1. ņä£ ļĪĀ
ļ¬©ļōĀ ĻĄ¼ņĪ░ļ¼╝ņØĆ ņŗ£Ļ░äņØ┤ ĒØÉļ”äņŚÉ ļö░ļØ╝ ņÖĖļČĆ ĒÖśĻ▓ĮņØś ņśüĒ¢źņØä ļ░øņĢä ņ×¼ļŻīņĀü, ĻĄ¼ņĪ░ņĀü ņä▒ļŖź ņĀĆĒĢśĻ░Ć ļ░£ņāØĒĢśĻ▓ī ļÉ£ļŗż. ņØ┤ļ¤¼ĒĢ£ ļģĖĒøäĒÖöļĪ£ ņØĖĒĢ┤ ĻĄ¼ņĪ░ļ¼╝ņØś ņĢłņĀäņä▒Ļ│╝ ņé¼ņÜ®ņä▒ņØ┤ Ļ░ÉņåīĒĢśĻ│Ā, Ļ▓░ĻĄŁņŚÉļŖö ĻĄ¼ņĪ░ļ¼╝ ļ│ĖņŚ░ņØś ņŚŁĒĢĀņØä ņłśĒ¢ēĒĢśņ¦Ć ļ¬╗ĒĢśļŖö ļŗ©Ļ│äņŚÉ ņØ┤ļź┤Ļ▓ī ļÉ£ļŗż. ņśłļź╝ ļōżļ®┤, 2007ļģäļÅä ļ»ĖĻĄŁ ļ»ĖļäżņåīĒāĆņŻ╝ņØś Squirt ĻĄÉļ¤ēņØĆ ļģĖĒøäļĪ£ ņØĖĒĢśņŚ¼ ļČĢĻ┤┤ ļÉśņŚłņ£╝ļ®░(Lee, 2011), 2018ļģäļÅä ņØ┤Ēāłļ”¼ņĢä ņĀ£ļģĖļ░ö ņŚÉņä£ļŖö ļģĖĒøäĒÖöļĪ£ ņØĖĒĢ£ Morandi ĻĄÉļ¤ē ļČĢĻ┤┤ņé¼Ļ│ĀļĪ£ ņØĖĒĢśņŚ¼ 60ņŚ¼ļ¬ģņØś ņé¼ņāüņ×ÉĻ░Ć ļ░£ņāØĒĢśņśĆļŗż(Lee, 2019).
ņÜ░ļ”¼ļéśļØ╝ņØś Ļ▓ĮņÜ░ 1970~1980ļģäļīĆņŚÉ ņ¦æņżæ Ļ░£ļ░£ļÉ£ ņé¼ĒÜīĻĖ░ļ░śņŗ£ņäżļ¼╝ļōżņØ┤ 30ļģä ņØ┤ņāü Ļ▓ĮĻ│╝ļÉśņ¢┤ ļģĖĒøäĒÖöļĪ£ ņØĖĒĢ£ ļ¼ĖņĀ£Ļ░Ć Ēü¼Ļ▓ī ļīĆļæÉļÉĀ ņĀäļ¦ØņØ┤ļŗż(Cha, 2016). ņŗ£ņäżļ¼╝ ņĢłņĀäļ▓Ģ ļīĆņāü ņŗ£ņäżļ¼╝ Ļ░ĆņÜ┤ļŹ░ Ļ▒┤ņäżļÉ£ ņ¦Ć 30ļģä ņØ┤ņāü ļÉ£ Ļ│ĀļĀ╣ĒÖö ņŗ£ņäżļ¼╝ņØś ļ╣äņ£©ņØĆ 1ņóģ ņŗ£ņäżļ¼╝ņØś Ļ▓ĮņÜ░ 7.7%, 2ņóģ ņŗ£ņäżļ¼╝ņØś Ļ▓ĮņÜ░ 4.4%ņØ┤ļ®░, Ē¢źĒøä ņŗ£ņäżļ¼╝ņØś ļģĖĒøäĒÖöĻ░Ć ĻĖēĻ▓®Ē׳ ņ¦äĒ¢ēļÉĀ Ļ▓āņ£╝ļĪ£ ņśłņāüļÉ£ļŗż(Kim, 2018).
ĻĄ¼ņĪ░ļ¼╝ņØś ļģĖĒøäĒÖöņŚÉ ļö░ļźĖ Ēö╝ĒĢ┤ļź╝ ņĄ£ņåīĒÖöņŗ£ĒéżĻĖ░ ņ£äĒĢ┤ ĻĄ¼ņĪ░ļ¼╝ ņĀÉĻ▓Ć ļ░Å ņ£Āņ¦ĆĻ┤Ćļ”¼ņØś ĒĢäņÜöņä▒ņØ┤ ņ”ØļīĆļÉśĻ│Ā ņ׳ļŗż. Ēśäņ×¼ ĻĄ¼ņĪ░ļ¼╝ņØś ļģĖĒøäĒÖöļź╝ ĒÅēĻ░ĆĒĢśĻ▒░ļéś ĻĄ¼ņĪ░ļ¼╝ņØä ņĀÉĻ▓ĆĒĢśļŖö ļŹ░ņŚÉļŖö ņĀäļ¼ĖĻ░ĆĻ░Ć ņ¦üņĀæ ĻĄ¼ņĪ░ļ¼╝ņØś ņāüĒā£ļź╝ ĒÖĢņØĖĒĢśĻ│Ā ĒÅēĻ░Ć ĒĢśĻ│Ā ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ņØ┤ļ¤¼ĒĢ£ ĒÅēĻ░Ć ļ░®ļ▓ĢņØĆ ņĀäļ¼ĖĻ░ĆņØś ņØśĻ▓¼ņ£╝ļĪ£ ņŻ╝Ļ┤ĆņĀüņØĖ ņÜöņåīĻ░Ć ļ¦ÄņØ┤ Ļ░£ņ×ģ ļÉĀ ļ┐Éļ¦ī ņĢäļŗłļØ╝, ņāüļŗ╣ĒĢ£ ņØĖļĀźĻ│╝ ņŗ£Ļ░äņØä ĒĢäņÜöļĪ£ ĒĢ£ļŗż.
ĻĄ¼ņĪ░ļ¼╝ņØś ļģĖĒøäĒÖö ņāüĒā£ļź╝ ĒīīņĢģĒĢśļŖö ņ×ÉļÅÖĒÖö ĻĖ░ņłĀļĪ£ Ļ░Ćņן ļ¦ÄņØ┤ ņé¼ņÜ®ļÉśĻ│Ā ņ׳ļŖö ĻĖ░ņłĀņØĆ ņ¦äļÅÖ ĻĖ░ļ░ś ĻĄ¼ņĪ░ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦ü(Structure Health Monitoring)ņØ┤ļŗż. ņ¦äļÅÖ ĻĖ░ļ░ś ĻĄ¼ņĪ░ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦ü ĻĖ░ņłĀņØĆ ĻĄ¼ņĪ░ļ¼╝ņŚÉ Ļ░ĆņåŹļÅäĻ│ä ļō▒ņØś ņä╝ņä£ļź╝ ļČĆņ░®ĒĢśņŚ¼ ņ¦äļÅÖņØä ņĖĪņĀĢĒĢśĻ│Ā, ņØ┤ ņĀĢļ│┤ļĪ£ļČĆĒä░ ĻĄ¼ņĪ░ļ¼╝ņØś ņāüĒā£ļź╝ ĒīīņĢģĒĢśļŖö ĻĖ░ņłĀņØ┤ļŗż. ņĄ£ĻĘ╝ņŚÉļÅä ņ¦äļÅÖĻĖ░ļ░ś ĻĄ¼ņĪ░ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦üņŚÉ ņŗĀĒśĖņ▓śļ”¼ņÖĆ ņ╣╝ļ¦ī ĒĢäĒä░ ļō▒ņØä ĒÖ£ņÜ®ĒĢśļŖö ļō▒ Ļ┤ĆļĀ© ņŚ░ĻĄ¼Ļ░Ć ĒÖ£ļ░£ĒĢśĻ▓ī ņłśĒ¢ēļÉśĻ│Ā ņ׳ļŗż(Amezquita-Sanchez and Adeli, 2016; Erazo et al., 2019). Juang and Pappa (1985)ļŖö ĻĄÉļ¤ē ļō▒ņØś ĻĄ¼ņĪ░ļ¼╝ņŚÉņä£ ņ¦äļÅÖņØä ņĖĪņĀĢĒĢ£ ņĀĢļ│┤ļź╝ ņŚŁĒĢ┤ņäØĒĢśņŚ¼ ĻĄ¼ņĪ░ļ¼╝ņØś ņŗ£ņŖżĒģ£ņØä ņśłņĖĪĒĢśļŖö ņŗ£ņŖżĒģ£ ņŗØļ│ä ņĢīĻ│Āļ”¼ņ”ś Eigensystem Realization Algorithm (ERA)ņØä Ļ░£ļ░£ĒĢśņśĆĻ│Ā, Bernal (2002)ņØĆ ĻĄ¼ņĪ░ļ¼╝ņØś ņåÉņāü ņ£äņ╣śļź╝ ņ×ÉļÅÖņ£╝ļĪ£ ņ░ŠņĢäļé┤ļŖö Damage Localization Vector (DLV) ņĢīĻ│Āļ”¼ņ”śņØä Ļ░£ļ░£ĒĢśņśĆņ£╝ļ®░, ņØ┤ļ¤¼ĒĢ£ ņĢīĻ│Āļ”¼ņ”śļōżņØä ņ¦äļÅäļīĆĻĄÉ ļō▒ ņŗżņĀ£ ĻĄÉļ¤ēņŚÉ ņĀüņÜ®ĒĢ£ ņŚ░ĻĄ¼ ņé¼ļĪĆļōżļÅä ņ׳ļŗż(Jang et al., 2010).
ĻĄ¼ņĪ░ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦ü ĻĖ░ņłĀņØĆ ļÅÖņĀüĒĢśņżæ ņĖĪņĀĢ ņ£Āļ¼┤ņŚÉ ļö░ļØ╝ Ēü¼Ļ▓ī Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓Ģ(Output-Only Method)ņÖĆ ĒĢśņżæ-Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓Ģ(Input-Ouput Method)ļĪ£ ĻĄ¼ļČä ĒĢĀ ņłś ņ׳ļŗż. Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓ĢņØĆ InputņØĖ ļÅÖņĀü ĒĢśņżæņØä ļ░▒ņāē ņåīņØī(White Noise)ņ£╝ļĪ£ Ļ░ĆņĀĢĒĢśĻ│Ā OutputņØĖ ļÅÖņĀü Ļ▒░ļÅÖ ņĀĢļ│┤ļ¦īņØä ņĖĪņĀĢĒĢśņŚ¼ ņØ┤ņÜ®ĒĢśļŖö ĻĖ░ņłĀņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ņĀĢĒÖĢļÅäņŚÉ ļ¼ĖņĀ£ņĀÉņØ┤ ļ░£ņāØĒĢ£ļŗż. ļ░śļ®┤ņŚÉ ĒĢśņżæ-Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓ĢņØĆ ĻĄ¼ņĪ░ļ¼╝ņŚÉ Ļ░ĆĒĢ┤ņ¦ĆļŖö ļÅÖņĀü ĒĢśņżæĻ│╝ ļÅÖņĀü Ļ▒░ļÅÖņØä ļ¬©ļæÉ ņĖĪņĀĢĒĢśņŚ¼ ļ¬©ļŗłĒä░ļ¦üņŚÉ ņØ┤ņÜ®ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓Ģ ļ│┤ļŗż ļåÆņØĆ ņĀĢĒÖĢļÅäļź╝ ņ¢╗ņØä ņłś ņ׳ļŖö ņןņĀÉņØ┤ ņ׳ļŗż.
ņØ┤ļ¤¼ĒĢ£ ņןņĀÉņŚÉļÅä ļČłĻĄ¼ĒĢśĻ│Ā ļīĆļČĆļČäņØś ļ¬©ļŗłĒä░ļ¦ü ņŚ░ĻĄ¼ņŚÉņä£ļŖö Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓ĢņØ┤ ļäÉļ”¼ ņé¼ņÜ®ļÉ£ļŗż. ņØ┤ļŖö Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓ĢņØ┤ ļŹö ņĀĢĒÖĢĒĢśĻĖ░ ļĢīļ¼ĖņØ┤ ņĢäļŗłļØ╝ Input ņĖĪņĀĢņØ┤ ņ¢┤ļĀĄĻĖ░ ļĢīļ¼ĖņØ┤ļŗż. ņØ╝ļ░śņĀüņ£╝ļĪ£ InputņØś ņĖĪņĀĢņØä ņ£äĒĢ┤ ĒĢ┤ļ©Ė(Hammer) ļō▒ņØä ĒÖ£ņÜ®ĒĢ£ ņČ®Ļ▓® ņ×¼ĒĢś ņŗżĒŚś(Impact Loading) ļ░®ļ▓ĢņØ┤ ņé¼ņÜ®ļÉśņ¦Ćļ¦ī, ļ│äļÅäņØś ņןļ╣äĻ░Ć ĒĢäņÜöĒĢśĻ▒░ļéś, ņĖĪņĀĢņØä ņ£äĒĢ┤ ĻĄÉĒåĄ ĒåĄņĀ£ļź╝ ĒĢäņÜöļĪ£ ĒĢśļŖö Ļ▓ĮņĀ£ņĀüņØĖ ĒĢ£Ļ│äļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗż.
ņĄ£ĻĘ╝ ļööņ¦ĆĒäĖ ņśüņāüĻĖ░ĻĖ░ņÖĆ ņśüņāü ņ▓śļ”¼ ĻĖ░ņłĀņØ┤ ĻĖēņåŹļÅäļĪ£ ļ░£ņĀäĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ņØ┤ļ¤¼ĒĢ£ ĻĖ░ņłĀļōżņØĆ ņŗ£ņäżļ¼╝ ņĀÉĻ▓Ć, ņ¦äļŗ© ļ░Å ņ×¼ļé£ ņĢłņĀä ļČäņĢ╝, CCTVļź╝ ņØ┤ņÜ®ĒĢ£ Ēśäņן Ļ┤Ćļ”¼ ļ░Å ņ×¼ļé£ Ļ░Éņ¦Ć/ļīĆņØæ, ĻĄ¼ņĪ░ļ¼╝ņØś ĻĘĀņŚ┤ ņāüĒā£ ņĀÉĻ▓Ć, ĻĘĖļ”¼Ļ│Ā ļÅÖņĀü ļ│Ćņ£ä ņĖĪņĀĢņŚÉļÅä ņé¼ņÜ®ļÉśĻ│Ā ņ׳ļŗż(Park et al., 2014; Yoon et al., 2016). ņØ┤ļ¤¼ĒĢ£ ņśüņāü ĻĖ░ļ▓ĢļōżņØä ĒÖ£ņÜ®ĒĢśļ®┤ ĻĄ¼ņĪ░ļ¼╝ņØś Ļ░ĆĒĢ┤ņ¦ĆļŖö ļÅÖņĀü ĒĢśņżæņØä ņśłņĖĪĒĢśļŖöļŹ░ Ēü¼Ļ▓ī ļÅäņøĆņØ┤ ļÉĀ Ļ▓āņ£╝ļĪ£ Ļ│ĀļĀżļÉśļéś, ņĢäņ¦üĻ╣īņ¦Ć ņśüņāüĻĖ░ļ▓ĢļōżņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ĻĄ¼ņĪ░ļ¼╝ņØś ļÅÖņĀü ĒĢśņżæņØä ņśłņĖĪĒĢśļŖö ņŚ░ĻĄ¼ļŖö ļ»Ėļ╣äĒĢ£ Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż.
Ļ░ĆņåŹļÅä ņĖĪņĀĢĻ│╝ ĻĄ¼ņĪ░ļ¼╝ņØś ļ│ĆĒśĢļźĀņØä ņØ┤ņÜ®ĒĢśļŖö ļō▒ ņä╝ņä£ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ĒĢśņżæņØś ņ£äņ╣śļź╝ ĻĄ¼ņĪ░ļ¼╝ņØś ĻĄ¼ļÅÖņ£╝ļĪ£ļČĆĒä░ ņśłņĖĪĒĢśļŖö ņŚ░ĻĄ¼ļŖö ņłśĒ¢ēļÉśņ¢┤ ņÖöļŗż(Cho et al., 2007). ĒĢśņ¦Ćļ¦ī System IdentificationņØä ņ£äĒĢ£ ĒĢśņżæņØś ņ£äņ╣śļŖö ļīĆļČĆļČä ņśüņāü ņĀĢļ│┤ļĪ£ļČĆĒä░ ņé¼ņÜ®ņ×ÉĻ░Ć ļīĆļץņĀüņØĖ ņ£äņ╣śļź╝ ņČöņĀĢĒĢśĻ│Ā ņ׳ļŗż. ļÅÖņØ╝ĒĢ£ ĒĢśņżæņØ┤ļØ╝ļÅä Ļ░ĆĒĢ┤ņ¦ĆļŖö ņ£äņ╣śņŚÉ ļö░ļØ╝ ĻĄ¼ņĪ░ļ¼╝ņØ┤ ļ│┤ņØ┤ļŖö Ļ▒░ļÅÖņØĆ ļ¦żņÜ░ ļŗ¼ļØ╝ņ¦ĆĻĖ░ ļĢīļ¼ĖņŚÉ ĒĢśņżæņØś ņ£äņ╣śļź╝ ņČöņĀĢĒĢśļŖö Ļ▓āņØĆ ĒĢśņżæ-Ļ▒░ļÅÖ ņĖĪņĀĢ ĻĖ░ļ░ś ļ░®ļ▓ĢņŚÉņä£ ļ¦żņÜ░ ņżæņÜöĒĢśļŗż.
ļö░ļØ╝ņä£ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņśüņāüĻĖ░ļ▓ĢņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ĻĄ¼ņĪ░ļ¼╝ņŚÉ Ļ░ĆĒĢ┤ņ¦ĆļŖö ļÅÖņĀü ĒĢśņżæņŚÉ ļīĆĒĢ£ ņ£äņ╣śņĀĢļ│┤ļź╝ ņĖĪņĀĢĒĢśĻ│Āņ×É ĒĢ£ļŗż. ņČöĻ░ĆņĀüņØĖ Ļ│ĀĻ░ĆņØś ņןļ╣äļéś ņŗżĒŚś ļō▒ņØä ĒĢäņÜöļĪ£ ĒĢśņ¦Ć ņĢŖĻ│Ā, ņāüņÜ®ĒÖöļÉ£ ņ╣┤ļ®öļØ╝ļ¦īņØä ĒÖ£ņÜ®ĒĢ£ ļ¬©ņģśņä╝ņŗ▒ ĻĖ░ļ▓ĢņØä Ļ░£ļ░£ĒĢśņŚ¼ ļ│┤ļŗż ĒÄĖļ”¼ĒĢśĻ│Ā Ļ▓ĮņĀ£ņĀüņ£╝ļĪ£ ņĖĪņĀĢ ļ░Å ļČäņäØņØä ņłśĒ¢ē ĒĢĀ ņłś ņ׳Ļ│Ā, ĻĄ¼ņĪ░ļ¼╝ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦üņŚÉ ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļÅäļĪØ ĒĢśĻ│Āņ×É ĒĢ£ļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļ╣äĻĄÉņĀü ļÅÖņĀü ĒĢśņżæņŚÉ ņóģļźśĻ░Ć ļŗ©ņł£ĒĢ£ ļ│┤ļÅäĻĄÉļź╝ ļīĆņāüņ£╝ļĪ£ ĒĢśņśĆņ£╝ļ®░, ļ│┤ļÅäĻĄÉņØś Ļ░Ćņן ļīĆĒæ£ņĀüņØĖ ļÅÖņĀü ĒĢśņżæņØĖ ļ│┤Ē¢ēņ×ÉņØś ņ£äņ╣śņĀĢļ│┤ļź╝ ņĖĪņĀĢĒĢśĻ│Āņ×É ĒĢ£ļŗż.
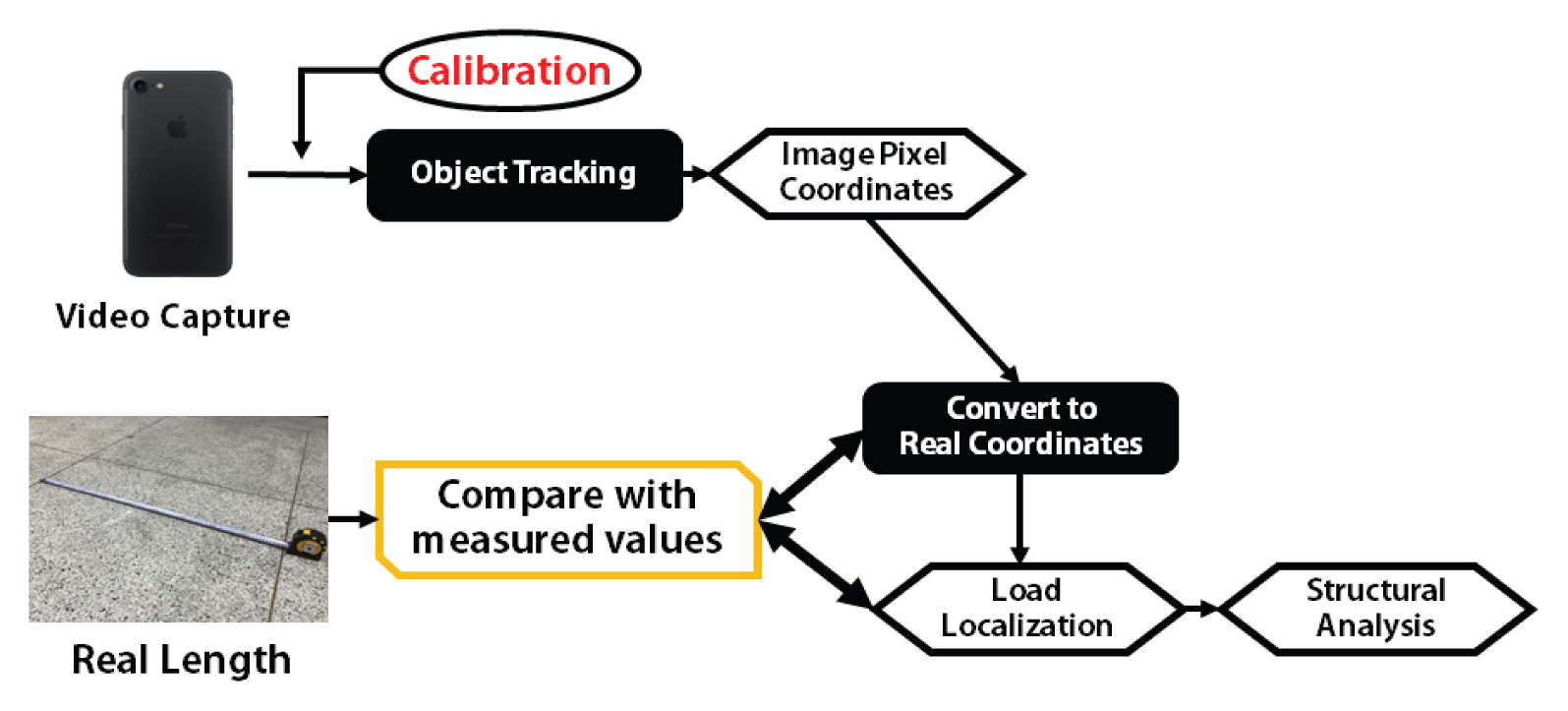
ļ│Ėļ¼ĖņŚÉņä£ļŖö ņśüņāüĻĖ░ļ░ś ļ¬©ņģśņä╝ņŗ▒ ĻĖ░ļ▓ĢņØä (1) Ļ░Øņ▓┤ ņČöņĀü(Object Tracking)Ļ│╝ (2) ņóīĒæ£Ļ│ä ļ│ĆĒÖś ļ░Å ņ£äņ╣śņØĖņŗØņØś ļæÉ ĒöäļĪ£ņäĖņŖżļĪ£ ļéśļłäņ¢┤ ņäżļ¬ģĒĢśņśĆņ£╝ļ®░, Ļ▓Ćņ”Ø ņŗżĒŚś, Ļ▓░Ļ│╝ ļČäņäØĻ│╝ ĒåĀņØś, ĻĘĖļ”¼Ļ│Ā ļ¦łņ¦Ćļ¦ē Ļ▓░ļĪĀ ņł£ņ£╝ļĪ£ ĻĖ░ņłĀĒĢśņśĆļŗż.
2. ņśüņāüĻĖ░ļ░ś ņ£äņ╣śņĀĢļ│┤ ņĖĪņĀĢņŗ£ņŖżĒģ£
2.1 ņŗ£ņŖżĒģ£ Ļ░£ņÜö
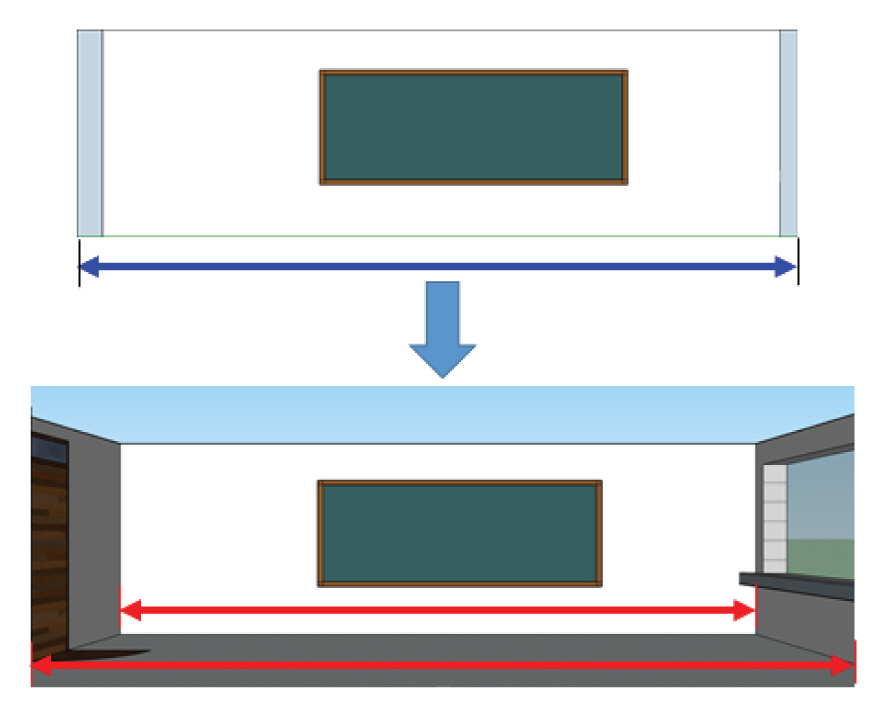
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņĀ£ņŗ£ĒĢśļŖö ņĀäņ▓┤ ņŗ£ņŖżĒģ£ņØś Ļ░£ņÜöļŖö ļŗżņØīĻ│╝ Ļ░Öļŗż(Fig. 1). ņāüņÜ® ņ╣┤ļ®öļØ╝ļéś ņŖżļ¦łĒŖĖĒÅ░ņ£╝ļĪ£ ņ┤¼ņśüļÉ£ ņśüņāüņŚÉ Ļ░Øņ▓┤ ņČöņĀü ņĢīĻ│Āļ”¼ņ”śņØä ņĀüņÜ®, ĻĄ¼ņĪ░ļ¼╝ ņ£äņŚÉņä£ ņøĆņ¦üņØ┤ļŖö Ļ░Øņ▓┤ļź╝ ņ¦ĆņåŹņĀüņ£╝ļĪ£ ņČöņĀüĒĢ£ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ņä£ ņśüņāü ĒöäļĀłņ×äņŚÉņä£ ĒöĮņģĆ(Pixel)ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ä ņóīĒæ£ ņĀĢļ│┤ļź╝ ņ¢╗ņØä ņłś ņ׳ļŗż. ņśüņāü ļé┤ņŚÉņä£ ņØ┤ļ»Ė ĻĖĖņØ┤ļź╝ ņĢīĻ│Ā ņ׳ļŖö ļ¼╝ņ▓┤ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņØ┤ļ»Ėņ¦Ć ņóīĒæ£Ļ│äņŚÉņä£ ņŗżņĀ£ ņóīĒæ£Ļ│äļĪ£ ļ│ĆĒÖśĒĢśļŖö ļ╣äņ£©ņØä ņ¢╗ņØä ņłś ņ׳ļŖöļŹ░, ņØ┤ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņ£äņŚÉņä£ ņ¢╗ņØĆ ņóīĒæ£ļź╝ ļ│ĆĒÖś, ĻĄ¼ņĪ░ļ¼╝ņŚÉ Ļ░ĆĒĢ┤ņ¦ĆļŖö ļÅÖņĀü ĒĢśņżæņØś ņ£äņ╣śļĪ£ ņé░ņĀĢĒĢ£ļŗż.
2.2 Ļ░Øņ▓┤ ņČöņĀü
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ Ļ░£ļ░£ĒĢ£ ņŗ£ņŖżĒģ£ņØś ņ▓½ ļ▓łņ¦Ė ļŗ©Ļ│äļŖö ņ┤¼ņśüĒĢ£ ļ╣äļööņśżļĪ£ļČĆĒä░ ļÅÖņĀü ĒĢśņżæņŚÉ ĒĢ┤ļŗ╣ļÉśļŖö Ļ░Øņ▓┤ļź╝ ņČöņĀü(Object Tracking)ĒĢśļŖö ļŗ©Ļ│äņØ┤ļŗż. Ļ░Øņ▓┤ ņČöņĀüņØĆ ņāüņÜ® ņ╣┤ļ®öļØ╝ļéś ņŖżļ¦łĒŖĖĒÅ░ ļō▒ņ£╝ļĪ£ ĻĖ░ ņ┤¼ņśüļÉ£ ņśüņāüņØä Ēøäņ▓śļ”¼ Ļ│╝ņĀĢņØä ĒåĄĒĢ┤ ņČöņĀüĒĢśĻ▒░ļéś, ņŗżņŗ£Ļ░äņ£╝ļĪ£ ņ┤¼ņśüļÉśĻ│Ā ņ׳ļŖö ņśüņāüņØä ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļÅäļĪØ ĻĄ¼ĒśäĒĢśņśĆļŗż.
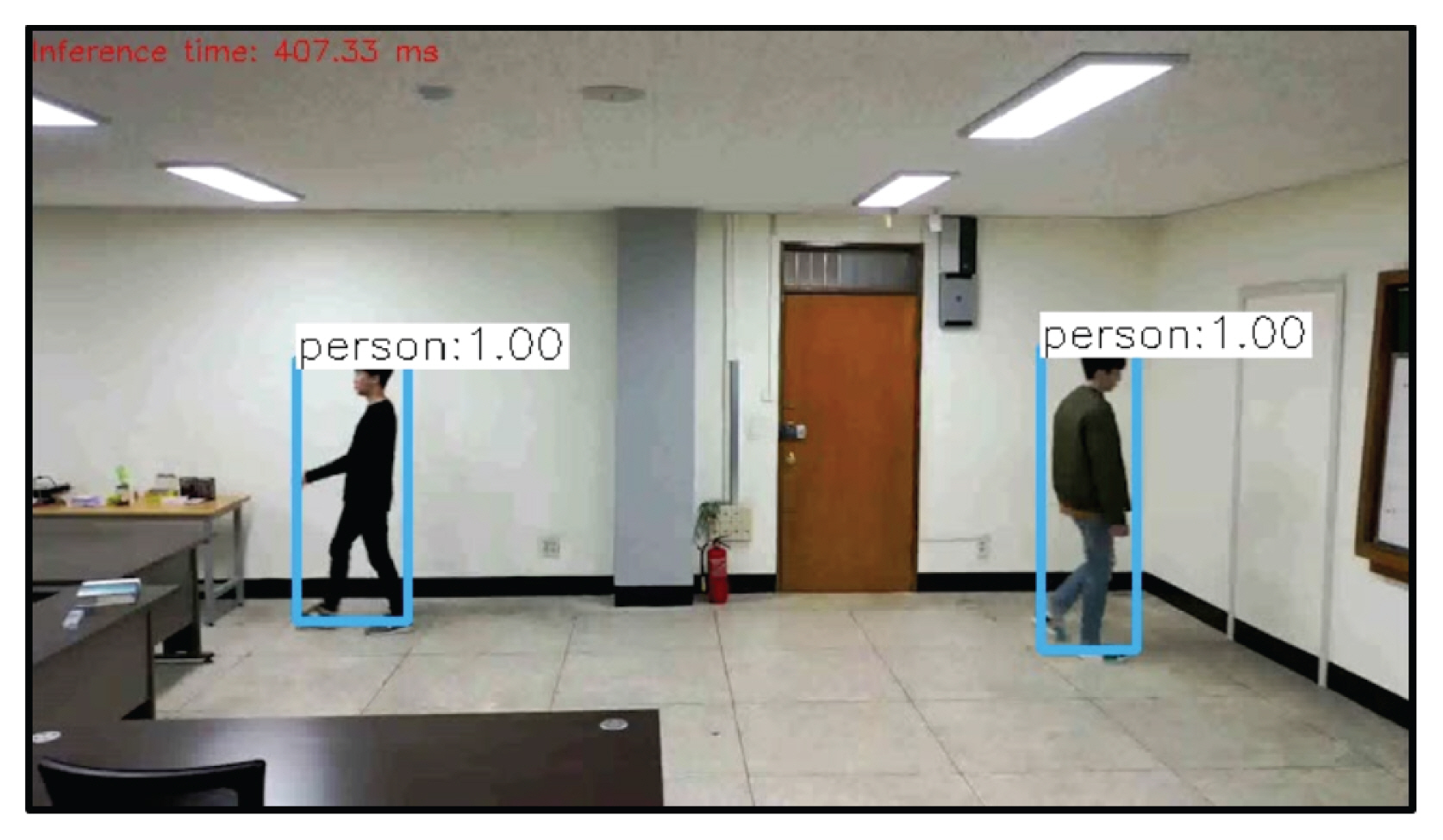
ņśüņāüņ▓śļ”¼ ĻĖ░ņłĀ ņżæņŚÉņä£ Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ ņśłņĖĪĒĢĀ ņłś ņ׳ļŖö ļ░®ļ▓Ģņ£╝ļĪ£ļŖö Ēü¼Ļ▓ī Ļ░Øņ▓┤ Ļ▓ĆņČ£(Object Detection)ĻĖ░ļ▓Ģ, ņ£Āņé¼ ĒŖ╣ņ¦ĢņĀÉ ĒāÉņ¦Ć(Feature Matching)ĻĖ░ļ▓ĢĻ│╝ ņČöņĀü(Tracking) ĻĖ░ļ▓Ģ ļō▒ņØ┤ ņ׳ļŗż. Ļ░Øņ▓┤ Ļ▓ĆņČ£ ĻĖ░ļ▓ĢņØĆ ļöźļ¤¼ļŗØ(Deep-Learning) ļō▒ņØś ņØĖĻ│Ąņ¦ĆļŖź ĻĖ░ņłĀņØä ņØ┤ņÜ®ĒĢśņŚ¼ Ļ▓ĆņČ£ĒĢśĻ│Āņ×É ĒĢśļŖö Ļ░Øņ▓┤ļź╝ ļ»Ėļ”¼ ĒĢÖņŖĄņŗ£Ēé© Ēøä ĒĢÖņŖĄļÉ£ ļ¬©ļŹĖņØä ĒåĄĒĢ┤ ņśüņāüņŚÉņä£ Ļ░Øņ▓┤ņØś ņóģļźśņÖĆ ņ£äņ╣śļź╝ Ļ▓ĆņČ£ĒĢ┤ļé┤ļŖö ļ░®ņŗØņØ┤ļŗż. Redmon et al. (2016)ņØ┤ ņĀ£ņŗ£ĒĢ£ YOLO (You Look Only Once) Ļ░Øņ▓┤ Ļ▓ĆņČ£ ņĢīĻ│Āļ”¼ņ”śņØś Ļ▓ĮņÜ░ 1ņןņØś ĒöäļĀłņ×äņØä ņ▓śļ”¼ĒĢśļŖöļŹ░ ņĢĮ 400 ms (millisecond), ņ”ē 2.5 FPS (frames per second) ņØś ņ▓śļ”¼ņåŹļÅäļź╝ ļéśĒāĆļé┤ņŚłļŗż(Fig. 2).
ņ£äņØś Ļ▓░Ļ│╝ņÖĆ Ļ░ÖņØ┤ Ļ░Øņ▓┤ Ļ▓ĆņČ£ ņĢīĻ│Āļ”¼ņ”śņØĆ ļ»Ėļ”¼ ĒĢÖņŖĄļÉ£ Ļ░Øņ▓┤Ļ░Ć ņĢäļŗī Ļ▓ĮņÜ░ Ļ▓ĆņČ£ņØ┤ ļČłĻ░ĆļŖźĒĢśĻ│Ā, ĒĢÖņŖĄĻ│╝ Ļ░Øņ▓┤ļź╝ Ļ▓ĆņČ£ĒĢśļŖö Ļ│╝ņĀĢņŚÉņä£ ļ¦ÄņØĆ ņŚ░ņé░ņØ┤ ĒĢäņÜöĒĢ©ņŚÉ ļö░ļØ╝ ļ¦żņÜ░ ļé«ņØĆ ņ▓śļ”¼ņåŹļÅäļź╝ ļ│┤ņŚ¼ ņŗżņŗ£Ļ░ä ņśüņāüņŚÉ ņĀüņÜ®ĒĢśĻĖ░ņŚö ņ¢┤ļĀżņÜĖ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż. ņ£Āņé¼ ĒŖ╣ņ¦ĢņĀÉ ĒāÉņ¦Ć ĻĖ░ļ▓ĢņØĆ ņśüņāüņØś ļ¦ż ĒöäļĀłņ×äļ¦łļŗż ņśüņāü ņĀäņ▓┤ ļČĆļČäņŚÉ ļīĆĒĢśņŚ¼ ĒŖ╣ņ¦ĢņĀÉ(Feature)ļōżņØä ņČöņČ£ĒĢśĻ│Ā ĒöäļĀłņ×äĻ░äņØś ĒŖ╣ņ¦ĢņĀÉļōżņØś ņ£Āņé¼ļÅäļź╝ Ļ│äņé░ĒĢśņŚ¼ ņČöņĀüĒĢśļŖö ļ░®ļ▓Ģņ£╝ļĪ£ ļ¦ÄņØĆ ņŚ░ņé░ Ļ│╝ņĀĢņØ┤ ņłśļ░śļÉśļŖö ņ¢┤ļĀżņøĆņØ┤ ņ׳ļŗż. ņØ┤ņŚÉ ļ░śĒĢ┤ ņČöņĀü ĻĖ░ļ▓ĢņØĆ ĻĖ░ņżĆņØ┤ ļÉśļŖö ĒöäļĀłņ×äņŚÉņä£ ĒŖ╣ņ¦ĢņĀÉņØä ĒĢ£ļ▓łļ¦ī ņČöņČ£ĒĢśņŚ¼ Ļ░ü ĒŖ╣ņ¦ĢņĀÉņØś ļ¬©ņ¢æ, ņøĆņ¦üņ×äņØś ļ░®Ē¢źĻ│╝ ņåŹļÅä ņĀĢļ│┤ļź╝ Ļ░Ćņ¦ĆĻ│Ā ļŗżņØī ĒöäļĀłņ×äņŚÉņä£ņØś Ļ░Øņ▓┤ ņ£äņ╣śļź╝ ņśłņĖĪĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņāüļīĆņĀüņ£╝ļĪ£ ļŹö ļ╣ĀļźĖ ņŚ░ņé░ņØ┤ Ļ░ĆļŖźĒĢśļŗż. ļśÉĒĢ£ Ļ░Øņ▓┤Ļ░Ć ļŗżļźĖ Ļ░Øņ▓┤ļéś ĻĄ¼ņĪ░ļ¼╝ ļō▒ņŚÉ Ļ░ĆļĀżņĪīņØä ļĢī Ļ░Øņ▓┤ Ļ▓ĆņČ£ņØ┤ļéś ņ£Āņé¼ ĒŖ╣ņ¦ĢņĀÉ ĒāÉņ¦Ć ĻĖ░ļ▓ĢņØś Ļ▓ĮņÜ░ ņ░ŠņĢäļāłļŹś Ļ░Øņ▓┤ļź╝ ņāüņŗżĒĢśņ¦Ćļ¦ī, ņČöņĀü ĻĖ░ļ▓ĢņØś Ļ▓ĮņÜ░ ĻĖ░ņĪ┤ ņĀĢļ│┤ļź╝ Ļ░Ćņ¦ĆĻ│Ā Ļ░ĆļĀżņ¦ä Ļ░Øņ▓┤ņØś ņ£äņ╣śņĀĢļ│┤ļź╝ ņśłņĖĪ, Ļ░äņ¦üĒĢĀ ņłś ņ׳ĻĖ░ņŚÉ ĒĢśņżæņØś ņ£äņ╣śļź╝ ņ£Āņ¦ĆĒĢĀ ņłś ņ׳ļŗż.
ļö░ļØ╝ņä£ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņČöņĀü ĻĖ░ļ▓ĢņØä ņé¼ņÜ®ĒĢśņśĆņ£╝ļ®░, Fig. 3Ļ│╝ Ļ░ÖņØ┤ ņŚ░ĻĄ¼ņØś ļ¬®Ēæ£ņŚÉ ņĀüĒĢ®ĒĢ£ ņČöņĀü ĻĖ░ļ▓ĢņØä ņäĀĒāØĒĢśĻĖ░ ņ£äĒĢ┤ ņČöņĀü ĻĖ░ļ▓ĢļōżņØś ņä▒ļŖźņØä ļ╣äĻĄÉĒĢśņśĆļŗż. ņŚ¼ļ¤¼ ņśüņāüņŚÉ Ļ░üĻ░ü ļÅÖņØ╝ĒĢ£ ROIļź╝ ņĀüņÜ®ĒĢśņśĆĻ│Ā, ņ┤łļŗ╣ ņ▓śļ”¼ņåŹļÅä(FPS)ļź╝ Ēæ£ĻĖ░ĒĢśĻ│Ā ņČöņĀü ņä▒Ļ│Ą ņŚ¼ļČĆļź╝ ļéśĒāĆļé┤ļŖö ņĢīĻ│Āļ”¼ņ”śņØä ņČöĻ░ĆĒĢśņŚ¼ ņ▓śļ”¼ņåŹļÅäņÖĆ ņČöņĀü ņä▒Ļ│ĄļźĀņØä ĒÅēĻ░ĆĒĢśņśĆļŗż. ĒĢ┤ņāüļÅäņŚÉ ļö░ļźĖ Ļ▓░Ļ│╝ļź╝ ļ╣äĻĄÉĒĢśĻĖ░ ņ£äĒĢ┤ Ļ░ÖņØĆ ņśüņāüņØä ĒĢ┤ņāüļÅäļź╝ ļŗżļź┤Ļ▓ī ĒĢśņŚ¼ ņČöĻ░Ć ņŗżĒŚśņØä ņ¦äĒ¢ēĒĢśņśĆņ£╝ļ®░ ņŗĀļó░ļÅäļź╝ ļåÆņØ┤ĻĖ░ ņ£äĒĢ┤ Ļ░ü ņśüņāüņŚÉ ļīĆĒĢ┤ ļ░śļ│Ą ņŗżĒŚśņ£╝ļĪ£ ļÅäņČ£ļÉ£ Ļ▓░Ļ│╝ņØś ĒÅēĻĘĀĻ░ÆņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņŗżĒŚśņŚÉ ņé¼ņÜ®ļÉ£ ņśüņāü(Fig. 4)ņØĆ Ļ░ü ņČöņĀü ĻĖ░ļ▓ĢņØ┤ ļŗżņ¢æĒĢ£ ņāüĒÖ®ņŚÉņä£ ņĀüņĀłĒĢ£ ņä▒ļŖźņØä ļ░£Ē£śĒĢśļŖöņ¦Ć ņĢīņĢäļ│┤ĻĖ░ ņ£äĒĢ┤ Ļ░Øņ▓┤ ņØ┤ļÅÖ Ļ▓ĮļĪ£ ņāüņŚÉ ļ░░Ļ▓ĮņØś ņāē, ĒśĢĒā£ ļō▒ņØś Intensity Ļ░Ć ĻĖēĻ▓®ĒĢśĻ▓ī ļ│ĆĒÖöĒĢśļŖö ņśüņāüĻ│╝, ņČöņĀüĒĢśļŖö Ļ░Øņ▓┤Ļ░Ć ļŗżļźĖ ņØ┤ļÅÖĒĢśļŖö Ļ░Øņ▓┤ņŚÉ ņØśĒĢ┤ Ļ░ĆļĀżņ¦ĆļŖö ņśüņāü ļō▒ņØä ņØ┤ņÜ®ĒĢśņśĆļŗż.
ņł£ĒÖśĒ¢ēļĀ¼ņØś ĒŖ╣ņä▒ņØä ņØ┤ņÜ®ĒĢ£ Kernelized Correlation Filters (KCF) ņĢīĻ│Āļ”¼ņ”ś(Henriques et al., 2014) ņØś Ļ▓ĮņÜ░ ļåÆņØĆ ņ▓śļ”¼ņåŹļÅäļź╝ ļ│┤ņśĆņ£╝ļéś ņČöņĀü ņżæņØ┤ļŹś Ļ░Øņ▓┤ņØś ļ░░Ļ▓ĮņØ┤ ĻĖēĻ▓®ĒĢśĻ▓ī ļ│ĆĒÖöĒĢśļŖö Ļ▓ĮņÜ░ļéś Ļ░Øņ▓┤Ļ░Ć Ļ░ĆļĀżņ¦ĆļŖö Ļ▓ĮņÜ░ ņČöņĀü ņżæņØ┤ļŹś Ļ░Øņ▓┤ļź╝ ņāüņŗżĒĢśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ╣łļ▓łĒĢśĻ▓ī ļ░£ņāØ ĒĢśņśĆļŗż. ļ¼╝ņ▓┤ņØś Ēśäņ×¼ ņ£äņ╣śņÖĆ ņŻ╝ļ│Ć ņ£äņ╣śĻ╣īņ¦Ć Positive exampleļĪ£ Ļ│ĀļĀż, ļŗżņżæ ņØĖņŖżĒä┤ņŖż ĒĢÖņŖĄņØä ĒåĄĒĢ┤ ļ¼╝ņ▓┤ļź╝ ņČöņĀüĒĢśļŖö Multiple Instance Learning (MIL) ņĢīĻ│Āļ”¼ņ”ś(Babenko et al., 2009)ņØĆ ĒĢ┤ņāüļÅäņŚÉ ļö░ļźĖ ņä▒ļŖź ĒÄĖņ░©Ļ░Ć ļČłĻĘ£ņ╣ÖĒĢśĻ▓ī ļ░£ņāØĒĢśņśĆĻ│Ā, ļé«ņØĆ ņ▓śļ”¼ņåŹļÅäļź╝ ļ│┤ņŚ¼ņŻ╝ņŚłļŗż. ņĀüņØæĒśĢ ņāüĻ┤Ć ĒĢäĒä░ļź╝ ņØ┤ņÜ®ĒĢ£ Minimum Output Sum of Squared Error (MOSSE) ņĢīĻ│Āļ”¼ņ”ś(Bolme et al., 2010)ņØĆ ļ¦żņÜ░ ļ╣ĀļźĖ ņ▓śļ”¼ņåŹļÅäņÖĆ ņżĆņłśĒĢ£ ņČöņĀü ņä▒Ļ│ĄļźĀņØä ļ│┤ņśĆņ£╝ļéś, ņČöņĀü ņżæņØ┤ļŹś Ļ░Øņ▓┤Ļ░Ć Ļ░ĆļĀżņ¦ĆļŖö Ļ▓ĮņÜ░ņŚÉ ņä▒ļŖźņØ┤ ĻĖēĻ▓®ĒĢśĻ▓ī ĒĢśļØĮĒĢśļŖö ļ¬©ņŖĄņØä ļ│┤ņśĆļŗż. Ļ┤Ćņŗ¼ ņśüņŚŁ(Region of Interest, ROI)ņ£╝ļĪ£ ņäżņĀĢĒĢ£ Ļ░Øņ▓┤ņØś Ļ░Ćņżæņ╣ś(Weight)ļź╝ MappingĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£ ņ×æļÅÖĒĢśļŖö Channel and Spatial Reliability (CSRT) ņĢīĻ│Āļ”¼ņ”ś(Luke┼Šic et al., 2017)ņØĆ Ļ│ĄĻ░ä ņŗĀļó░ļÅä ļ¦Ą ĻĄ¼ņČĢ, ņĀ£ĒĢ£ļÉ£ ņāüĻ┤Ć ĒĢäĒä░ ĒĢÖņŖĄ, ņ▒äļäÉ ņŗĀļó░ņä▒ ņČöņĀĢņØś 3ļŗ©Ļ│ä ņŚ░ņé░ņØä ĒåĄĒĢ┤ ņ×æļÅÖĒĢ£ļŗż. ņ▓½ ļ▓łņ¦Ė ļŗ©Ļ│äļŖö ROIļĪ£ ņäżņĀĢļÉ£ ņśüņŚŁ ņĢłņŚÉņä£ ĒĢäĒä░Ļ░Ć ņ×æļÅÖĒĢśļŖö ļ▓öņ£äļź╝ ņČöņĀüĒĢĀ Ļ░Øņ▓┤ņŚÉ ņĀüĒĢ®ĒĢśļÅäļĪØ ņĀ£ĒĢ£ĒĢśņŚ¼ ņ¦üņé¼Ļ░üĒśĢņØ┤ ņĢäļŗī ļČłĻĘ£ņ╣ÖĒĢ£ ļ¬©ņ¢æņØś Ļ░Øņ▓┤ņŚÉ ļīĆĒĢ£ Ļ▓Ćņāē ļ▓öņ£äņÖĆ ņä▒ļŖźņØä Ē¢źņāüņŗ£ĒéżļŖö ļŗ©Ļ│äņØ┤ļŗż. ļæÉ ļ▓łņ¦Ė ļŗ©Ļ│äņŚÉņä£ļŖö ņ▓½ ļ▓łņ¦Ė ļŗ©Ļ│äļź╝ ĒåĄĒĢ┤ ņĀ£ĒĢ£ļÉ£ ņśüņŚŁ ļé┤ņØś ĒöĮņģĆļōżņŚÉ ļīĆĒĢ┤ ļ░░Ļ▓ĮņØś ņśüĒ¢źņØä Ļ░Éņåīņŗ£ĒéżĻ│Ā Ļ░Øņ▓┤ņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖö ļČĆļČäņŚÉ Ļ░Ćņżæņ╣śļź╝ ļČĆņŚ¼ĒĢ£ļŗż. ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ ņĀ£ĒĢ£ļÉśņ¦Ć ņĢŖņØĆ ņĀä ņśüņŚŁņŚÉ ļīĆĒĢ£ ĒĢäĒä░ņØś ņØæļŗĄņŚÉ ņØ┤ņĀä ļŗ©Ļ│äņŚÉņä£ ņé░ņĀĢĒĢ£ Ļ░Ćņżæņ╣śļź╝ Ļ│▒ĒĢ┤ņä£ Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ ņČöņĀĢĒĢ£ļŗż. ņØ┤ļ¤¼ĒĢ£ CSRT ņĢīĻ│Āļ”¼ņ”śņØĆ ņĄ£ņāüņØś ņČöņĀü ņä▒Ļ│ĄļźĀņØä ļ│┤ņŚ¼ņŻ╝ņŚłĻ│Ā, ņ▓śļ”¼ ņåŹļÅäļŖö ļé«ņØĆ ĒÄĖņŚÉ ņåŹĒ¢łņ£╝ļéś ņŗżņé¼ņÜ®ņŚÉļŖö ļ¼┤ļ”¼Ļ░Ć ņŚåļŖö ņłśņżĆņ£╝ļĪ£ ĒīÉļŗ©ļÉśņ¢┤ ļ│Ė ņŚ░ĻĄ¼ņŚÉ ņĀüņÜ®ĒĢśņśĆļŗż. Table 1ņØĆ ņČöņĀü ņĢīĻ│Āļ”¼ņ”śļōżņØś ņä▒ļŖźņØä ļ╣äĻĄÉĒĢ£ Ļ▓░Ļ│╝ņØ┤ļŗż.
ļ│Ė ņŗ£ņŖżĒģ£ņŚÉņäĀ Ļ░Øņ▓┤ ņČöņĀüņŚÉ ņĢ×ņä£ ņé¼ņÜ®ņ×ÉĻ░Ć ņČöņĀüĒĢĀ Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ ROI ņśüņŚŁņ£╝ļĪ£ ņ¦ĆņĀĢĒĢ┤ ņŻ╝ļ®┤ Ļ░ü ĒöäļĀłņ×äļ│äļĪ£ Fig. 5ņÖĆ Ļ░ÖņØ┤ ņóīņĖĪ ņāüļŗ©ņØä ņøÉņĀÉņ£╝ļĪ£ ĒĢśļŖö ņØ┤ļ»Ėņ¦Ć ņóīĒæ£Ļ│äņŚÉņä£ Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ Ļ│äņé░ĒĢ£ļŗż. ņØ┤ļĢī Ļ░Øņ▓┤ņØś ņ£äņ╣śļŖö ņøÉņĀÉņŚÉņä£ļČĆĒä░ Ļ░Øņ▓┤ņØś ņżæņŗ¼Ļ╣īņ¦Ćļź╝ ĒöĮņģĆ ļŗ©ņ£äļĪ£ Ļ│äņé░ĒĢ£ļŗż. ņØ┤Ēøä ņČöņĀü ņĢīĻ│Āļ”¼ņ”śņØ┤ ņ×æļÅÖĒĢśņŚ¼ Ļ░Øņ▓┤ņØś ņØ┤ļÅÖņŚÉ ļö░ļØ╝ ROI ņśüņŚŁļÅä ņØ┤ļÅÖĒĢśĻ▓ī ļÉśļ®░ Ļ░ü ĒöäļĀłņ×äļ│ä ņóīĒæ£ Ļ░ÆņØä ņ¢╗ņØä ņłś ņ׳Ļ▓ī ļÉ£ļŗż.
2.3 ņóīĒæ£Ļ│ä ļ│ĆĒÖś ļ░Å ņ£äņ╣śņé░ņĀĢ
ņČöņĀü ĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ņ¢╗ņØĆ ņóīĒæ£ļŖö ņŗżņĀ£ Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ ļéśĒāĆļé┤ļŖö ņĀĢļ│┤Ļ░Ć ņĢäļŗī, ņśüņāü ĒöäļĀłņ×äņŚÉņä£ Ļ░Øņ▓┤Ļ░Ć ņ׳ļŖö ņ£äņ╣śĻ╣īņ¦ĆĻ░Ć ļ¬ć Ļ░£ņØś ĒöĮņģĆļĪ£ ĻĄ¼ņä▒ļÉśņ¢┤ ņ׳ļŖöĻ░Ćļź╝ ļéśĒāĆļé┤ļŖö ņĀĢļ│┤ņŚÉ ļČłĻ│╝ĒĢśļŗż. ņØ┤ļź╝ ņŗżņĀ£ Ļ░Øņ▓┤ņØś ņ£äņ╣śņØĖ ĻĖĖņØ┤ ņĀĢļ│┤ļĪ£ ļ│ĆĒÖśĒĢśĻĖ░ ņ£äĒĢ┤ņä£ļŖö ĒĢ£ Ļ░£ņØś ĒöĮņģĆņØ┤ ņ¢╝ļ¦łņØś ņŗżņĀ£ ĻĖĖņØ┤ņŚÉ ļīĆņØæĒĢśļŖöņ¦Ćļź╝ ļéśĒāĆļé┤ļŖö Scale Factorļź╝ Ļ│äņé░ĒĢ┤ņĢ╝ ĒĢ£ļŗż.
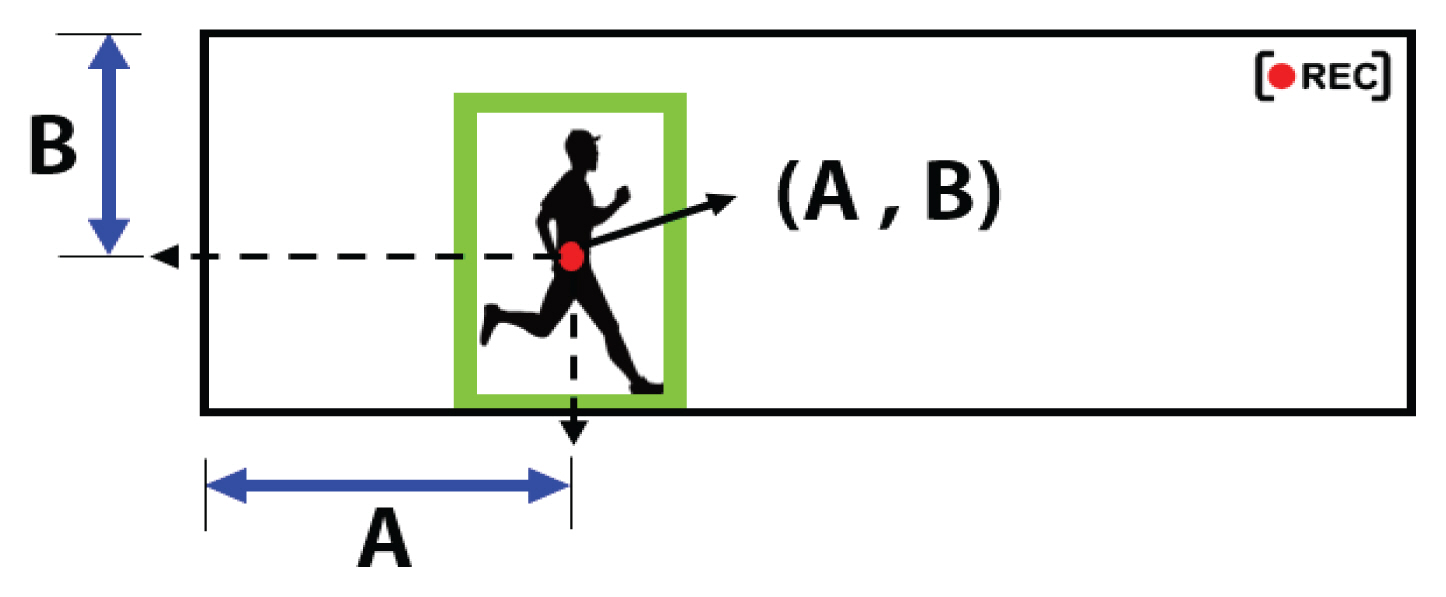
Ļ░Øņ▓┤ ņČöņĀüņŚÉ ņé¼ņÜ®ļÉ£ ņśüņāüņŚÉņä£ ņØ┤ļ»Ė ĻĖĖņØ┤ļź╝ ņĢīĻ│Ā ņ׳ļŖö ņé¼ļ×īņØ┤ļéś ĻĄ¼ņĪ░ļ¼╝ņØä ņØ┤ņÜ®ĒĢśņŚ¼, Scale Factor (ĒĢ┤ļŗ╣ĒĢśļŖö ĻĖĖņØ┤Ļ░Ć ļ¬ć Ļ░£ņØś ĒöĮņģĆļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ļŖöņ¦Ćļź╝)ļź╝ Ļ│äņé░ĒĢ£ Ēøä, ņśüņāü ĒöäļĀłņ×äņŚÉņä£ņØś ņ£äņ╣śļź╝ ņŗżņĀ£ ņ£äņ╣śļĪ£ ĒÖśņé░ĒĢśļŖö ļ░®ļ▓ĢņØä ņé¼ņÜ® ĒĢĀ ņłś ņ׳ļŗż(Fig. 6).
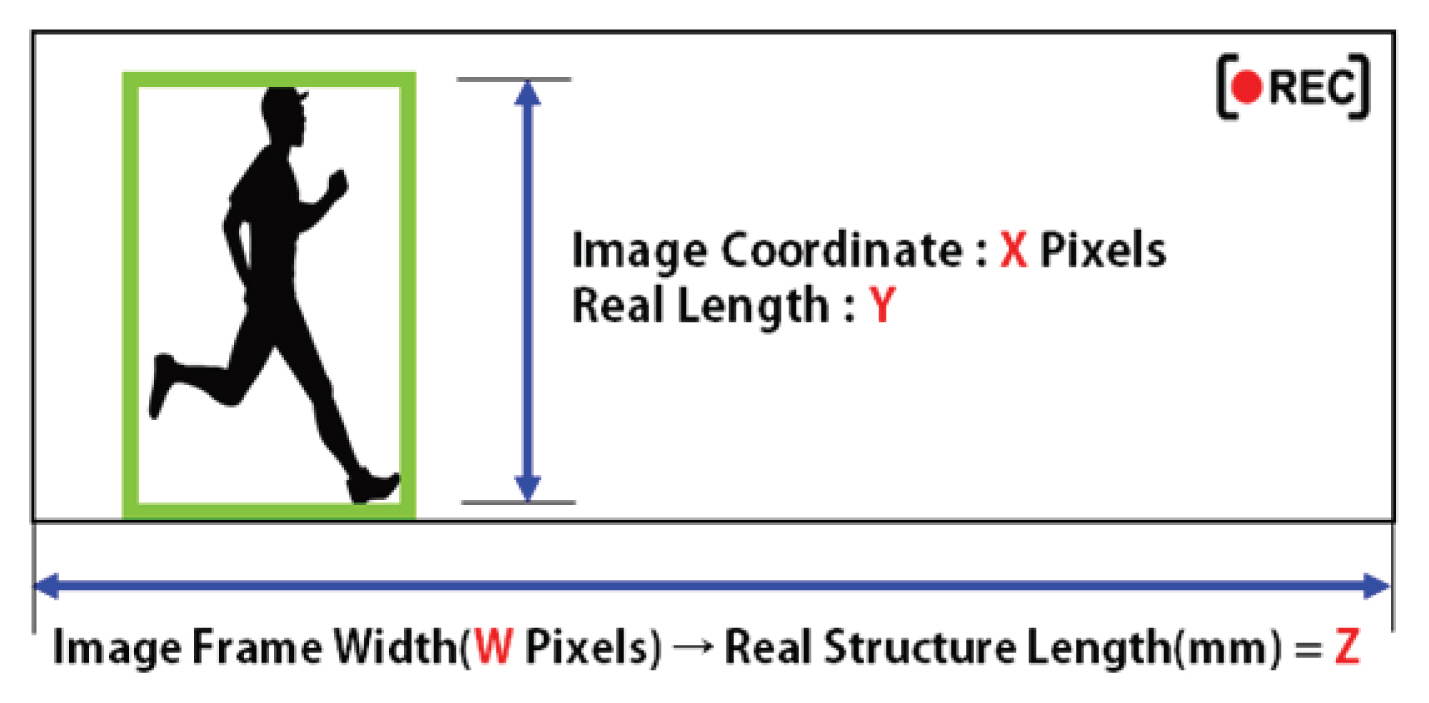
ņČöņĀüņØä ņ£äĒĢ£ Ļ┤Ćņŗ¼ ņśüņŚŁ(ROI) ņ£╝ļĪ£ ņäĀĒāØļÉ£ Ļ░Øņ▓┤ņØś ĻĖĖņØ┤ļź╝ ņØ┤ļ»Ė ņĢīĻ│Ā ņ׳ļŗżļ®┤ ņåÉņēĮĻ▓ī ĒĢ┤ļŗ╣ Ļ░Øņ▓┤ļź╝ ĻĄ¼ņä▒ĒĢśļŖö ĒöĮņģĆņØś Ļ░£ņłś Xļź╝ ņ¢╗ņØä ņłś ņ׳ļŗż. ĒĢ┤ļŗ╣ Ļ░Øņ▓┤ņØś ņŗżņĀ£ ĻĖĖņØ┤ Yļź╝ XļĪ£ ļéśļłäņ¢┤ ņŻ╝ļ®┤ ĒöĮņģĆ ĒĢ£ Ļ░£ņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖö ĻĖĖņØ┤ļź╝ ņ¢╗ņØä ņłś ņ׳ļŗż. ņØ┤ļĀćĻ▓ī ņ¢╗ņ¢┤ņ¦ä ļ╣äņ£©ņØä ņśüņāü ĒöäļĀłņ×äņØś Ļ░ĆļĪ£ ĒöĮņģĆ ņłś WņŚÉ Ļ│▒ĒĢśļ®┤ ĒöäļĀłņ×äņŚÉ ļŗ┤ĻĖ┤ ņŗżņĀ£ Ļ░ĆļĪ£ ĒÅŁ ĻĖĖņØ┤ ZĻ░Ć ņé░ņČ£ļÉ£ļŗż. ņØ┤ļź╝ ņŗØņ£╝ļĪ£ ļéśĒāĆļé┤ļ®┤ Eq. (1)Ļ│╝ Ļ░Öļŗż.
ĒöĮņģĆ ļŗ╣ ņŗżņĀ£ ĻĖĖņØ┤ļź╝ ņØ┤ņÜ®ĒĢśļ®┤ (Fig. 5)ņŚÉņä£ ĻĄ¼ĒĢ£ Ļ░Øņ▓┤Ļ╣īņ¦ĆņØś ĒöĮņģĆ ņłś AĻ░Ć ņŗżņĀ£ ĻĖĖņØ┤ ņ¢╝ļ¦łņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖöņ¦Ć ņĢī ņłś ņ׳Ļ│Ā, AņÖĆ W, Zļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Ļ░Øņ▓┤ņØś ņŗżņĀ£ ņ£äņ╣ś A'ņØä Ļ│äņé░ĒĢĀ ņłś ņ׳ļŗż(Eq. (2)).
2.4 ĻĄ¼ņĪ░ ĒĢ┤ņäØ
ļ¦łņ¦Ćļ¦ē ļŗ©Ļ│äļŖö ĻĄ¼ņĪ░ĒĢ┤ņäØ ļŗ©Ļ│äļĪ£ņŹ©, ņ£äņŚÉņä£ ņé░ņČ£ĒĢ£ ļÅÖņĀüĒĢśņżæņØś ņ£äņ╣śļź╝ ĻĄ¼ņĪ░ļ¼╝ņØś ņ£ĀĒĢ£ņÜöņåī ļ¬©ļŹĖņŚÉ ņĀüņÜ®ņŗ£ĒéżļŖö ļŗ©Ļ│äņØ┤ļŗż. ļ│Ė ņŚ░ĻĄ¼ļŖö ĻĄ¼ņĪ░ļ¼╝ņØś ļÅÖņĀü ĒĢśņżæņØä ņĖĪņĀĢĒĢśļŖöļŹ░ ņ┤łņĀÉņØä ļ¦×ņČöņŚłĻĖ░ ļĢīļ¼ĖņŚÉ, Ļ░äļŗ©ĒĢ£ Ļ░ĆņāüņØś ļ│┤ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Ļ▓░Ļ│╝ļź╝ ļČäņäØĒĢśņśĆļŗż(Fig. 7).
3. ņŗżĒŚś ļ░Å Ļ▓Ćņ”Ø
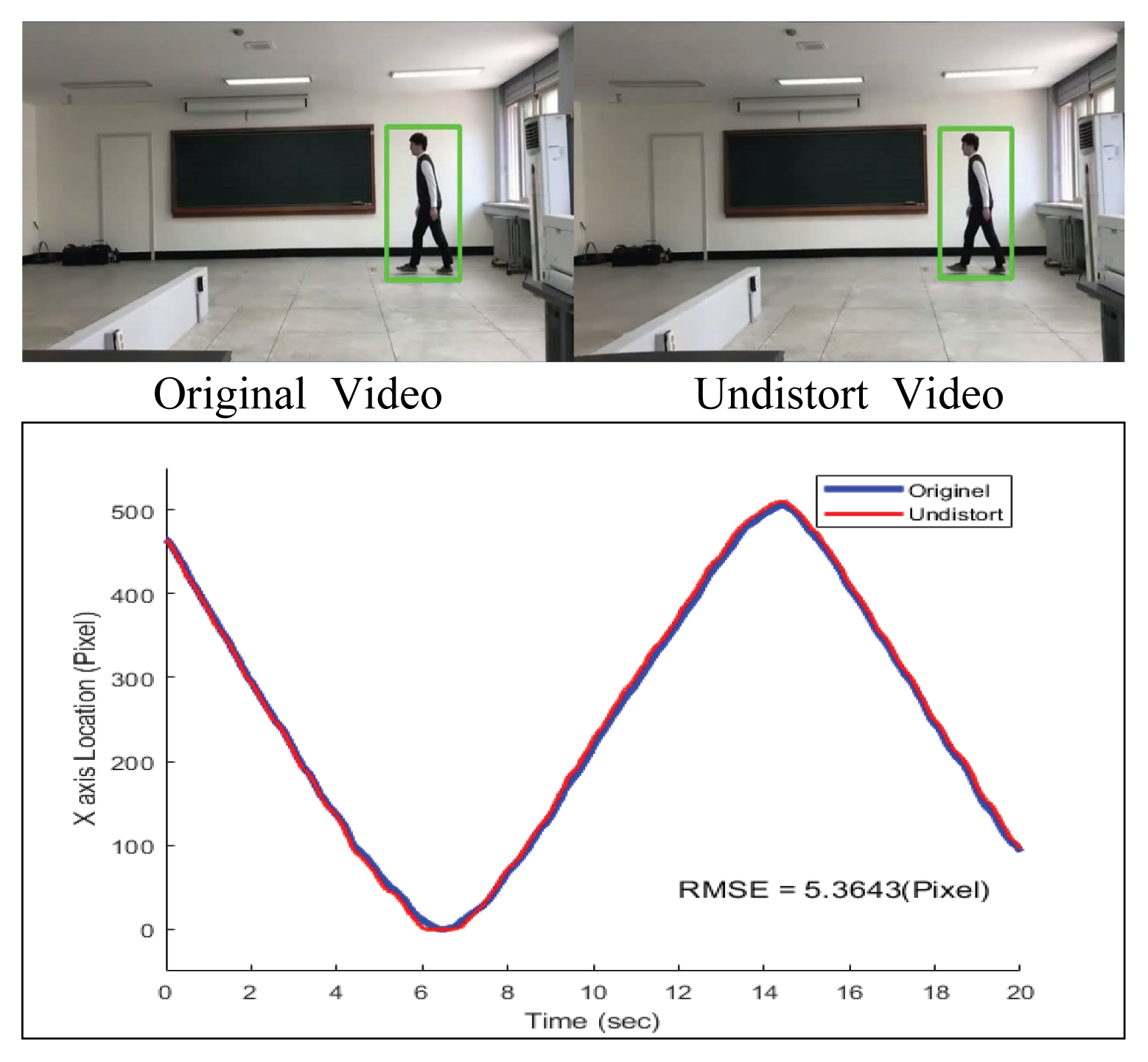
Ļ░£ļ░£ĒĢ£ ņŗ£ņŖżĒģ£ņØś ņä▒ļŖźņØä Ļ▓Ćņ”ØĒĢśĻĖ░ ņ£äĒĢśņŚ¼ ņŗżļé┤ņŗżĒŚśņØä ņ¦äĒ¢ēĒĢśņśĆļŗż. iPhone 7+ņŚÉ Ēāæņ×¼ļÉ£ ņ╣┤ļ®öļØ╝ļź╝ ņØ┤ņÜ®, ņ╣┤ļ®öļØ╝ļź╝ ņäżņ╣śĒĢ£ Ēøä Ļ░Øņ▓┤ļź╝ ņ¦ĆņåŹņĀüņ£╝ļĪ£ ņøĆņ¦üņØ┤Ļ▓ī ĒĢśļ®░ ņśüņāüņØä ņ┤¼ņśüĒĢśņśĆĻ│Ā, Figs. 8, 9ņÖĆ Ļ░ÖņØ┤ ņśüņāü ņ┤¼ņśüņŚÉņä£ ļ░£ņāØĒĢśļŖö ņÖ£Ļ│ĪņØä ļ│┤ņĀĢĒĢśĻĖ░ ņ£äĒĢ┤ Zhang (2000)ņØ┤ ņĀ£ņŗ£ĒĢ£ ņĢīĻ│Āļ”¼ņ”śņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņ╣┤ļ®öļØ╝ ņ║śļ”¼ļĖīļĀłņØ┤ņģśņØä ņ¦äĒ¢ē, ĒÜŹļōØĒĢ£ ĒīīļØ╝ļ»ĖĒä░ļź╝ ĒåĄĒĢ┤ ņśüņāüņØä ļ│┤ņĀĢĒĢśņśĆļŗż(Fig. 10).
ņØ┤Ēøä ļ│┤ņĀĢļÉ£ ņśüņāüņØä Ļ░£ļ░£ĒĢ£ ņŗ£ņŖżĒģ£ņØä ĒåĄĒĢ┤ ņ▓śļ”¼ĒĢśņśĆĻ│Ā Ļ▓░Ļ│╝ Ļ░Æ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ļ░öļŗźņØś ĻĖĖņØ┤ļź╝ ņĖĪņĀĢĒĢśņŚ¼ ņŗżņĀ£ ĻĖĖņØ┤ļź╝ ņ¢╗ņŚłļŗż. ņśüņāü ņ▓śļ”¼ļź╝ ĒåĄĒĢ┤ Ļ│äņé░ļÉ£ ņĀäņ▓┤ Ļ░ĆļĪ£ ĒÅŁ ĻĖĖņØ┤ ļ░Å Ļ░Øņ▓┤ņØś ņ£äņ╣śņÖĆ ņĖĪņĀĢņØä ĒåĄĒĢ┤ ņ¢╗ņØĆ ņŗżņĀ£ Ļ░ÆĻ│╝ ļ╣äĻĄÉļź╝ ņ¦äĒ¢ēĒĢśņśĆļŗż. ņĀäņ▓┤ņĀüņØĖ ĒģīņŖżĒŖĖļ▓Āļō£ ĻĄ¼ņČĢ Ļ░£ņÜöļŖö ļŗżņØīĻ│╝ Ļ░Öļŗż(Fig. 11).
ņןļ╣ä ļ░Å ņĖĪņĀĢļ░®ļ▓ĢņØś ĒĢ£Ļ│äļĪ£ ņØĖĒĢ┤ ņŗżļé┤ņŗżĒŚśņØä ņ¦äĒ¢ēĒ¢łņ£╝ļéś ņóĆ ļŹö ļ¬ģĒÖĢĒĢ£ ņŗ£ņŖżĒģ£ņØś ĒÅēĻ░Ćļź╝ ņ£äĒĢ┤ ĒĢśņżæ ņ£äņ╣śņØś ņØ┤ļÅÖļ¤ēņØä ņĀĢĒÖĢĒ׳ ĒåĄņĀ£ĒĢĀ ņłś ņ׳ļŖö Ļ░äļץĒĢ£ ļ│┤ļÅäĒśäņłśĻĄÉ ņŗ£ļ«¼ļĀłņØ┤ņģśņØä ņĀ£ņ×æĒĢśņśĆļŗż. ņŗ£ļ«¼ļĀłņØ┤ņģś Ļ▓░Ļ│╝ļź╝ ņśüņāüņ£╝ļĪ£ ņ┤¼ņśüĒĢśņŚ¼ ņØ┤ņŚÉ ļīĆĒĢ£ ņŗżĒŚśņØä ņČöĻ░ĆņĀüņ£╝ļĪ£ ņ¦äĒ¢ēĒĢśņśĆļŗż(Fig. 12). ņŗ£ļ«¼ļĀłņØ┤ņģś ņĀ£ņ×æņŚÉ ņé¼ņÜ®ĒĢ£ ĒĢśņżæ ņØ┤ļÅÖļ¤ēĻ│╝ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ Ļ░£ļ░£ļÉ£ ņŗ£ņŖżĒģ£ņØä ĒåĄĒĢ┤ ņ¢╗ņ¢┤ņ¦ä ņØ┤ļÅÖļ¤ēņØä ļ╣äĻĄÉĒĢśņśĆļŗż.
4. Ļ▓░Ļ│╝ ļČäņäØ ļ░Å ĒåĀņØś
ņ╣┤ļ®öļØ╝ ļ│┤ņĀĢņŚÉ ļö░ļźĖ ĒÜ©Ļ│╝ļź╝ ņĢīņĢäļ│┤ĻĖ░ ņ£äĒĢ┤ ļ│┤ņĀĢļÉśņ¦Ć ņĢŖņØĆ ņśüņāüĻ│╝ ļ│┤ņĀĢļÉ£ ņśüņāüņŚÉ Ļ░£ļ░£ĒĢ£ ņŗ£ņŖżĒģ£ņØä ņĀüņÜ®ĒĢśņŚ¼ ņĖĪņĀĢļÉ£ ĒĢśņżæņØś ņ£äņ╣śļź╝ ļ╣äĻĄÉĒĢśņśĆļŗż(Fig. 13). ņŗżĒŚśĻ▓░Ļ│╝ 720 ├Ś 404 ĒöĮņģĆļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ä ņśüņāüņØś Ļ▓ĮņÜ░ ĒÅēĻĘĀ ņĀ£Ļ│▒ĻĘ╝ ņśżņ░©(RMSE)Ļ░Ć ņĢĮ 5.4ĒöĮņģĆ ņĀĢļÅä ļ░£ņāØĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż. ļśÉĒĢ£ ņśüņāüņØś ņÖ£Ļ│ĪņØ┤ Ļ░Ćņןņ×Éļ”¼ņŚÉņä£ ņāüļīĆņĀüņ£╝ļĪ£ Ēü¼Ļ▓ī ļ░£ņāØĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ Ļ░Øņ▓┤Ļ░Ć ņśüņāüņØś ņóī, ņÜ░ ļüØņ£╝ļĪ£ ņØ┤ļÅÖĒĢĀņłśļĪØ ņśżņ░©Ļ░Ć Ēü¼Ļ▓ī ļ░£ņāØĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż.
ņ£äņØś ņĀĢļ│┤ļź╝ ļ░öĒāĢņ£╝ļĪ£ ļ│┤ņĀĢļÉ£ ņśüņāüņŚÉ ņŗ£ņŖżĒģ£ņØä ņĀüņÜ®ĒĢśņśĆļŗż. Eq. (1)ņØä ņĀüņÜ®ĒĢśĻĖ░ ņ£äĒĢ┤, ņČöņĀüĒĢĀ Ļ░Øņ▓┤ņØś Ēéż(1,816 mm)ļź╝ ņØ┤ļ»Ė ņĢīĻ│Ā ņ׳ņ£╝ļ»ĆļĪ£ ņØ┤ļź╝ YļĪ£ ņØ┤ņÜ®ĒĢśņśĆļŗż. ņśüņāü ĒöäļĀłņ×äņŚÉņä£ ņØ┤ Ļ░Øņ▓┤ļź╝ ĻĄ¼ņä▒ĒĢśļŖö ņäĖļĪ£ ĒöĮņģĆ ņłśļŖö 163Ļ░£(X)ņŚÉ ĒĢ┤ļŗ╣ļÉśņŚłļŗż. ņĀäņ▓┤ ņśüņāü ĒöäļĀłņ×äņØś Ļ░ĆļĪ£ ĒöĮņģĆ ņłśļŖö ņ┤Ø 720Ļ░£(W) ņØ┤Ļ│Ā, ļ░öļŗź Ļ░ĆļĪ£ ĒÅŁņØĆ ņŗżņĀ£ ņĖĪņĀĢĻ▓░Ļ│╝ 8,150 mm ņØ┤ņŚłļŗż(Fig. 14). Eq. (1)ņŚÉ ļö░ļØ╝ Ļ│äņé░ļÉ£ ZĻ░ÆņØĆ ņĢĮ 8,022 mmļĪ£, ņŗżņĀ£ ņĖĪņĀĢĻ░ÆņØĖ 8,150 mmņÖĆ 1.57%ņØś ņśżņ░©ļź╝ ļ│┤ņśĆļŗż. ļ│┤ņĀĢ ņĀä ņśüņāüņØś Ļ▓ĮņÜ░ XĻ░ÆņØ┤ 168Ļ░£, ņØ┤ņŚÉ ļö░ļźĖ ņĄ£ņóģ ZĻ░ÆņØĆ 7,783 mmļĪ£ 4.51%ņØś ņśżņ░©ļź╝ ļ│┤ņśĆļŖöļŹ░, ņśüņāü ļ│┤ņĀĢņØä ĒåĄĒĢ┤ 2.94%ņØś ņśżņ░© Ļ░Éņåī ĒÜ©Ļ│╝ļź╝ ļ│┤ņĢśņØīņØä ņĢī ņłś ņ׳ļŗż.
Ļ░Øņ▓┤ņØś ņ£äņ╣śļź╝ ņØĖņŗØĒĢ£ Ļ▓░Ļ│╝ļŖö Fig. 15ņÖĆ Ļ░Öņ£╝ļ®░, ņ£äņ╣ś ņØ┤ļÅÖņŚÉ ļö░ļźĖ ļ│ĆĒÖöļź╝ ņēĮĻ▓ī ņĢīņĢäļ│┤ĻĖ░ ņ£äĒĢ┤ ņ×äņØśņØś ĒĢśņżæņØä ņĀüņÜ®ĒĢśņŚ¼ ņĀäļŗ©ļĀźļÅäņÖĆ Ē£©ļ¬©ļ®śĒŖĖļÅäļź╝ ņ×æļÅäĒĢśņśĆļŗż. Eq. (2)ļź╝ ņĀüņÜ®Ē¢łĻĖ░ ļĢīļ¼ĖņŚÉ ZņØś ņśżņ░©ņŚÉņä£ ĻĖ░ņØĖĒĢ£ Ļ░Øņ▓┤ņØś ņ£äņ╣ś ņśżņ░©Ļ░Ć ļ░£ņāØĒ¢łĻ│Ā ņØ┤ļŖö ZņØś ņśżņ░©ļź╝ ĒĢ┤Ļ▓░ĒĢśļ®┤ Ļ░ÖņØ┤ ĒĢ┤Ļ▓░ļÉĀ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż. ņØ┤ ņśżņ░© ņÖĖņŚÉ ļŗżļźĖ ņśżņ░©ļŖö ļ░£ņāØĒĢśņ¦Ć ņĢŖņĢä ļåÆņØĆ ņ£äņ╣ś ņØĖņŗØļźĀņØä ļ│┤ņśĆļŗż.
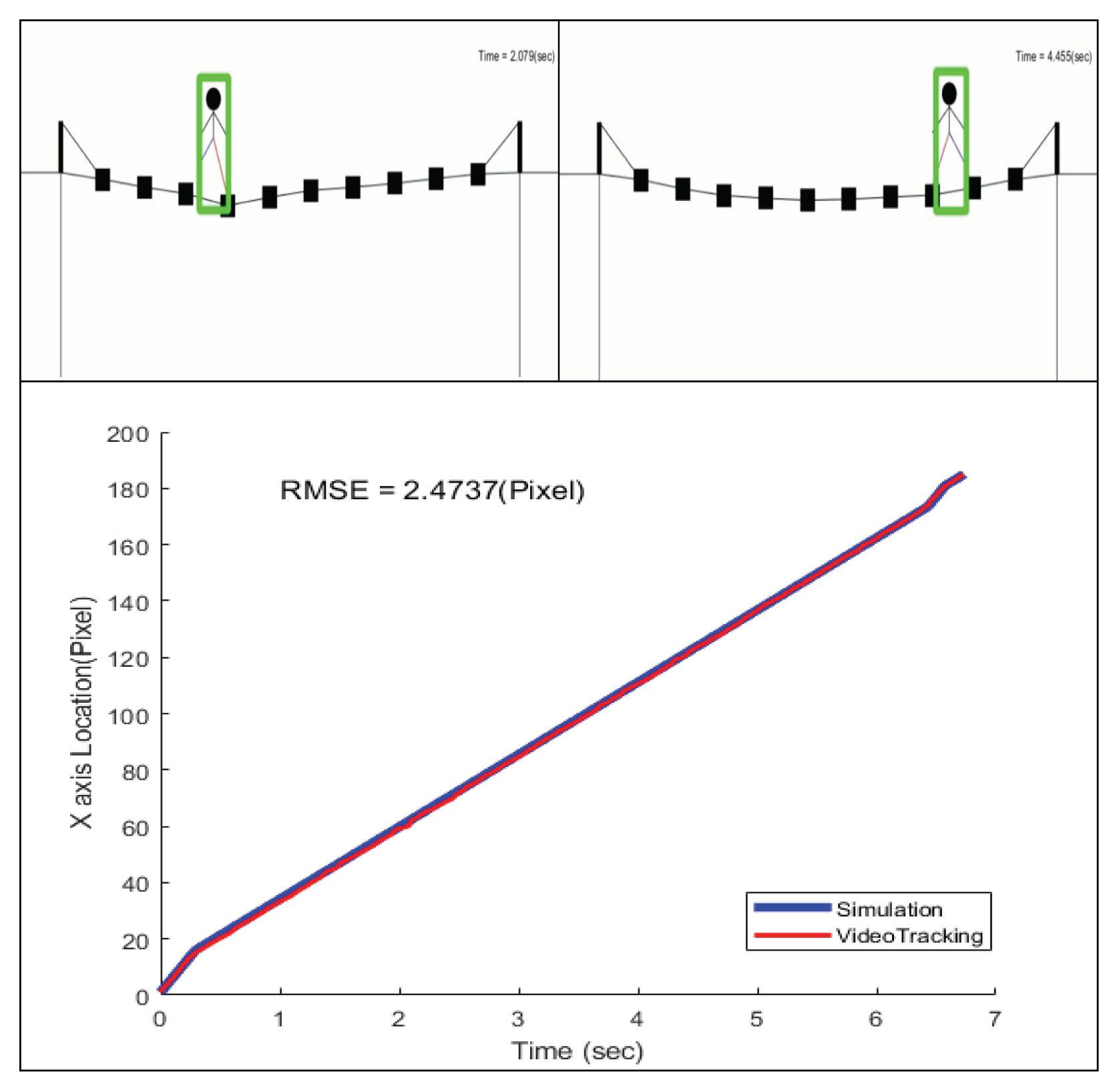
ņČöĻ░Ć ņŗżĒŚśņŚÉ ņé¼ņÜ®ļÉ£ ņŗ£ļ«¼ļĀłņØ┤ņģś ņśüņāüņØĆ 762 ├Ś 330ĒöĮņģĆļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ņ£╝ļ®░, ņŗżņĀ£ ņŗ£ļ«¼ļĀłņØ┤ņģśņØś ņØ┤ļÅÖļ¤ēĻ│╝ ņŗ£ņŖżĒģ£ņØä ĒåĄĒĢ┤ ņ¢╗ņ¢┤ņ¦ä Ļ▓░Ļ│╝ļź╝ ļ╣äĻĄÉĒĢ£ Ļ▓░Ļ│╝ ĒÅēĻĘĀ ņĀ£Ļ│▒ ņśżņ░©Ļ░Ć ņĢĮ 2.47ĒöĮņģĆļĪ£ ņŗżļé┤ņŗżĒŚśņŚÉ ļ╣äĒĢ┤ ļåÆņØĆ ņĀĢĒÖĢļÅäļź╝ ļ│┤ņŚ¼ņŻ╝ņŚłļŗż(Fig. 16).
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĒÜŹļōØĒĢ£ ĒĢśņżæņØś ņ£äņ╣śņĀĢļ│┤ņŚÉ ņ×äņØśņØś ĒĢśņżæ Ēü¼ĻĖ░ļź╝ ņĀüņÜ®ĒĢśņŚ¼ Ļ░äļץĒĢśĻ▓ī ĻĄ¼ņĪ░ ĒĢ┤ņäØņØä ņ¦äĒ¢ēĒĢśņśĆņ£╝ļéś, ņØ┤ ņŗ£ņŖżĒģ£ņŚÉ ļöźļ¤¼ļŗØ(Deep Learning) ĻĖ░ļ▓ĢņØä ĻĖ░ļ░śņ£╝ļĪ£ ĒĢ£ ĒĢśņżæ ņśłņĖĪ ņĢīĻ│Āļ”¼ņ”śņØä ņČöĻ░ĆĒĢ£ļŗżļ®┤ ņśüņāü ņ┤¼ņśüļ¦īņ£╝ļĪ£ ļÅÖņĀü ĒĢśņżæņØś Ēü¼ĻĖ░ņÖĆ ņ£äņ╣śļź╝ ņé░ņČ£ĒĢśņŚ¼ ĻĄ¼ņĪ░ ļ¬©ļŗłĒä░ļ¦üņŚÉ ņåÉņēĮĻ▓ī ņØ┤ņÜ®ĒĢĀ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.
ļśÉĒĢ£ ņČöņĀü ĻĖ░ļ▓ĢņØ┤ Ļ░Ćņ¦ĆļŖö ĒĢ£Ļ│äņÖĆ ņŗżņĀ£ ņĀüņÜ®ņä▒ņØä ļåÆņØ┤ĻĖ░ ņ£äĒĢśņŚ¼ Ļ░Øņ▓┤ Ļ▓ĆņČ£ ĻĖ░ļ▓ĢĻ│╝ ņČöņĀü ĻĖ░ļ▓ĢņØä ĒĢ©Ļ╗ś ņé¼ņÜ®ĒĢśļŖö ļ░®ļ▓ĢņŚÉ ļīĆĒĢ£ ņČöĻ░ĆņĀüņØĖ ņŚ░ĻĄ¼Ļ░Ć ĒĢäņÜö ĒĢ£ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż. ROI ņäżņĀĢ ļŗ©Ļ│äņŚÉļ¦ī Ļ▓ĆņČ£ ĻĖ░ļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ Ļ▓ĆņČ£ ĻĖ░ļ▓ĢņØś ņ▓śļ”¼ņåŹļÅäĻ░Ć ļé«ļŗżļŖö ĒĢ£Ļ│äņĀÉņØä ĒĢ┤Ļ▓░ĒĢśĻ│Ā, ņČöņĀü ļīĆņāü ņäĀņĀĢņØä ņ×ÉļÅÖĒÖö ĒĢĀ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.
ĻĖ░ņĪ┤ ņŚ░ĻĄ¼ļōżņØĆ ņśüņāü ĻĖ░ļ▓ĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ InputņØ┤ Ļ░ĆĒĢ┤ņĪīņØä ļĢī ļ░£ņāØĒĢśļŖö ĻĄ¼ņĪ░ļ¼╝ņØś ļ│Ćņ£äļź╝ ņĖĪņĀĢĒĢśļŖö ļŹ░ ņżæņĀÉņØä ļæÉĻ│Ā ņ׳ņŚłņ£╝ļéś, ņØ┤ ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ OutputņØ┤ ņĢäļŗī Input ņĖĪņĀĢņŚÉļÅä ņśüņāü ĻĖ░ļ▓ĢņØä ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļŗżļŖö Ļ░ĆļŖźņä▒ņØä ņĀ£ņŗ£ ĒĢśĻ▓ī ļÉśņŚłļŗż. ņśüņāü ĻĖ░ļ░ś ļÅÖņĀü ĒĢśņżæ ņĖĪņĀĢ ņŗ£ņŖżĒģ£ņØ┤ ņóĆ ļŹö ļ░£ņĀäĒĢśĻ▓ī ļÉśļ®┤ ĻĖ░ņĪ┤ņŚÉ Ļ░£ļ░£ļÉ£ ņśüņāü ĻĖ░ļ░ś ļÅÖņĀü ņØæļŗĄ ņĖĪņĀĢ ņŗ£ņŖżĒģ£Ļ│╝ Ļ▓░ĒĢ®ĒĢśņŚ¼ ņśüņāü ņ┤¼ņśüļ¦īņ£╝ļĪ£ ĻĄ¼ņĪ░ļ¼╝ ļ¬©ļŗłĒä░ļ¦üņØ┤ Ļ░ĆļŖźĒĢśĻ▓ī ļÉĀ Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.
ĒŖ╣Ē׳ ļ│┤Ē¢ēĒĢśņżæņØ┤ ņ¦Ćļ░░ņĀüņØĖ ņŚŁĒĢĀņØä ĒĢśļŖö ļ│┤ļÅäĒśäņłśĻĄÉņØś Ļ▓ĮņÜ░ ņØ╝ļ░śņĀüņØĖ ĻĄ¼ņĪ░ļ¼╝ņŚÉ ļ╣äĒĢ┤ InputĻ│╝ ĻĘĖņŚÉ ļīĆĒĢ£ Output ļśÉĒĢ£ Ļ░Ćņŗ£ņĀüņ£╝ļĪ£ ĒÖĢņØĖļÉĀ ņĀĢļÅäņØ┤ļ»ĆļĪ£, ņØ┤ļ¤¼ĒĢ£ ĻĄ¼ņĪ░ļ¼╝ņŚÉ ļ│Ė ņŚ░ĻĄ¼ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒĢ£ ņśüņāü ĻĖ░ļ░ś ĻĄ¼ņĪ░ļ¼╝ ļ¬©ļŗłĒä░ļ¦ü ņŗ£ņŖżĒģ£ņØä ņĀüņÜ®ĒĢ£ļŗżļ®┤ ļ│┤ļŗż ļ¬ģĒÖĢĒĢśĻ▓ī ĻĄ¼ņĪ░ļ¼╝ņØś ņāüĒā£ļź╝ ņĢīņĢäļé╝ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ņāØĻ░üļÉ£ļŗż.
5. Ļ▓░ ļĪĀ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĻĄ¼ņĪ░ļ¼╝ Ļ▒┤ņĀäņä▒ ļ¬©ļŗłĒä░ļ¦üņŚÉ ņØ┤ņÜ®ĒĢśĻĖ░ ņ£äĒĢ£ ļÅÖņĀü ĒĢśņżæ ņĖĪņĀĢņŚÉ ņ׳ņ¢┤ņä£, ņśüņāü ĻĖ░ļ▓ĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒÄĖļ”¼ĒĢśĻ│Ā Ļ▓ĮņĀ£ņĀüņ£╝ļĪ£ ĒĢśņżæņØś ņ£äņ╣śņĀĢļ│┤ļź╝ ņĖĪņĀĢĒĢĀ ņłś ņ׳ļŖö ņŗ£ņŖżĒģ£ņØä Ļ░£ļ░£ĒĢśņśĆļŗż. ņØ┤ ņŗ£ņŖżĒģ£ņØĆ ĻĖ░ņĪ┤ ļÅÖņĀü ĒĢśņżæ ņĖĪņĀĢ ļ░®ņŗØĻ│╝ ļ│äļÅäņØś ņ×ÉņøÉņØ┤ ņåīļ¬©ļÉśļŖö ĒĢ£Ļ│äļź╝ ĻĘ╣ļ│ĄĒĢśĻ│Ā, ņāüņÜ® ņ╣┤ļ®öļØ╝ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņåÉņēĮĻ▓ī ļÅÖņĀü ĒĢśņżæņØś ņ£äņ╣śņĀĢļ│┤ļź╝ ĒÜŹļōØĒĢĀ ņłś ņ׳ņŚłņ£╝ļ®░, ņØ┤ļź╝ ĻĄ¼ņĪ░ ĒĢ┤ņäØņŚÉ ņĀüņÜ®ĒĢĀ ņłś ņ׳Ļ▓ī ļÉśņŚłļŗż. ņØ┤ ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ ĻĄ¼ņĪ░ļ¼╝ņØś ļÅÖņĀü ĒĢśņżæ ņĖĪņĀĢņŚÉ ņśüņāü ĻĖ░ļ▓ĢņØä ņØ┤ņÜ®ĒĢśļŖö ņŚ░ĻĄ¼ņŚÉ ļīĆĒĢ£ Ļ░ĆļŖźņä▒ņØä ņĀ£ņŗ£Ē¢łļŗżĻ│Ā ĒīÉļŗ©ļÉ£ļŗż. ņČöĒøä ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļöźļ¤¼ļŗØņŚÉ ĻĖ░ļ░śĒĢ£ ĒĢśņżæ Ēü¼ĻĖ░ ņĖĪņĀĢ ņĢīĻ│Āļ”¼ņ”ś Ļ░£ļ░£Ļ│╝ ņśüņāü ĻĖ░ļ░ś ļÅÖņĀü ņØæļŗĄ ņĖĪņĀĢ ņŗ£ņŖżĒģ£Ļ│╝ņØś ņŚ░ļÅÖ, ĻĄ¼ņĪ░ļ¼╝ ļ¬©ļŹĖņØä ņČöĻ░ĆĒĢśņŚ¼ ĻČüĻĘ╣ņĀüņ£╝ļĪ£ ņśüņāü ņ┤¼ņśüļ¦īņ£╝ļĪ£ ĒĢ┤ļŗ╣ ĻĄ¼ņĪ░ļ¼╝ņØś ļ¬©ļŗłĒä░ļ¦üņØ┤ Ļ░ĆļŖźĒĢ┤ņ¦ĆļÅäļĪØ ĒĢśļŖö ņŚ░ĻĄ¼Ļ░Ć ĒĢäņÜöĒĢĀ Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż.