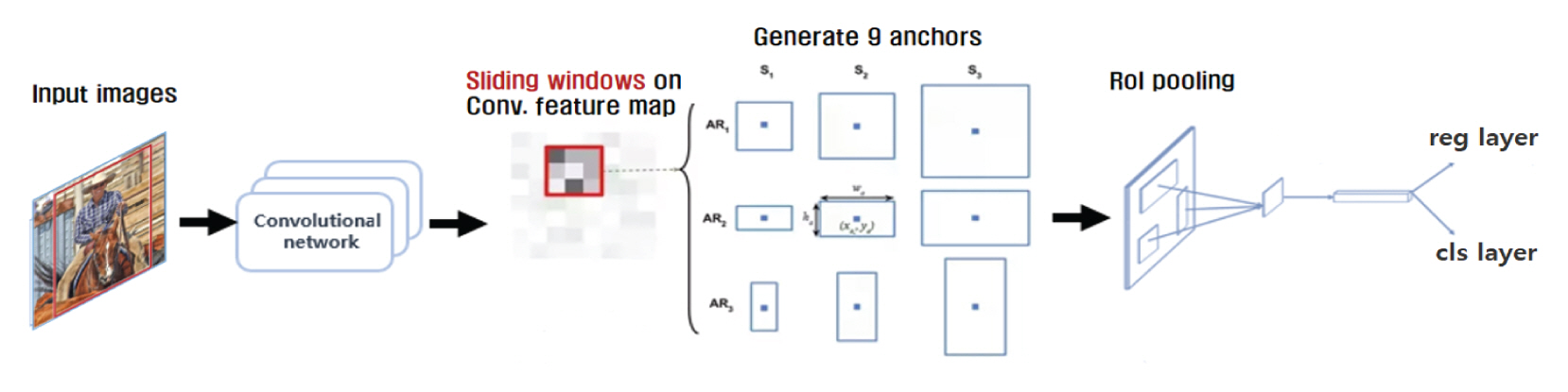
ļöźļ¤¼ļŗØĻĖ░ļ▓ĢņØä ĻĖ░ļ░śņ£╝ļĪ£ ĒĢśļŖö ņØ┤ļ»Ėņ¦Ć ņØĖņŗØ ļ¬©ļŹĖļĪ£ļŖö ĻĄ¼ĻĖĆ(google)ņØś Inception V3ļéś MobilenetĻ│╝ Ļ░ÖņØĆ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ĻĖ░ļ░śņØś ņØ┤ļ»Ėņ¦Ć ļČäļźś ļ¬©ļŹĖļōżļÅä ļø░ņ¢┤ļé£ ņĀĢĒÖĢļÅäļź╝ ļ│┤ņØ┤Ļ│Ā ņ׳ņ¦Ćļ¦ī, ņĄ£ĻĘ╝ņŚÉļŖö ļŹö ļéśņĢäĻ░Ć ņØ┤ļ»Ėņ¦Ć ļé┤ņŚÉņä£ ņŚ¼ļ¤¼ Ļ░£ņØś Ļ░Øņ▓┤Ļ░Ć ņĪ┤ņ×¼ĒĢśļŖö ņ£äņ╣śņśüņŚŁ ņĀĢļ│┤ņÖĆ Ļ░Øņ▓┤ļōżņØś ņóģļźśļź╝ ļŗżņżæņ£╝ļĪ£ ņČöļĪĀĒĢśļŖö Region-convolutional neural network (R-CNN)ņØ┤ļéś Single shot multibox detector (SSD)ņÖĆ Ļ░ÖņØĆ Ļ░Øņ▓┤Ļ▓ĆņČ£(object detection) ņĢīĻ│Āļ”¼ņ”śļōżņØ┤ ņŚ░ĻĄ¼ļÉśĻ│Ā ņ׳ļŗż. ļīĆĒæ£ņĀüņ£╝ļĪ£ ĻĖ░ņĪ┤ņØś R-CNNņØä ļ│┤ņÖäĒĢ£ Faster R-CNNņØĆ Ļ░Øņ▓┤Ļ░Ć ņĪ┤ņ×¼ĒĢĀ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉśļŖö Ļ┤Ćņŗ¼ņśüņŚŁņØä ņĀ£ņĢłĒĢśļŖö region proposal Ļ│╝ņĀĢņ£╝ļĪ£ ņØĖĒĢ£ ņŚ░ņé░ ņ¦ĆņŚ░ņØä Ļ░£ņäĀĒĢśĻ│Āņ×É Region proposal network(RPN)ņØ┤ļØ╝ ļČłļ”¼ļŖö ļ¦Ø(network)ņØä ņČöĻ░ĆĒĢśņŚ¼ ĻĘĖ Ļ▓░Ļ│╝ļź╝ RoI ĒÆĆļ¦üĻ│äņĖĄņ£╝ļĪ£ ņĀäļŗ¼ĒĢśļÅäļĪØ ĒĢ£ļŗż. ļśÉĒĢ£ ņØ┤ļ»Ėņ¦Ć ļé┤ņŚÉņä£ Ļ░Øņ▓┤ļź╝ ĒāÉņāēĒĢśļŖö Ļ│╝ņĀĢņØĆ Fig. 6Ļ│╝ Ļ░ÖņØ┤ ŅĆČ├ŚŅĆČĒöĮņģĆ Ēü¼ĻĖ░ņŚÉ ĻĘĖļ”╝ ņżæĻ░äĻ│╝ Ļ░ÖņØ┤ 9Ļ░Ćņ¦Ć ļ╣äņ£©ņØś ņĢĄņ╗ż ļ░ĢņŖż(anchor boxes)ļź╝ ņØ┤ļ»Ėņ¦Ć ĒÅēļ®┤ņāüņŚÉņä£ ņØ┤ļÅÖĒĢśļ®░ Ļ░Øņ▓┤Ļ░Ć ņ׳ņØä Ļ░ĆļŖźņä▒ņØ┤ ņ׳ļŖö ĒŖ╣ņ¦ĢņØä ĒāÉņāēĒĢ┤ ļéśĻ░ĆĻ▓ī ļÉśĻ│Ā, reg layerņÖĆ cls layerļź╝ ĒåĄĒĢ┤ Ļ░üĻ░ü 4Ļ░Ćņ¦Ć ņóīĒæ£ Ļ░ÆĻ│╝ ņ£ĀĒÜ©ĒĢ£ Ļ░Øņ▓┤ņØ╝ ĒÖĢļźĀņØä ņĖĪņĀĢĒĢśĻ▓ī ļÉ£ļŗż.
ņØ┤ļ¤¼ĒĢ£ ļöźļ¤¼ļŗØ ĻĖ░ļ░śņØś Ļ░Øņ▓┤Ļ▓ĆņČ£ĻĖ░ļ▓ĢņØĆ ņØ┤ļ»Ėņ¦Ć ļé┤ņŚÉņä£ Ļ░Øņ▓┤ņØś ņ£äņ╣śļ┐Éļ¦ī ņĢäļŗłļØ╝ Ļ▓╣ņ│ÉņĀĖņ׳ļŖö Ļ░Øņ▓┤ņŚÉ ļīĆĒĢ£ ņČöļĪĀļÅä Ļ░ĆļŖźĒĢ£ ņןņĀÉņØ┤ ņ׳ņ¢┤, ņ╗┤Ēō©Ēä░ ļ╣äņĀä ļČäņĢ╝ņŚÉņä£ ĒĢ£Ļ│äļĪ£ ņŚ¼Ļ▓©ņĪīļŹś Ļ│ĀņåŹ Ļ░Øņ▓┤Ļ▓ĆņČ£ ļ¼ĖņĀ£ļź╝ Ēü¼Ļ▓ī Ļ░£ņäĀ ņŗ£Ēé© ņŚ░ĻĄ¼Ļ▓░Ļ│╝ļĪ£ ļ│╝ ņłś ņ׳ļŗż(Ren et al., 2015; Kim et al., 2018).
3.5 ļō£ļĪŁņĢäņøā
ņŗ¼ņĖĄņŗĀĻ▓Įļ¦ØņØä ĒåĄĒĢ┤ ņØ┤ļ»Ėņ¦Ć ļŹ░ņØ┤Ēä░ļōżņØä ĒĢÖņŖĄĒĢĀ ļĢī, ļŹ░ņØ┤Ēä░ņģŗņØä ņåīļ¤ēņ£╝ļĪ£ ņé¼ņÜ®ĒĢśļŖö Ļ▓ĮņÜ░ ĒĢÖņŖĄĒĢśĻ│Āņ×É ĒĢśļŖö Ļ░Øņ▓┤ņŚÉ ļīĆĒĢ£ ņØĖĻ│Ąņ¦ĆļŖźļ¬©ļŹĖņØś ņØ┤ĒĢ┤ļÅäņÖĆ ņĀĢĒÖĢļÅäĻ░Ć ļ¢©ņ¢┤ņ¦ĆļŖö Ļ│╝ņĀüĒĢ® ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢĀ ņłś ņ׳ļŗż.
ņØ┤ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ┤ ļō£ļĪŁņĢäņøā(dropout)ĻĖ░ļ▓ĢņØä ņé¼ņÜ®ĒĢśņśĆļŖöļŹ░, ļō£ļĪŁņĢäņøāņØĆ ļ»ĖņäĖņĪ░ņĀĢ(fine-tuning) ļŗ©Ļ│äņŚÉņä£ ņĀüņÜ®ļÉśļŖö ĻĖ░ļ▓Ģņ£╝ļĪ£ Fig. 7Ļ│╝ Ļ░ÖņØ┤ ĒĢÖņŖĄņØ┤ ņ¦äĒ¢ēļÉĀ ļĢī ņĀäņ▓┤ ļģĖļō£ ņżæ 50~80% ņĀĢļÅäņŚÉ ņØ┤ļź┤ļŖö ļģĖļō£ņØś Ļ░ĆņżæĻ░ÆņØä 0ņ£╝ļĪ£ ļ¦īļōżņ¢┤ ĒāłļØĮņŗ£Ēé© Ēøä ĒĢÖņŖĄĒĢśĻ▓ī ļÉ£ļŗż. ņØ┤ļĀćĻ▓ī ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢśļ®┤ ņĀĢĻĘ£ĒÖö(regularization) ĒÜ©Ļ│╝ļź╝ Ļ░ĆņĀĖ ņĀĢĒÖĢļÅäĻ░Ć Ē¢źņāüļÉśĻ▓ī ļÉ£ļŗż(Srivastava et al., 2014).
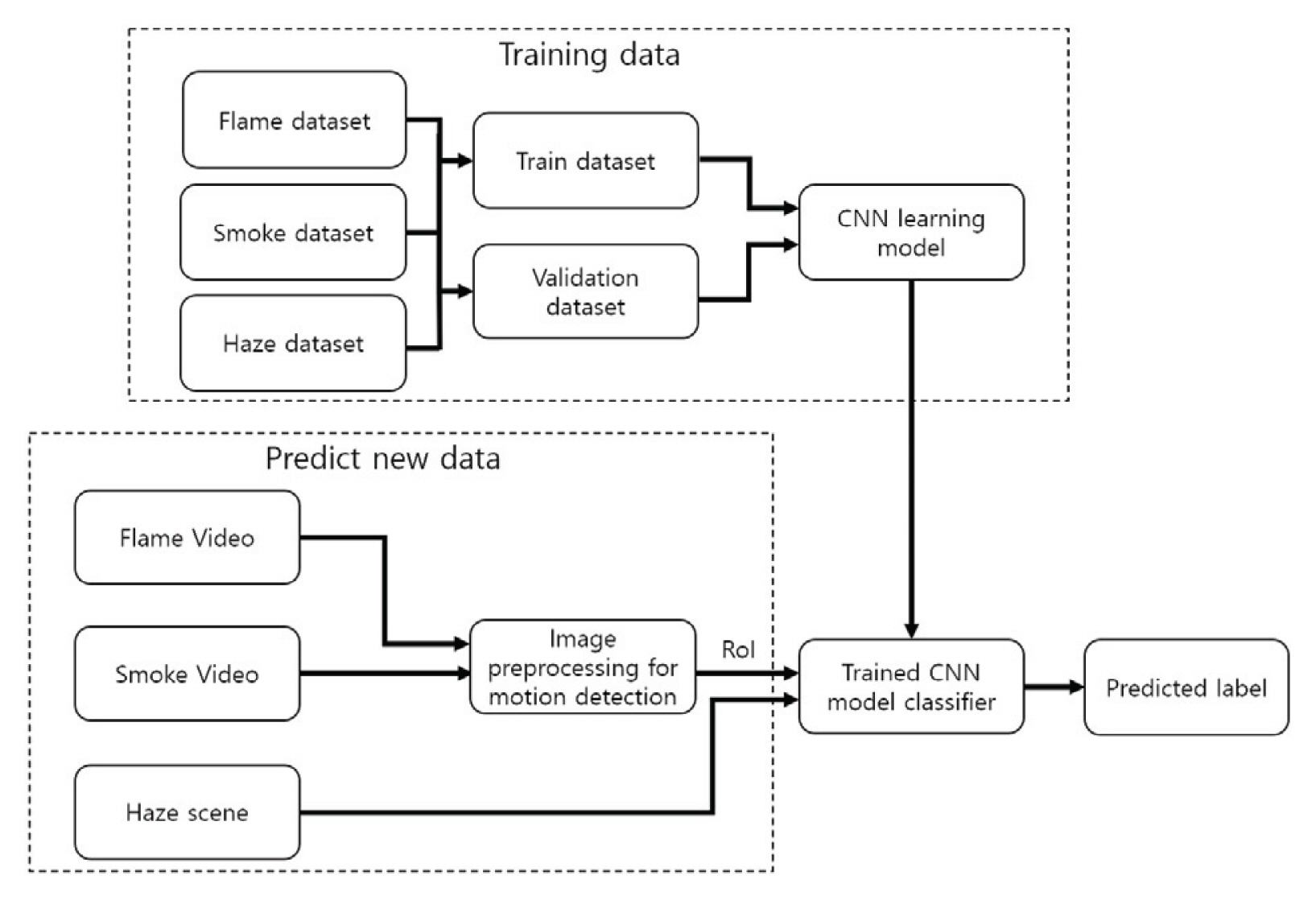
4. ņØĖĻ│Ąņ¦ĆļŖźņØä ņØ┤ņÜ®ĒĢ£ ĒÖöņ×¼Ļ░Éņ¦Ć ņŚ░ĻĄ¼
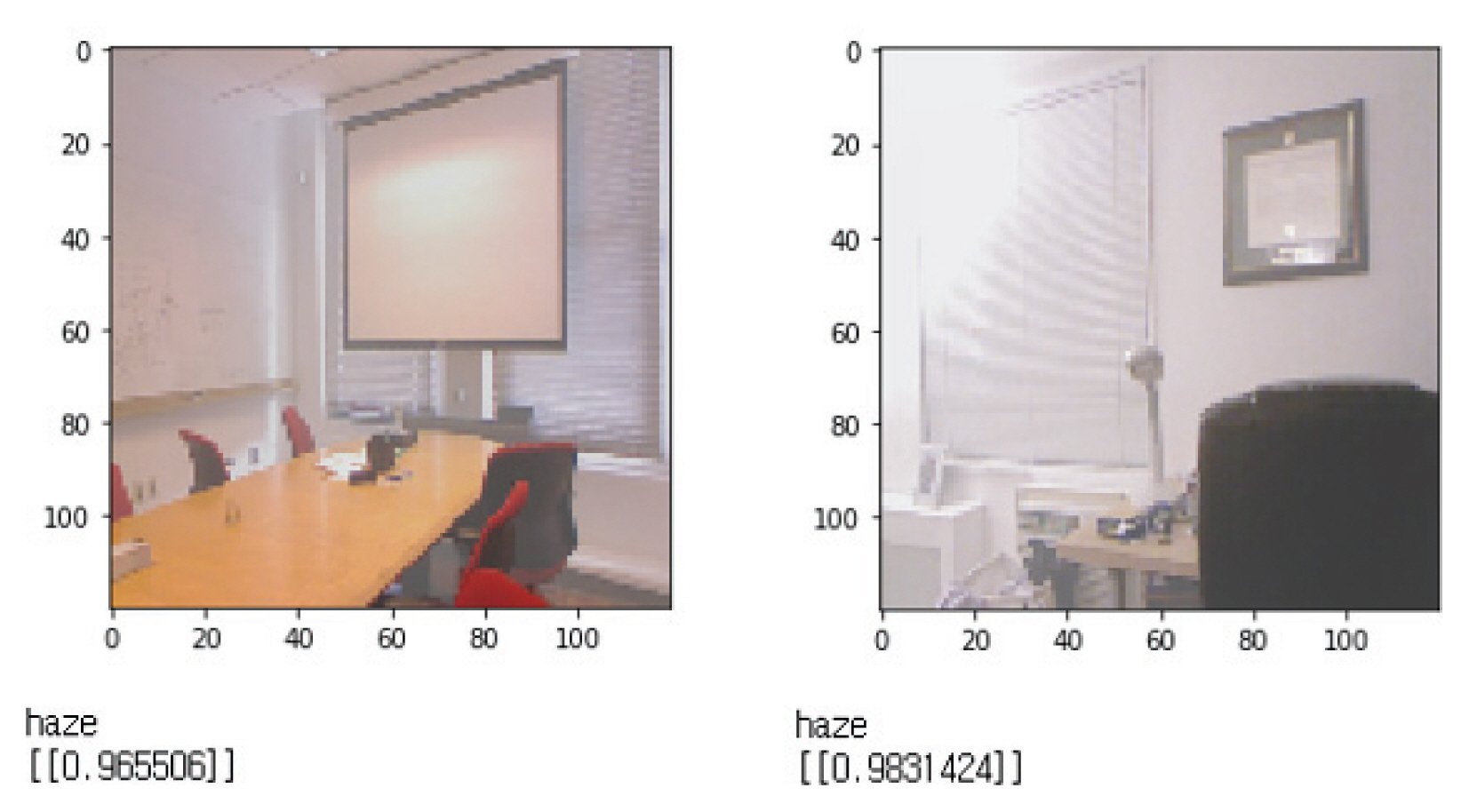
Fig. 8ņØĆ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ļÉ£ ņØĖĻ│Ąņ¦ĆļŖź ļ¬©ļŹĖņØś ĒĢÖņŖĄ ļ░Å ņČöļĪĀņŚÉ ļīĆĒĢ£ ņĀäņ▓┤ ĒØÉļ”äļÅäņØ┤ļŗż. ĻĘĖļ”╝ ņāüļŗ© ļČĆļČäņØĆ ņØ┤ļ»Ėņ¦Ć ļŹ░ņØ┤Ēä░ņØś ĒĢÖņŖĄ Ļ│╝ņĀĢņ£╝ļĪ£, ņé¼ņÜ®ļÉ£ ļŹ░ņØ┤Ēä░ņģŗņØś ņóģļźśļŖö Fig. 9ņÖĆ Ļ░ÖņØ┤ ņóīņĖĪļČĆĒä░ ĒÖöņŚ╝(flame), ņŚ░ĻĖ░(smoke) ĻĘĖļ”¼Ļ│Ā ņŚ░ļ¼┤(haze) ļŹ░ņØ┤Ēä░ņģŗņ£╝ļĪ£ ļéśļłäņ¢┤ņä£ ļČäļźśĒĢśņśĆļŗż.
ņŚ░ĻĄ¼ ņ┤łĻĖ░ņŚÉļŖö ĒÖöņ×¼ļź╝ Ļ░Éņ¦ĆĒĢśĻĖ░ ņ£äĒĢ┤ ļČłĻĮāĻ│╝ ņŚ░ĻĖ░ņŚÉ ļīĆĒĢ£ ļŹ░ņØ┤Ēä░ņģŗņØä ņłśņ¦æĒĢśņŚ¼ ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś ņŗżņĀ£ ĒÖöņ×¼ņśüņāü ņ┤łĻĖ░ņŚÉ ļČłĻĮāņØ┤ļéś ņŚ░ĻĖ░ņØś ņ£ĀļÅÖļÅä ļ│┤ņØ┤ņ¦Ćļ¦ī ņŗżļé┤Ļ│ĄĻ░ä ņĢłņŚÉ ņĢłĻ░£ ņ”ē, ņŚ░ļ¼┤ņØś ĒśĢĒā£ļĪ£ ņŚ░ĻĖ░Ļ░Ć ņśģĻ▓ī ĒŹ╝ņ¦Ćļ®░ ĒÖöņ×¼Ļ░Ć ņ¦äĒ¢ēļÉśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż.
ļö░ļØ╝ņä£ ņØ┤ļ¤¼ĒĢ£ ļŗżņ¢æĒĢ£ ņä▒ņāüņ£╝ļĪ£ļČĆĒä░ ĒÖöņ×¼ļź╝ Ļ░Éņ¦ĆĒĢśĻ│Āņ×É Fig. 9ņØś ņóīņĖĪĻ│╝ Ļ░ÖņØ┤ ĒÖöņ×¼ņŚÉņä£ ņØ╝ļ░śņĀüņ£╝ļĪ£ ļ│┤ņØ┤ļŖö ĒÖöņŚ╝ļŹ░ņØ┤Ēä░ņģŗĻ│╝ ņŚ░ĻĖ░Ļ░Ć ĒÖĢņé░ļÉśļŖö ĒśĢĒā£Ļ░Ć ļ│┤ņØ┤ļŖö ņŚ░ĻĖ░ļŹ░ņØ┤Ēä░ņģŗ ĻĘĖļ”¼Ļ│Ā ņŗżļé┤ņĀäņ▓┤ņŚÉ ņ▓£ņ▓£Ē׳ ņŚ░ĻĖ░Ļ░Ć ĒŹ╝ņ¦ä ņŚ░ļ¼┤ ĒśĢĒā£ņØś ļŹ░ņØ┤Ēä░ņģŗ 3Ļ░Ćņ¦ĆļĪ£ ĻĄ¼ļČäĒĢ┤ ņłśņ¦æĒĢśņśĆļŗż. ĻĘĖļ”¼Ļ│Ā ņé¼ņÜ®ļÉ£ ļŹ░ņØ┤Ēä░ņģŗņØś ņłśļŖö Table 1ņŚÉ ļéśĒāĆļéĖļŗż.
Ļ░üĻ░üņØś ļŹ░ņØ┤Ēä░ņģŗņØĆ ņł£ņłśĒĢ£ ĒĢÖņŖĄņŚÉ ĒĢäņÜöĒĢ£ ĒĢÖņŖĄņģŗ(train set)Ļ│╝ ĒĢÖņŖĄļÅäņżæ ļ¬©ļŹĖņØś ņĀĢĒÖĢļÅäļź╝ ĒÅēĻ░ĆĒĢśĻĖ░ ņ£äĒĢ£ Ļ▓Ćņ”Øņģŗ(validation set)ņ£╝ļĪ£ 10ļīĆ2 ļ╣äņ£©ļĪ£ ļéśļłäņ¢┤ ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢśņśĆļŗż.
ņÖäļŻīļÉ£ ĒĢÖņŖĄļ¬©ļŹĖņŚÉ ļīĆĒĢ┤ ņŗżņĀ£ ņČöļĪĀ ņłśĒ¢ēņØĆ Fig. 8ņØś ĒĢśļŗ©Ļ│╝ Ļ░Öļŗż. ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ļŖö ņśüņāü ļé┤ņŚÉ ņ£ĀļÅÖņĀüņØĖ ņøĆņ¦üņ×äņØ┤ ņĪ┤ņ×¼ĒĢśļ»ĆļĪ£ ņśüņāü ņĀäņ▓śļ”¼ĻĖ░ļ▓ĢņØä ĒåĄĒĢśņŚ¼ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ ņśüņŚŁņŚÉ ļīĆĒĢ┤ņä£ļ¦ī Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņČöņČ£ĒĢśņŚ¼ ĒĢÖņŖĄļÉ£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØä ņØ┤ņÜ®ĒĢ┤ ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ņŚÉ ĒĢ┤ļŗ╣ļÉśļŖöņ¦Ć ņČöļĪĀņØä ĒĢśļÅäļĪØ ĒĢśņśĆļŗż.
ĒĢśņ¦Ćļ¦ī ņŚ░ļ¼┤ ĒśĢĒā£ņØś ļŹ░ņØ┤Ēä░ņģŗņØä ĒĢÖņŖĄĒĢ£ ļ¬©ļŹĖņØĆ Ļ┤Ćņŗ¼ņśüņŚŁņØ┤ ņĢäļŗī ņśüņāü ņĀäņ▓┤ņśüņŚŁņŚÉ ļīĆĒĢ┤ ņŚ░ļ¼┤ ĒśĢņä▒ ņŚ¼ļČĆļź╝ ņČöļĪĀĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£, ļæÉ Ļ░Ćņ¦Ć Ļ▓ĆņČ£ļ░®ļ▓ĢņØś ņ░©ņØ┤ļź╝ ļæÉĻ│Ā ņ¦äĒ¢ēĒĢśņśĆļŗż.
4.1 ņśüņāüņ░©ļČäņØä ĒåĄĒĢ£ Ēøäļ│┤ņśüņŚŁ Ļ▓ĆņČ£
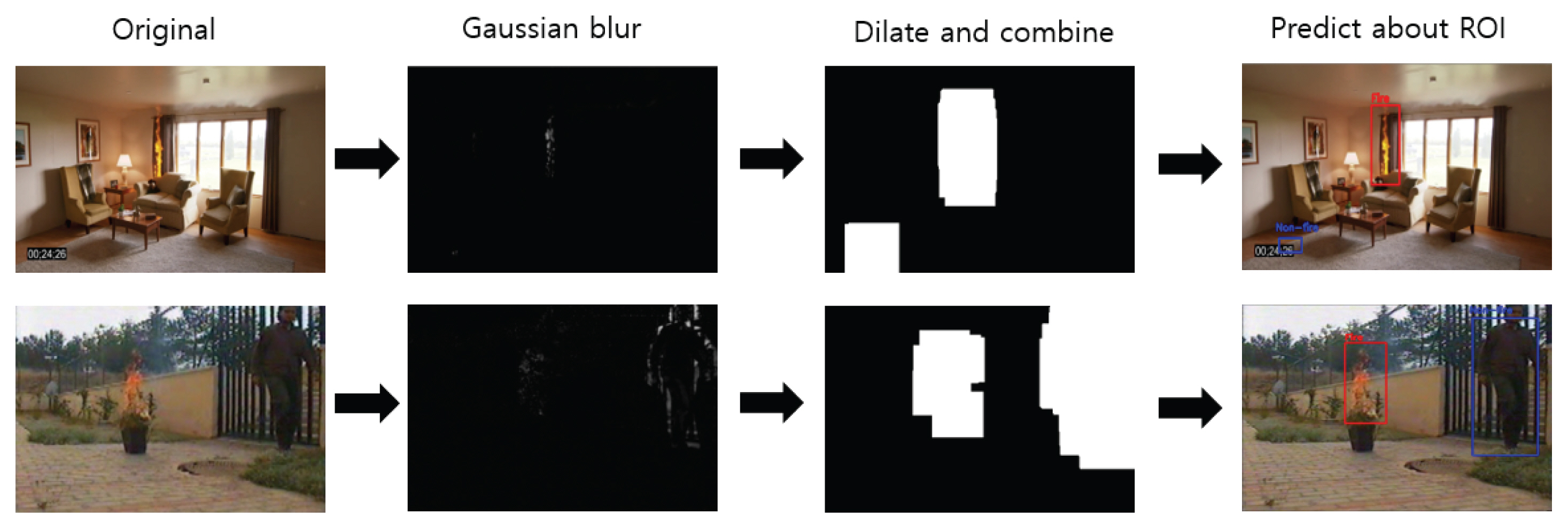
ņ×ģļĀź ņśüņāüņ£╝ļĪ£ļČĆĒä░ ĒÖöņ×¼ļź╝ Ļ▓ĆņČ£ĒĢśĻ│Āņ×É ĒĢĀ ļĢī ņśüņāü ļé┤ņŚÉļŖö ņ░ŠĻ│Āņ×É ĒĢśļŖö ĒÖöņ×¼ņŚÉ ĒĢ┤ļŗ╣ļÉśļŖö Ļ░Øņ▓┤ ņØ┤ņÖĖņØś ņŚ¼ļ¤¼ ņé¼ļ¼╝ļōżņØ┤ ņĪ┤ņ×¼ĒĢĀ ņłś ņ׳ņ£╝ļ»ĆļĪ£ ņĀäĻ▓ĮņśüņāüĻ│╝ ļ░░Ļ▓ĮņśüņāüņØś ļČäļ”¼Ļ░Ć ĒĢäņÜöĒĢśļŗż. ļö░ļØ╝ņä£ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ×ģļĀź ņśüņāüņ£╝ļĪ£ļČĆĒä░ ņØ╝ņĀĢ ņŗ£Ļ░äņ░©ļź╝ ļæÉĻ│Ā ļæÉ ĒöäļĀłņ×äņØä ņśüņāüņ░©ļČä(image difference)ĒĢśņŚ¼ ņśüņāü ļé┤ņŚÉņä£ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ ļČĆļČäņØä Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. Eq. (4)ļŖö ņØ╝ņĀĢĻ░äĻ▓® ĒöäļĀłņ×äņŚÉ ļīĆĒĢ┤ ņ░©ļČäņØä ĒåĄĒĢ┤ Ļ┤Ćņŗ¼ņśüņŚŁņØä ĻĄ¼ĒĢśļŖö ņŗØņØ┤ļŗż.
F1ņØĆ ņ▓śņØī ņĀĆņןļÉ£ ņśüņāü ĒöäļĀłņ×äņØ┤Ļ│Ā F2ļŖö ņØ╝ņĀĢ ņŗ£Ļ░ä ļÆżņØś ņśüņāü ĒöäļĀłņ×äņ£╝ļĪ£ ļæÉ Ļ░£ņØś ņ░©ļČäņØä ĒåĄĒĢ┤ ņ×äĻ│äĻ░Æ(threshhold) Tļ│┤ļŗż Ēü░ Ļ▓ĮņÜ░ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ ņśüņŚŁņ£╝ļĪ£ ĒīÉļŗ©ĒĢśņŚ¼ Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņé¼ņÜ®ļÉśĻ▓ī ļÉ£ļŗż. ņśüņāüņ░©ļČäņØä ņłśĒ¢ēĒĢśĻĖ░ ņĀä Ļ░ü ĒöäļĀłņ×äņØĆ ņ╣┤ļ®öļØ╝ņØś ņä╝ņä£ļéś ļööņ¦ĆĒäĖ ņ▓śļ”¼ Ļ│╝ņĀĢ ņżæ ļ░£ņāØĒĢśļŖö ļģĖņØ┤ņ”łļōżļĪ£ ņØĖĒĢ┤ ļ░£ņāØĒĢ£ ļ»ĖņäĖĒĢ£ ļ│ĆĒÖöļÅä ņøĆņ¦üņ×äņ£╝ļĪ£ Ļ░äņŻ╝ĒĢĀ ņłś ņ׳ņ£╝ļ»ĆļĪ£ ņØ┤ļź╝ Ļ░ĆņÜ░ņŗ£ņĢł Ēś╝ĒĢ® ļ¬©ļŹĖļ¦ü(Gaussian mixture model)ņØä ĒåĄĒĢ┤ ĒĢ┤Ļ▓░ĒĢśņśĆļŗż.
Fig. 10ņØś ņóīņĖĪņØĆ ņśüņāü ņĀäņ▓śļ”¼ĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ ņśüņŚŁņ£╝ļĪ£ Ļ▓ĆņČ£Ēøäļ│┤ļĪ£ ņČöņČ£ĒĢśĻ│Āņ×É ĒĢśļŖö ņøÉļ│ĖņśüņāüņØś ĒĢ£ ņןļ®┤ņØ┤Ļ│Ā, ņØ┤ļź╝ ņØ╝ņĀĢņŗ£Ļ░ä Ļ░äĻ▓®ņØä ļæÉĻ│Ā ņ░©ļČäņØä ĒĢ£ ļŹ░ņØ┤Ēä░ļź╝ Ļ░ĆņÜ░ņŗ£ņĢł ĒĢäĒä░ļ¦üņØä ņłśĒ¢ēĒĢ£ Ļ▓░Ļ│╝Ļ░Ć ņÜ░ņĖĪņŚÉ ĒĢ┤ļŗ╣ĒĢ£ļŗż. ņśüņāü ļé┤ņŚÉņä£ ļ│ĆĒÖöĻ░Ć Ēü┤ņłśļĪØ ļ░ØĻ▓ī ļéśĒāĆļéśĻ│Ā, ņ×æņØäņłśļĪØ ņ¢┤ļæĪĻ▓ī ļéśĒāĆļé£ļŗż. ņŚ¼ĻĖ░ņä£ ņśüņāü ļé┤ņŚÉņä£ ļģĖņØ┤ņ”łņØ╝ ņłś ņ׳ļŖö ņ×æņØĆ ļ│ĆĒÖöļōżņØĆ ņäżņĀĢļÉ£ ņ×äĻ│äĻ░ÆņŚÉ ņØśĒĢ┤ ļ¼┤ņŗ£ļÉ£ļŗż.
Ļ░ĆņÜ░ņŗ£ņĢł ĒĢäĒä░ļź╝ ņØ┤ņÜ®ĒĢ£ Ēś╝ĒĢ® ļ¬©ļŹĖļ¦ü ļ░®ļ▓ĢņØĆ ņśüņāüņØś Ļ░ĢļÅä ļ│ĆĒÖöļź╝ ņĀĢĒÖĢĒĢśĻ▓ī ļéśĒāĆļé╝ ņłś ņ׳ļŖöļŹ░, KĻ░£ņØś Ļ░ĆņÜ░ņŗ£ņĢłļČäĒżļĪ£ ļ¬©ļŹĖļ¦ü ļÉśļŖö Ļ▓ĮņÜ░ Ē£śļÅäĻ░Æ XtņØś ĒÖĢļźĀņØĆ Eq. (5)ņÖĆ Ļ░Öļŗż.
ņŚ¼ĻĖ░ņä£, w j t ╬╝ j t Žā j t ╬╝ j t Žā j t
KĻ░£ņØś Ļ░ĆņÜ░ņŗ£ņĢł Ēś╝ĒĢ®ņØä ļ░░ņŚ┤ĒĢśņśĆņØä ļĢī w j t Žā j t
ņØ┤ļĢī ņ×äĻ│äĻ░Æ TļŖö ļ░░Ļ▓Į ļ¬©ļŹĖņØś ņĄ£ņåī ļ╣äņ£©ņŚÉ ĒĢ┤ļŗ╣ļÉ£ļŗż (Zivkovic, 2004; An and Kang, 2010; Hu and He, 2016).
Ļ┤Ćņŗ¼ņśüņŚŁņØĆ Fig. 11Ļ│╝ Ļ░ÖņØ┤ ņ×äĻ│äĻ░Æ ņØ┤ĒĢśņŚÉņä£ ĒĢäĒä░ļ¦üļÉ£ ĒöĮņģĆļōżņØ┤ ĒÖĢļīĆļÉśĻ│Ā ņØĖņĀæĒĢ£ ĒöĮņģĆļōżņØ┤ ĒĢ®ņä▒ļÉśņ¢┤ ļ¦īļōżņ¢┤ņ¦äļŗż. ĻĘĖļ”╝ ņÜ░ņĖĪņŚÉ ļ│┤ņØ┤ļŖö Ļ▓āņØ┤ ņĄ£ņóģņĀüņ£╝ļĪ£ ņøĆņ¦üņ×äņØ┤ ļ░£ņāØĒĢ£ Ļ┤Ćņŗ¼ņśüņŚŁņØä Ļ▓ĆņČ£Ēøäļ│┤ļĪ£ ļ╣©Ļ░äņāē ļ░öņÜ┤ļö® ļ░ĢņŖż(bounding box)ļĪ£ ņ▓śļ”¼ĒĢśņŚ¼ ļéśĒāĆļé┤ņŚłļŗż.
4.2 ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ļÉ£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØä ĻĄ¼ĒśäĒĢśĻĖ░ ņ£äĒĢ┤ ņØĖĒä░Ēöäļ”¼Ēä░ ļ░®ņŗØņØś ĒöäļĪ£ĻĘĖļלļ░Ź ņ¢Ėņ¢┤ņØĖ ĒīīņØ┤ņŹ¼(python)ņØä ņé¼ņÜ®ĒĢśņśĆĻ│Ā, ņśżĒöłņåīņŖż ļØ╝ņØ┤ļĖīļ¤¼ļ”¼ņØĖ ņ╝ĆļØ╝ņŖż(keras)ļź╝ ĒåĄĒĢ┤ ņŗĀĻ▓Įļ¦ØņØä ĻĄ¼ņä▒ĒĢśņśĆļŗż. Ļ│╝Ļ▒░ ņ╝ĆļØ╝ņŖżļŖö ĒģÉņä£ĒöīļĪ£ņÜ░(tensorflow)ņÖĆ ĒĢ©Ļ╗ś ņŚ░ĻĄ¼ņ×ÉļōżņØ┤ Ļ░Ćņן ļ¦ÄņØ┤ ņō░ļŖö ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ņĢīĻ│Āļ”¼ņ”ś ļØ╝ņØ┤ļĖīļ¤¼ļ”¼ņśĆņ£╝ļéś Ēśäņ×¼ ņ╝ĆļØ╝ņŖżļŖö ĒģÉņä£ĒöīļĪ£ņÜ░ņÖĆ ĒåĄĒĢ®ļÉśņ¢┤ ņé¼ņŗżņāü ĒģÉņä£ĒöīļĪ£ņÜ░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ļØ╝ņØ┤ļĖīļ¤¼ļ”¼Ļ░Ć ņ×æļÅÖļÉ£ļŗż. ņ╝ĆļØ╝ņŖżņÖĆ ĒģÉņä£ĒöīļĪ£ņÜ░ ņØ┤ņÖĖņŚÉ ĒģīņĢäļģĖ(theano), ĒåĀņ╣ś(torch) ļō▒ņØ┤ ņ׳ņ£╝ļéś, ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØä ĻĄ¼ĒśäĒĢśĻĖ░ņŚÉ Ļ░Ćņן ņ¦üĻ┤ĆņĀüņØĖ ļ¬©ļŹĖņØĖ ņ╝ĆļØ╝ņŖżļź╝ ņØ┤ņÜ®ĒĢśņśĆļŗż.
ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø Ļ│äņĖĄņØĆ Table 2ņÖĆ Ļ░ÖņØ┤ ĻĄ¼ņä▒ĒĢśņśĆņ£╝ļ®░, ņ×ģļĀź ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö 150 ├Ś 150 (pixel)Ēü¼ĻĖ░ņŚÉ 3Ļ░Ćņ¦Ć RGBņ╗¼ļ¤¼ļĪ£ ĻĄ¼ņä▒ļÉ£ ņØ╝ļ░śņĀüņØĖ Ēżļ¦ĘņØś ņØ┤ļ»Ėņ¦Ć ĒīīņØ╝ņØä ļŹ░ņØ┤Ēä░ņģŗņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ┤Ø 13Ļ░£ņØś ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņØä ņé¼ņÜ®ĒĢśņśĆĻ│Ā Ļ│äņĖĄ ņé¼ņØ┤ņŚÉļŖö ļŗżņÜ┤ ņāśĒöīļ¦üņØ┤ ļ¬®ņĀüņØĖ ĒÆĆļ¦ü Ļ│äņĖĄņØ┤ ņĪ┤ņ×¼ĒĢśļÅäļĪØ ņäżĻ│äĒĢśņśĆļŗż. ļśÉĒĢ£ ĒĢÖņŖĄ ņżæ ļ░£ņāØĒĢĀ ņłś ņ׳ļŖö Ļ│╝ņĀüĒĢ® ļ¼ĖņĀ£ļź╝ ņżäņØ┤Ļ│Āņ×É ĒĢ®ņä▒Ļ│▒-ĒÆĆļ¦üĻ│äņĖĄ ļ¦łņ¦Ćļ¦ē ļŗ©ņŚÉļŖö 50%ņØś ļģĖļō£ Ļ░ĆņżæĻ░Æ ĒāłļØĮļźĀņØä Ļ░¢ļŖö ļō£ļĪŁņĢäņøāņØä ņČöĻ░ĆĒĢśņśĆĻ│Ā, ņĄ£ņóģĻ│äņĖĄņØś ĒÖ£ņä▒ĒÖöĒĢ©ņłśļŖö ņŗ£ĻĘĖļ¬©ņØ┤ļō£ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņ░ŠĻ│Āņ×ÉĒĢśļŖö Ļ░Øņ▓┤ņØĖņ¦Ć ņĢäļŗīņ¦Ć ļæÉ Ļ░Ćņ¦ĆļĪ£ ļČäļźśĒĢśļÅäļĪØ ņäżĻ│ä ĒĢśņśĆļŗż.
4.3 ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØś ĒĢÖņŖĄ ļ░Å Ļ▓ĆņČ£Ļ▓░Ļ│╝
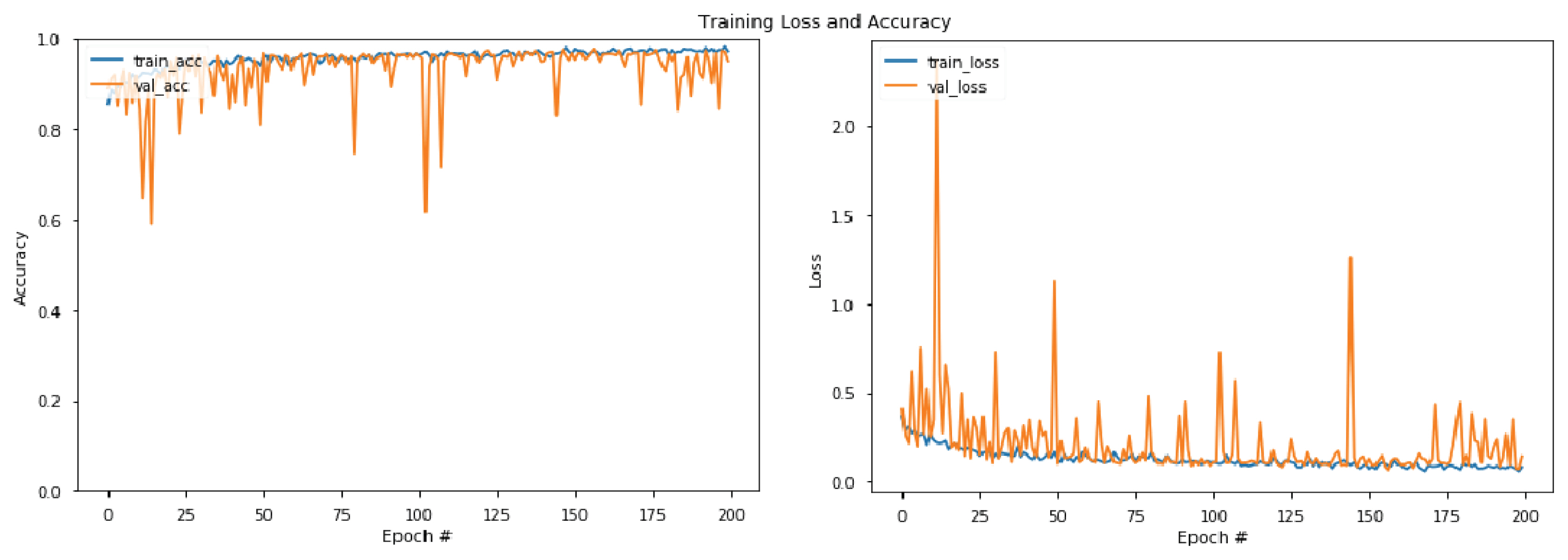
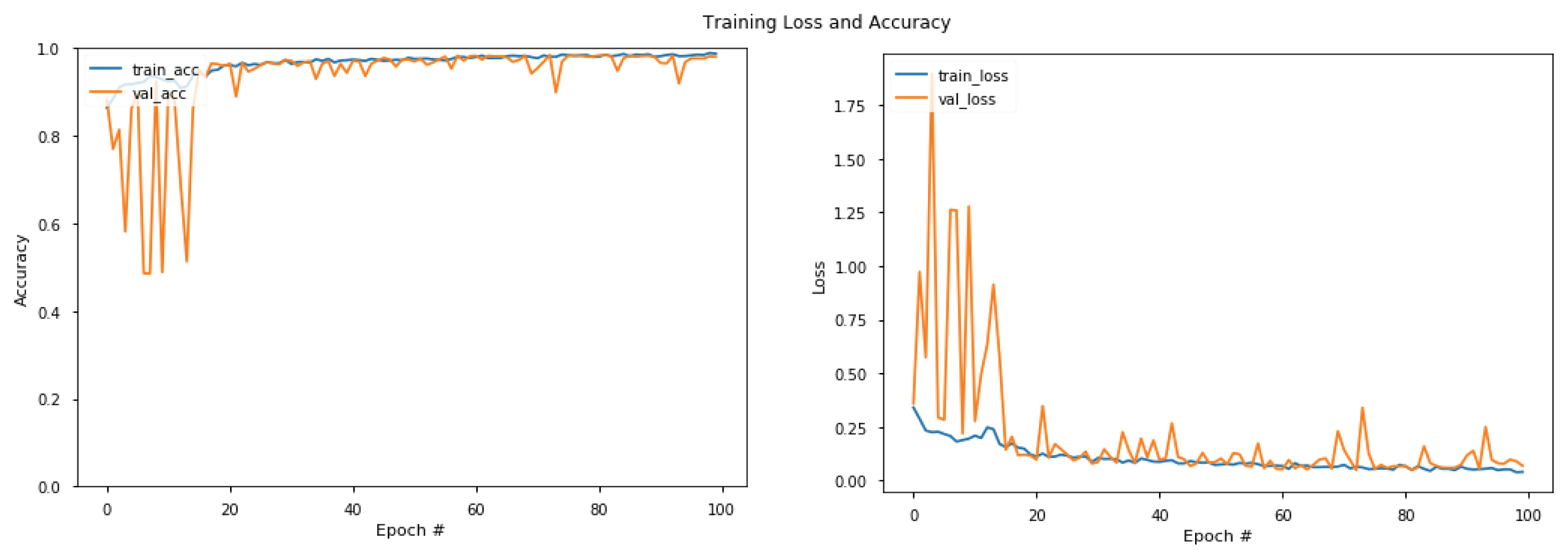
Fig. 12ļŖö ĒÖöņŚ╝ļŹ░ņØ┤Ēä░ņģŗņŚÉ ļīĆĒĢ£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØś ĒĢÖņŖĄĻ▓░Ļ│╝ ņĀĢĒÖĢļÅäņÖĆ ņåÉņŗżņØä ļ│┤ņŚ¼ņŻ╝ļŖö ĻĘĖļלĒöäņØ┤ļŗż. Ēīīļ×Ćņāē Ļ│ĪņäĀņØĆ ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ņģŗņØä ĒĢÖņŖĄĒĢśĻ│Ā ļŗżņŗ£ ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ņģŗņ£╝ļĪ£ļČĆĒä░ ļČäļźśņŚÉ ļīĆĒĢ£ ņĀĢĒÖĢļÅäņÖĆ ņĀĢļŗĄņŚÉ ļīĆĒĢ£ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØś ņśżļźś ņ¦ĆĒæ£ņØĖ ņåÉņŗżņØä ĻĘĖļלĒöäļĪ£ ļéśĒāĆļéĖ Ļ▓āņØ┤ļŗż. ņØ╝ļ░śņĀüņ£╝ļĪ£ ņĀĢĒÖĢļÅäĻ░Ć ņ”ØĻ░ĆĒĢĀņłśļĪØ ņåÉņŗżņØĆ ļ░śļ╣äļĪĆĒĢśņŚ¼ ņżäņ¢┤ļōżĻ▓ī ļÉ£ļŗż. ņŻ╝ĒÖ®ņāē Ļ│ĪņäĀņØĆ ĒĢÖņŖĄņŚÉ ņśüĒ¢źņØä ņŻ╝ņ¦Ć ņĢŖļŖö Ļ▓Ćņ”Ø ļŹ░ņØ┤Ēä░ņģŗņØä ĒåĄĒĢ┤ ņĀĢĒÖĢļÅäņÖĆ ņåÉņŗżņØä ĒÅēĻ░ĆĒĢ£ Ļ▓āņØ┤ļŗż. ņØ┤ļĢī ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ņģŗņØś ņĀĢĒÖĢļÅäļŖö ļåÆņØĆļŹ░ Ļ▓Ćņ”Ø ļŹ░ņØ┤Ēä░ņģŗņØś ņĀĢĒÖĢļÅäĻ░Ć ļé«Ļ▓ī ļéśĒāĆļéś ņ░©ņØ┤Ļ░Ć Ēü░ Ļ▓ĮņÜ░ Ļ│╝ņĀüĒĢ®ņØ┤ ļéśĒāĆļé£ Ļ▓āņ£╝ļĪ£ ļ│╝ ņłś ņ׳ņ£╝ļ®░, ĒĢÖņŖĄĻ│╝ Ļ▓Ćņ”Ø ļŹ░ņØ┤Ēä░ņģŗņØś ņĀĢĒÖĢļÅäĻ░Ć ņ£Āņé¼ĒĢśĻ▓ī ļéśĒāĆļéĀ ļĢīļŖö Ļ│╝ņĀüĒĢ® ņŚåņØ┤ ĒĢÖņŖĄņØ┤ ņל ņ¦äĒ¢ēļÉśļŖö Ļ▓āņ£╝ļĪ£ ļ│╝ ņłś ņ׳ļŗż. ļśÉĒĢ£ ņĀĢĒÖĢļÅäņÖĆ ņåÉņŗżņØś ņłśņ╣śĻ░Ć ņØ╝ņĀĢ ņłśņżĆņŚÉ ļ©Ėļ¼┤ļź┤Ļ│Ā ņłśļĀ┤ĒĢśļŖö ĒĢÖņŖĄ ĒܤņłśņŚÉņä£ ĒĢÖņŖĄņØä ņóģļŻīĒĢśļÅäļĪØ ĒĢśņśĆļŗż. Figs. 13Ļ│╝ 14ļŖö Ļ░üĻ░ü ņŚ░ĻĖ░ņÖĆ ņŚ░ļ¼┤ļŹ░ņØ┤Ēä░ņģŗņØä ĒĢÖņŖĄĒĢ£ Ļ▓░Ļ│╝ļź╝ ļ│┤ņŚ¼ņŻ╝ļŖö ĻĘĖļלĒöäļĪ£ ņŚ░ĻĖ░ļ│┤ļŗż ņŚ░ļ¼┤ļŹ░ņØ┤Ēä░ņģŗņŚÉ ļīĆĒĢ£ ĒĢÖņŖĄ ņĀĢĒÖĢļÅäĻ░Ć ļ╣Āļź┤Ļ▓ī ļÅäļŗ¼ĒĢśņŚ¼ ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ļŹ░ņØ┤Ēä░ņģŗ ļ│┤ļŗż ņĪ░ĻĖ░ņŚÉ ĒĢÖņŖĄņØä ņóģļŻīĒĢśņśĆļŗż.
Fig. 15ļŖö ĒĢÖņŖĄĒĢ£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØś ĒÅēĻ░Ćļź╝ ņ£äĒĢ┤ ņśüņāüņ£╝ļĪ£ļČĆĒä░ ņøĆņ¦üņØ┤ļŖö ņśüņŚŁņØä Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņČöņČ£ĒĢśņŚ¼ ĒĢ┤ļŗ╣ ņśüņŚŁņØś ĒÖöņŚ╝ ņŚ¼ļČĆļź╝ ņČöļĪĀĒĢ£ Ļ▓░Ļ│╝ļź╝ ļéśĒāĆļéĖļŗż. ņČöņČ£ļÉ£ ņśüņŚŁņØĆ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØä ĒåĄĒĢ┤ ĒĢÖņŖĄļÉ£ ļ¬©ļŹĖņŚÉ ņ×ģļĀźļÉśņ¢┤ ņČöļĪĀņØä ĒĢśĻ▓ī ļÉ£ļŗż. ņØ┤ļĢī ĒÖöņŚ╝ņ£╝ļĪ£ ĒīÉļŗ©ļÉśļ®┤ ļ╣©Ļ░äņāē ļ░öņÜ┤ļö® ļ░ĢņŖżļĪ£ ļéśĒāĆļé┤Ļ▓ī ĒĢśĻ│Ā ĒÖöņŚ╝ņØ┤ ņĢäļŗÉ Ļ▓ĮņÜ░ Ēīīļ×Ćņāē ļ░öņÜ┤ļö® ļ░ĢņŖżļĪ£ ļéśĒāĆļéśĻ▓ī ĒĢśņśĆļŗż. Fig. 16ņØĆ ņśüņāü ļé┤ņŚÉņä£ ņŚ░ĻĖ░ļź╝ Ļ▓ĆņČ£ĒĢ£ Ļ▓āņ£╝ļĪ£ ĒÖöņŚ╝ņØś ņČöļĪĀĻ│╝ ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ ņČöņČ£ļÉ£ Ļ┤Ćņŗ¼ņśüņŚŁņØ┤ ņŚ░ĻĖ░ņØ╝ Ļ▓ĮņÜ░ ļ╣©Ļ░äņāē ļ░öņÜ┤ļö® ļ░ĢņŖżļĪ£ ļéśĒāĆļé┤Ļ│Ā ņøĆņ¦üņØĖ ļ¼╝ņ▓┤Ļ░Ć ņé¼ļ×īņØ┤ļéś ļŗżļźĖ Ļ░Øņ▓┤ņØ╝ Ļ▓ĮņÜ░ņŚÉļŖö Ēīīļ×Ćņāē ļ░öņÜ┤ļö® ļ░ĢņŖżļĪ£ ļéśĒāĆļéĖļŗż.
Figs. 17Ļ│╝ 18ņØĆ ņŗżļé┤ ņĀäņ▓┤ ņśüņŚŁņŚÉ ļīĆĒĢ┤ ņŚ░ļ¼┤ņØś ĒśĢņä▒ ņŚ¼ļČĆļź╝ ņČöļĪĀĒĢ£ Ļ▓░Ļ│╝ļĪ£ņŹ©, ņśüņāüņ£╝ļĪ£ļČĆĒä░ ļ│äļÅäņØś Ļ┤Ćņŗ¼ņśüņŚŁ ņČöņČ£ņØä ĒĢśņ¦Ć ņĢŖĻ│Ā ņ×ģļĀź ņØ┤ļ»Ėņ¦ĆĻ░Ć ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉ£ ņŗżļé┤ņØĖņ¦Ć ĒīÉļŗ©ĒĢ£ Ļ▓░Ļ│╝ļź╝ ļ│┤ņŚ¼ņŻ╝Ļ│Ā ņ׳ļŗż. Fig. 17ņØĆ ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉ£ ņŗżļé┤ ņØ┤ļ»Ėņ¦ĆņØś ņČöļĪĀ Ļ▓░Ļ│╝ ņżæ ņØ╝ļČĆņØ┤ļ®░ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖļĪ£ļČĆĒä░ ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉ£ ņČöļĪĀ Ļ▓░Ļ│╝ļź╝ ļéśĒāĆļéĖļŗż. Fig. 18ņØĆ ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉśņ¦Ć ņĢŖņØĆ ņŗżļé┤ ņØ┤ļ»Ėņ¦ĆĻ░Ć ņŻ╝ņ¢┤ņĪīņØä ļĢī ņŚ░ļ¼┤Ļ░Ć ĒśĢņä▒ļÉśņ¦Ć ņĢŖņØīņØä ņČöļĪĀĒĢ£ Ļ▓░Ļ│╝ļź╝ ļ│┤ņŚ¼ņŻ╝Ļ│Ā ņ׳ļŗż.
4.4 Ļ▓ĆņČ£Ļ▓░Ļ│╝ņŚÉ ļīĆĒĢ£ ņĀĢĒÖĢļÅä ĒÅēĻ░Ć
ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØä ĒåĄĒĢ£ ĒÖöņŚ╝ ļ░Å ņŚ░ĻĖ░ ĻĘĖļ”¼Ļ│Ā ņŚ░ļ¼┤ Ļ▓ĆņČ£Ļ▓░Ļ│╝ņØś Ļ░ØĻ┤ĆņĀüņØĖ ĒÅēĻ░Ćļź╝ ņ£äĒĢ┤ Eq. (8)ņØś ņĀĢĒÖĢļÅä, Eq. (9)ņØś ņĀĢļ░ĆļÅä ĻĘĖļ”¼Ļ│Ā Eq. (10)ņØä ĒåĄĒĢ┤ Ļ▓ĆņČ£ņ£©ņØä ĻĄ¼ĒĢśņśĆļŗż.
True positive (TP)ļŖö ņśüņāü Ļ┤Ćņŗ¼ņśüņŚŁ ļé┤ņŚÉņä£ ĒÖöņ×¼Ļ░Ć ņĪ┤ņ×¼ĒĢśļŖö Ļ▓ĮņÜ░ņŚÉ ļīĆĒĢ┤ ņØĖĻ│Ąņ¦ĆļŖź ļ¬©ļŹĖņØ┤ ĒĢ┤ļŗ╣ Ļ░Øņ▓┤ļĪ£ ņś¼ļ░öļź┤Ļ▓ī ĒīÉļŗ©ĒĢ£ ĒܤņłśņŚÉ ĒĢ┤ļŗ╣ļÉśĻ│Ā, False negative (FN)ņØĆ ĒÖöņ×¼Ļ░Ć ņĪ┤ņ×¼ĒĢśņ¦Ćļ¦ī ņØĖĻ│Ąņ¦ĆļŖź ļ¬©ļŹĖņØ┤ ĒÖöņ×¼Ļ░Ć ņĢäļŗī Ļ▓āņ£╝ļĪ£ ņלļ¬╗ ĒīÉļŗ©ĒĢ£ Ļ▓ĮņÜ░ņŚÉ ĒĢ┤ļŗ╣ļÉ£ļŗż. False positive (FP)ļŖö ĒÖöņ×¼ņÖĆ Ļ┤ĆļĀ©ņØ┤ ņŚåļŖö ņśüņāüņŚÉņä£ ņØĖĻ│Ąņ¦ĆļŖź ļ¬©ļŹĖņØ┤ ĒÖöņ×¼ļĪ£ ņלļ¬╗ ĒīÉļŗ©ĒĢ£ Ļ▓ĮņÜ░, True negative (TN)ļŖö ĒÖöņ×¼Ļ░Ć ņĢäļŗī Ļ▓āņ£╝ļĪ£ ņś¼ļ░öļź┤Ļ▓ī ĒīÉļŗ©ĒĢ£ Ļ▓ĮņÜ░ņØ┤ļŗż.
Table 3ņØĆ ĒÖöņ×¼ņśüņāüņ£╝ļĪ£ļČĆĒä░ ņøĆņ¦üņ×äņØä Ļ▓ĆņČ£ĒĢśņŚ¼ ĒÖöņŚ╝ņ£╝ļĪ£ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØ┤ ņś¼ļ░öļź┤Ļ▓ī ĒīÉļŗ©ĒĢ£ ĒܤņłśņÖĆ ļ╣äĒÖöņ×¼ņśüņāüņ£╝ļĪ£ļČĆĒä░ ĒÖöņŚ╝ņ£╝ļĪ£ Ļ▓ĆņČ£ĒĢ£ Ēܤņłśļź╝ ĻĖ░ļĪØĒĢ£ Ļ▓āņØ┤ļŗż. ņśüņāü ĒĢśļéśļŗ╣ ļ¬©ļŹĖņØ┤ ņČöļĪĀĒĢ£ ņןļ®┤ļōż ņżæ 50ņןņö® ņ×äņØśļĪ£ ņäĀļ│äĒĢśņŚ¼ ņś¼ļ░öļź┤Ļ▓ī ņČöļĪĀĒĢśņśĆļŖöņ¦Ć ĒÖĢņØĖĒĢśņśĆļŗż.
ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ ņŚ░ĻĖ░Ļ░Ć ļ░£ņāØļÉśļŖö ĒÖöņ×¼ņśüņāüĻ│╝ ļ╣äĒÖöņ×¼ņśüņāüņŚÉ ļīĆĒĢ┤ņä£ļÅä 50ņןņö® ņäĀļ│äĒĢśņŚ¼ ņś¼ļ░öļź┤Ļ▓ī ņČöļĪĀĒĢśņśĆļŖöņ¦Ć Table 4ņŚÉ ĻĖ░ļĪØĒĢśņśĆļŗż. Table 5ļŖö ņŚ░ļ¼┤ ņØ┤ļ»Ėņ¦ĆņÖĆ ņŚ░ļ¼┤Ļ░Ć ņĢäļŗī ņØ┤ļ»Ėņ¦ĆņŚÉ ļīĆĒĢ£ ņČöļĪĀ Ļ▓░Ļ│╝ļź╝ ĻĖ░ļĪØĒĢśņśĆļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ Eqs. (8 - 10)ņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒÅēĻ░Ćņ¦ĆĒæ£ļōżņØä ĻĄ¼ĒĢśĻ▓ī ļÉśļ®┤ ņśüņāüņŚÉņä£ņØś ĒÖöņŚ╝Ļ░Éņ¦ĆļŖö ņĀĢĒÖĢļÅä 92%, ņĀĢļ░ĆļÅä 93% ĻĘĖļ”¼Ļ│Ā Ļ▓ĆņČ£ņ£©ņØĆ 90.8%ļź╝ ĻĖ░ļĪØĒĢśņśĆĻ│Ā, ņŚ░ĻĖ░ņØ┤ļ»Ėņ¦ĆņØś Ļ░Éņ¦Ć ņĀĢĒÖĢļÅäļŖö 87.8%, ņĀĢļ░ĆļÅäļŖö 91.3% ĻĘĖļ”¼Ļ│Ā Ļ▓ĆņČ£ņ£©ņØĆ 83.6%ļź╝ ļ│┤ņŚ¼ņŻ╝ņŚłļŗż. ĻĘĖļ”¼Ļ│Ā ņŚ░ļ¼┤Ļ░Éņ¦ĆņØś Ļ▓ĮņÜ░ļŖö ņĀĢĒÖĢļÅä 97%, ņĀĢļ░ĆļÅä 96.1% ĻĘĖļ”¼Ļ│Ā Ļ▓ĆņČ£ņ£©ņØĆ 98%ļĪ£ ļéśĒāĆļé¼ļŗż. ĒÖöņŚ╝ ļ░Å ņŚ░ĻĖ░ņØ┤ļ»Ėņ¦ĆņØś Ļ▓ĮņÜ░ ņØ┤ļ»Ėņ¦Ć ņĀäņ▓┤ņØś ĒŖ╣ņ¦ĢņØä ņØ┤ĒĢ┤ĒĢ┤ņĢ╝ ĒĢśļŖö ņŚ░ļ¼┤ņØ┤ļ»Ėņ¦Ćļ│┤ļŗż ņāüļīĆņĀüņ£╝ļĪ£ ļé«ņØĆ ņĀĢĒÖĢļÅäņÖĆ ņĀĢļ░ĆļÅäļź╝ ļ│┤ņśĆļŗż. ņØ┤ļŖö Wang et al. (2016)ņØ┤ ņĀ£ņĢłĒĢ£ ņŚ░ĻĖ░Ļ▓ĆņČ£ ļ░®ļ▓ĢņŚÉņä£ ĒÅēĻ░ĆņÜ® ņśüņāüņ£╝ļĪ£ļČĆĒä░ ĒÅēĻĘĀ 86.6%, Kong et al. (2016)ņØĆ 96%ņŚÉ ņØ┤ļź┤ļŖö ņŚ░ĻĖ░ Ļ▓ĆņČ£ņ£©ņØä ļéśĒāĆļé┤Ļ│Ā ņ׳ņ¦Ćļ¦ī, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņŚ░ĻĖ░ļ┐Éļ¦ī ņĢäļŗłļØ╝ ĒÖöņŚ╝Ļ│╝ ņŚ░ļ¼┤ ĒśĢĒā£ņØś ĒÖöņ×¼ļÅä Ļ▓ĆņČ£ņØ┤ Ļ░ĆļŖźĒĢśļ»ĆļĪ£ ļŗżņ¢æĒĢ£ ĒÖöņ×¼ ņä▒ņāüņ£╝ļĪ£ļČĆĒä░ ĒÖöņ×¼Ļ░Éņ¦ĆĻ░Ć Ļ░ĆļŖźĒĢśļŗżļŖö ņןņĀÉņØ┤ ņ׳ļŗż.
5. Ļ▓░ ļĪĀ
ņĄ£ĻĘ╝ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ĻĖ░ļ░śņØś ņØ┤ļ»Ėņ¦Ć ļČäļźśļ¬©ļŹĖļ┐Éļ¦ī ņĢäļŗłļØ╝ ņØ┤ļ»Ėņ¦Ć ļé┤ņŚÉ Ļ░Øņ▓┤ņŚÉ ļīĆĒĢ£ ņ£äņ╣śņśüņŚŁ ņĀĢļ│┤Ļ╣īņ¦Ć ņśłņĖĪĒĢśļŖö Ļ░Øņ▓┤Ļ▓ĆņČ£ ļ¬©ļŹĖļōż ļśÉĒĢ£ ĻŠĖņżĆĒ׳ Ļ░£ļ░£ļÉśĻ│Ā ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņśüņāüņ░©ļČäņØä ĒåĄĒĢśņŚ¼ ņøĆņ¦üņØ┤ļŖö Ļ░Øņ▓┤ļź╝ Ļ┤Ćņŗ¼ņśüņŚŁņ£╝ļĪ£ ņČöņČ£ĒĢśņŚ¼ ņØ┤ļź╝ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Øņ£╝ļĪ£ ĒÖöņ×¼ ņŚ¼ļČĆļź╝ ņČöļĪĀĒĢśļÅäļĪØ ĒĢśņśĆļŗż. ļö░ļØ╝ņä£ ĻĖ░ņĪ┤ Ļ░Øņ▓┤Ļ▓ĆņČ£ĻĖ░ļ▓ĢļōżņØ┤ ĒöĮņģĆ ņĀäņ▓┤ņŚÉ ļīĆĒĢ┤ Ļ░Øņ▓┤Ļ░Ć ņ׳ņØä Ļ▓āņ£╝ļĪ£ ņČöņĀĢļÉśļŖö ņ£äņ╣śņśüņŚŁņØä Ļ▓ĆņāēĒĢśļ®┤ņä£ ļ░£ņāØļÉśļŖö ĒĢśļō£ņø©ņ¢┤ņØś ņŚ░ņé░ ņåīļ¬©ļź╝ ņżäņØ╝ ņłś ņ׳ļÅäļĪØ ĒĢśņśĆļŗż.
ņØ┤ļ¤¼ĒĢ£ ņśüņāü ņĀäņ▓śļ”¼ļź╝ ĒåĄĒĢ┤ Ļ┤Ćņŗ¼ņśüņŚŁņŚÉ ļīĆĒĢ£ ĒÖöņŚ╝ ļ░Å ņŚ░ĻĖ░ Ļ▓ĆņČ£ņØä ĒĢśņśĆņ£╝ļ®░, ņČöĻ░ĆļĪ£ ņŗżņĀ£ ĒÖöņ×¼ļ░£ņāØ ņŗ£ ņ╣┤ļ®öļØ╝ ņśüņāüņŚÉņä£ ĒÖöņŚ╝ņØ┤ļéś ņŚ░ĻĖ░ņØś ņøĆņ¦üņ×äņØä Ēżņ░®ĒĢśņ¦Ć ļ¬╗ĒĢĀ ņłś ņ׳ņ£╝ļ»ĆļĪ£ ņØ┤ļź╝ ļ│┤ņÖäĒĢśĻ│Āņ×É ņĀäņ▓┤ ņśüņŚŁņŚÉ ļīĆĒĢ┤ ņŚ░ļ¼┤ ĒśĢĒā£ņØś ņŚ░ĻĖ░ ĒśĢņä▒ ņŚ¼ļČĆ ļśÉĒĢ£ Ļ▓ĆņČ£ ĒĢĀ ņłś ņ׳ļÅäļĪØ ĒĢśņśĆļŗż. ņŚ░ĻĖ░Ļ▓ĆņČ£ņØś Ļ▓ĮņÜ░ ĒÖöņŚ╝Ļ│╝ ļŗ¼ļ”¼ ļ╣øņØä Ēł¼Ļ│╝ĒĢśņŚ¼ ļ░śĒł¼ļ¬ģņĀüņØĖ ĒŖ╣ņä▒ņØ┤ ņ׳ņ£╝ļ»ĆļĪ£ Ļ░Éņ¦ĆņØś ņ¢┤ļĀżņøĆņØ┤ ņ׳Ļ│Ā, ņØ┤ļĪ£ ņØĖĒĢśņŚ¼ ĒÖöņŚ╝ņØś Ļ▓ĆņČ£ļ│┤ļŗżļŖö ļŗżņåī ņĀĢĒÖĢļÅäĻ░Ć ļ¢©ņ¢┤ņ¦ĆļŖö Ļ▓░Ļ│╝ļź╝ ļ│╝ ņłś ņ׳ņŚłļŗż. ņŚ░ĻĄ¼ ņ┤łĻĖ░ņŚÉļŖö ĒÖöņŚ╝, ņŚ░ĻĖ░, ņŚ░ļ¼┤ ņäĖ Ļ░Ćņ¦Ć ņ£ĀĒśĢ ņżæ ņśüņāüņØś ņĀäņ▓┤ ņśüņŚŁņŚÉ ļīĆĒĢ£ ĒŖ╣ņ¦ĢņØä ņØ┤ĒĢ┤ĒĢ┤ņĢ╝ ĒĢśļŖö ņŚ░ļ¼┤Ļ░Éņ¦ĆĻ░Ć Ļ░Ćņן ņĀĢĒÖĢļÅäĻ░Ć ļé«Ļ│Ā ĒĢÖņŖĄņŚÉ ņ¢┤ļĀżņøĆņØ┤ ņ׳ņØä Ļ▓āņ£╝ļĪ£ ņśłņāüĒĢśņśĆņ£╝ļéś, ĒĢÖņŖĄ Ļ│╝ņĀĢņŚÉņä£ļÅä Ļ░Ćņן ļ╣Āļź┤Ļ▓ī ļé«ņØĆ ņåÉņŗżĻ│╝ ļåÆņØĆ ņĀĢĒÖĢļÅäņŚÉ ņłśļĀ┤ĒĢśņśĆĻ│Ā, ņŗżņĀ£ Ļ▓ĆņČ£Ļ▓░Ļ│╝ņŚÉņä£ļÅä ļåÆņØĆ ņĀĢĒÖĢļÅäņÖĆ ņĀĢļ░ĆļÅäļź╝ ļ│┤ņśĆļŗż.
ņØ┤ļź╝ ĒåĄĒĢ┤ ļöźļ¤¼ļŗØ ĻĖ░ļ░śņØś ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø ļ¬©ļŹĖņØ┤ ļŗ©ņł£Ē׳ ņé¼ļ¼╝ņØś ĒśĢĒā£ļź╝ ĒĢÖņŖĄĒĢśļŖö Ļ▓āļ¦īņØ┤ ņĢäļŗī ņØ┤ļ»Ėņ¦ĆņØś ņāüĒÖ®ņØ┤ļéś ļČäņ£äĻĖ░ļź╝ ĒĢÖņŖĄĒĢśļŖö Ļ▓āņŚÉļÅä ņ£ĀņÜ®ĒĢ©ņØä ļ│┤ņŚ¼ņŻ╝ņŚłļŗż. Ē¢źĒøä ņČöĻ░ĆņĀüņØĖ ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ ļŹ░ņØ┤Ēä░ņģŗņØś ļ│┤Ļ░Ģ, ļ¬©ļŹĖņØś ņČöļĪĀ Ļ▓░Ļ│╝ņŚÉ ļīĆĒĢ£ ĒÖĢļźĀņØś ņ×äĻ│äĻ░Æ ņäżņĀĢ ņĪ░ņĀĢņØ┤ļéś ņČöĻ░ĆņĀüņØĖ ņĪ░Ļ▒┤ņØä ļČĆņŚ¼ĒĢ£ļŗżļ®┤ ļåÆņØĆ ņĀĢĒÖĢļÅäņÖĆ ņĀĢļ░ĆļÅäĻ░Ć ņśłņāüļÉ£ļŗż. ļśÉĒĢ£ ļöźļ¤¼ļŗØ ĻĖ░ļ░śņØś ĒÖöņ×¼Ļ░Éņ¦ĆĻĖ░ņłĀņØä ļō£ļĪĀĻ│╝ Ļ░ÖņØĆ ļ¼┤ņØĖļ╣äĒ¢ēņ▓┤ļź╝ ĒåĄĒĢ┤ ĒÖ£ņÜ®ĒĢ£ļŗżļ®┤ ļäōņØĆ ļ▓öņ£äņØś ņśüņŚŁņŚÉ ļīĆĒĢ┤ ĒÜ©Ļ│╝ņĀüņ£╝ļĪ£ Ļ░Éņŗ£ĒĢĀ ņłś ņ׳ņ¢┤ ĒÖöņ×¼ļĪ£ļČĆĒä░ ņ×¼ņé░Ļ│╝ ņØĖļ¬ģņØä ņ¦ĆĒéżļŖöļŹ░ Ēü░ ļÅäņøĆņØ┤ ļÉĀ Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.