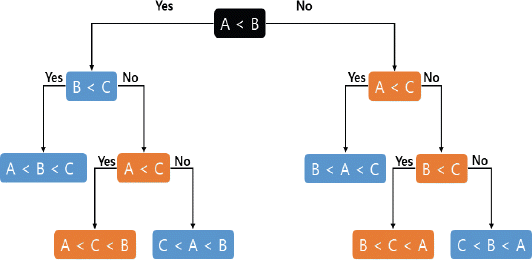
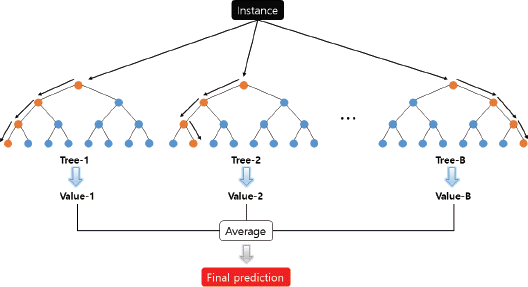
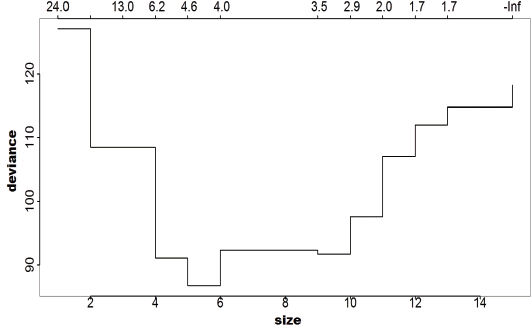
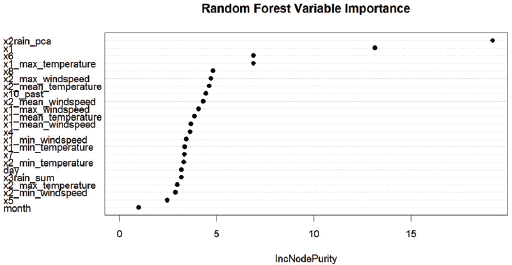
Ahn, J.H, Lee, J.U, and Choi, C.W (2011) Flood Mitigation Analysis for Abnormal Flood at the South Han River Basin.
J. Korean Soc. Hazard Mitig, Vol. 11, No. 5, pp. 265-272. 10.9798/KOSHAM.2011.11.5.265.

Asim, K.M, Mart├Łnez-├ülvarez, F, Basit, A, and Iqbal, T (2017) Earthquake Magnitude Prediction in Hindukush Region Using Machine Learning Techniques.
Natural Hazards, Vol. 85, No. 1, pp. 471-486. 10.1007/s11069-016-2579-3.
Breiman, L (1996) Bagging Predictors.
Machine Learning, Vol. 24, No. 2, pp. 123-140. 10.1007/BF00058655.
Breiman, L (2001) Random Forests.
Machine Learning, Vol. 45, No. 1, pp. 5-32. 10.1023/A:1010933404324.
Breiman, L, Friedman, J, Stone, C.J, and Olshen, R.A (1984).
Classification and Regression Trees. CRC press.
Cho, J.P, Jung, I.W, Kim, C.G, and Kim, T.G (2016) One-month Lead Dam Inflow Forecast Using Climate Indices Based on Tele-connection.
Journal of Korea Water Resources Association, Vol. 49, No. 5, pp. 361-372. 10.3741/JKWRA.2016.49.5.361.
Choi, C.H, Han, D.G, Kim, J.W, Jung, J.W, Kim, D.H, and Kim, H.S (2016) Mega Flood Simulation Assuming Successive Extreme Rainfall Events.
Journal of Wetlands Research, Vol. 18, No. 1, pp. 76-83. 10.17663/JWR.2016.18.1.076.
Choi, C.H, Kim, J.S, Kim, J.H, Kim, H.Y, Lee, W.J, and Kim, H.S (2017) Development of Heavy Rain Damage Prediction Function Using Statistical Methodology.
J. Korean Soc. Hazard Mitig, Vol. 17, No. 3, pp. 331-338. 10.9798/KOSHAM.2017.17.3.331.
Furquim, G, Pessin, G, Fai├¦al, B.S, Mendiondo, E.M, and Ueyama, J (2016) Improving the Accuracy of a Flood Forecasting Model by Means of Machine Learning and Chaos Theory.
Neural Computing and Applications, Vol. 27, No. 5, pp. 1129-1141. 10.1007/s00521-015-1930-z.
Han, D.G, Choi, C.H, Kim, D.H, Jung, J.W, Kim, J.W, and Kim, S.J (2016) Determination of Flood Reduction Alternatives for Responding to Climate Change in Gyeongan Watershed.
Journal of Wetlands Research, Vol. 18, No. 2, pp. 154-165. 10.17663/JWR.2016.18.2.154.
Han, G.Y, and Choi, G.H (2002) Comparison Study on One- and Two-Dimensional Models for Extreme Flood Routing.
Proceeding of KSCE 2002 Conference. Korean Society of Civil Engineers, pp. 1589-1592.
Han, G.Y, Choi, G.H, and Choi, H.J (2003) Emergency Action Plan against Extreme Flood from Dam/Levee Break.
Proceeding of KSCE 2003 Conference. Korean Society of Civil Engineers, pp. 2348-2351.
Hwang, S.W (2014) Assessing the Performance of CMIP5 GCMs for Various Climatic Elements and Indicators over the Southeast US.
Journal of Korea Water Resources Association, Vol. 47, No. 11, pp. 1039-1050. 10.3741/JKWRA.2014.47.11.1039.
Jang, D.W, Kim, B.S, Yang, D.M, Kim, B.G, and Seo, B.H (2009) A Development of GIS based Excess Flood Protection System - Using Decision Support methods.
Proceeding of KSCE 2009 Conference. Korean Society of Civil Engineers, pp. 630-634.
Jung, J.W, Kim, Y.S, Hong, S.J, Kwon, H.S, Kim, J.W, and Kim, H.S (2014) Effectiveness Analysis of Artificial Wetland for Flood Reduction.
J. Korean Soc. Hazard Mitig, Vol. 14, No. 4, pp. 369-377. 10.9798/KOSHAM.2014.14.4.369.
Kim, D.G, Lee, L.Y, Lee, C.W, Kang, N.R, Lee, J.S, and Kim, H.S (2011) Analysis of Flood Reduction Effect of Washland using Hydraulic Experiment.
Journal of Wetlands Research, Vol. 13, No. 2, pp. 307-317.
Kim, J, Lee, C.K, Shon, J, Choi, K.J, and Yoon, Y (2012) Comparison of Statistic Methods for Evaluating Crop Model Performance.
Korean Journal of Agricultural and Forest Meteorology, Vol. 14, No. 4, pp. 269-276. 10.5532/KJAFM.2012.14.4.269.
Kim, J.S, Choi, C.H, Lee, J.S, and Kim, H.S (2017) Damage Prediction Using Heavy Rain Risk As- sessment:(2) Development of Heavy Rain Damage Prediction Function.
J. Korean Soc. Hazard Mitig, Vol. 17, No. 2, pp. 371-379. 10.9798/KOSHAM.2017.17.2.371.
Lee, J.S (2017).
Development of Regional Flood Damage Functions for Public Facilities Based on Disaster Statistics and Impact Assessment of Climate Change. Ph.D. dissertation. University of Inha, Republic of Korea.
Lee, J.S, Eo, G, Choi, C.H, Jung, J.W, and Kim, H.S (2016) Development of Rainfall-Flood Damage Estimation Function using Nonlinear Regression Equation.
Journal of the Korean Society of Disaster Information, Vol. 12, No. 1, pp. 74-88. 10.15683/kosdi.2016.3.31.74.
Liu, J (2012). Weather or Wealth: An Analysis of Property Loss Caused by Flooding in the US.
2012 Annual Meeting. Agricultural and Applied Economics Association.

Munich Re (2002)
Winter Storms in Europe: Analysis of 1990 Losses and Future Loss Potentials.
Oh, S.M, Kim, G.H, Jung, Y.H, Kim, D.H, and Kim, H.S (2015) Risk Assessment of Heavy Snowfall Using PROMETHEE: The Case of Gangwon Province.
J. Korean Soc. Hazard Mitig, Vol. 15, No. 1, pp. 87-98. 10.9798/KOSHAM.2015.15.1.87.
Pielke, R.A, and Downton, M.W (2000) Precipitation and Damaging Floods: Trends in the United States, 1932ŌĆō97.
Journal of Climate, Vol. 13, No. 20, pp. 3625-3637. 10.1175/1520-0442(2000)013<3625:PADFTI>2.0.CO;2.
Toya, H, and Skidmore, M (2007) Economic Development and the Impacts of Natural Disasters.
Economics Letters, Vol. 94, No. 1, pp. 20-25. 10.1016/j.econlet.2006.06.020.
Yi, C.S, Lee, S.C, Kim, H.S, and Shim, M.P (2005) Multi-Criteria Decision Making Model for Flood Control Project - 1. A Comparative Analysis of AHP and MAUT.
Journal of Korean Society of Civil Engineers, Vol. 25, No. 5B, pp. 337-346.