석탄회 혼합 모래필터의 폐색 예측을 위한 신경망모델
A Neural Network Model to Estimate the Clogging of Ash Mixed Sand Filter
Article information
Abstract
강우유출수 침투시설에 설치한 침투필터는 운영 시 오염물질이 공극을 막는 폐색이 발생할 수 있다. 침투시설의 기능 저감을 방지하기 위해서는 폐색도를 고려하여 필터를 유지관리해야 한다. 본 연구에서는 폐색도의 변화를 침투유량(Q)에 대한 침투율(IR)의 상관관계인 폐색곡선으로 나타냈다. 폐색도 추정을 위해 임의로 선정한 특성치 조건(석탄회 혼합률, 침투율, 침투율 변화량)에서 기준값(침투유량)을 추정할 수 있는 회귀 신경망(neural network, NN) 모델을 개발하였다. 모든 훈련 데이터세트에 대해서 훈련한 최종모델의 신뢰도와 적용성을 검토한 결과 다음 결론을 얻었다. 1) 최종모델의 성능평가지표인 평균절대오차(MAE)는 훈련세트와 테스트세트에 대해서 각각 0.00445와 0.00491로 구해져 적절한 수준으로 훈련되었음을 확인했다. 2) 최종모델은 훈련된 침투율 시계열 구간과 임의 석탄회 혼합률 조건에 대한 다중 다변량 폐색곡선을 추정하기 위해 적용할 수 있을 것으로 확인되었다. 3) 최종모델은 훈련되지 않은 미래 시간스텝에 대한 폐색곡선의 예측이 불가하므로 대안으로 합성곱신경망(CNN) 혹은 장단기 기억 순환신경망(LSTM-RNN) 모델의 적용을 제안하였다.
Trans Abstract
Infiltration filters of LID facilities are frequently confronted with clogging of pores by contaminants. To avoid malfunctioning of LID facilities, filters should be maintained according to the degree of clogging. In this study, clogging was characterized by curves representing the correlation between infiltration rate (IR) and infiltration quantity (Q). To estimate the degree of clogging, a regression neural network model was developed to estimate the label (infiltration quantity) corresponding to the selected features (ash mix ratio, infiltration rate, and variation of infiltration rate). According to the results obtained from the evaluation of accuracy and applicability of the final model trained over the whole training dataset, the following conclusions were drawn: 1) the training of the final model was verified to be correct according to mean absolute errors of 0.00445 and 0.00491 for the training and test datasets, respectively; 2) the final model could be applied to estimate multiple, multivariate clogging curves for arbitrary ash mixing ratios and trained range of time series in terms of infiltration rate; 3) given that the final model could not estimate the clogging curve for future time steps for which the model was not trained, a CNN model or LSTM-RNN model are suggested as an alternative.
1. 서 론
도시 저영향개발(low impact development)을 위해 설치한 침투시설에서 강우유출수 내의 비점오염원은 필터를 통해 제거된다. 공극폐색은 침투하는 강우유출수 내 비점오염원이 필터여재에 침전, 걸림, 흡착으로 제거되면서 공극을 막는 현상이다. 공극이 폐색되면 필터의 침투 및 제거효율이 저감되는 등 침투시설의 기능 저하가 초래된다. 침투시설의 효율적 운영과 기능 유지를 위해 공극 폐색도를 추적하여 적기에 대처해야 한다.
공극폐색도는 침투유량 증가에 따라 감소하는 침투율의 관계인 폐색곡선으로 나타낼 수 있다. 필터의 폐색곡선을 추정하기 위한 경험적, 시험적, 이론적 모델들이 개발되었다(Blazejewski and Murat-Blazejewska, 1997; Du et al., 2013; Hua et al., 2013; Wang et al., 2013). 이들 모델은 일반 특성 조건에 대한 적용성 제한, 긴 개발시간과 과다한 비용, 모델 입력자료의 난해성 등의 문제를 내포하고 있다(Lee et al., 2014).
최근에는 이들 문제를 일부 해결할 수 있는 잠재력을 가진 대안으로 인공지능 알고리즘(Géron, 2019)을 적용한 모델들이 제안되고 있다(Lin et al., 2018; Meade et al., 2018; Chew and Law, 2019; Sliwinski, 2019; Wu et al., 2019). 인공지능모델로서 Lee (2021a, 2021b)는 석탄회 혼합 모래 필터의 폐색도를 추정하기 위한 합성곱신경망모델(Lee, 2021a)과 순환신경망(RNN)모델(Lee, 2021b)을 개발하였다. 이들 모델은 다변량(multivariate), 다중(multiple) 시계열 폐색곡선에 대해서 현재 시간스텝의 특성(feature) 입력값(석탄회 혼합률, 침투율, 침투율 변화량)으로부터 미래 시간스텝의 기준(label) 출력값(침투유량)을 적정한 수준으로 예측할 수 있는 것으로 검증되었다. 하지만 시험성과가 없는 폐색곡선의 예측에서는 현재 시간스텝에 대한 기준값을 적절히 가정해 입력해야 하는 문제가 있었다.
본 연구에서는 폐색곡선에서 임의로 선정한 특성치 조건(석탄회 혼합률, 침투율, 침투유량)에서 임의 시계열에 대한 기준값(침투유량)을 추정할 수 있는 회귀 신경망(neural network, NN) 모델을 개발하였다. 개발한 모델의 신뢰도와 적용성을 다음의 사항들을 주목해 검토하였다. 첫째로 개발모델은 데이터세트의 시계열과 상관없이 특성과 기준의 다변량 상관관계에 대해서만 훈련되었으므로, 시계열 상관관계 특성을 가지는 폐색곡선의 추정에 대한 적용성을 검토했다. 둘째로, 훈련된 시계열 범위 이후의 시계열 예측을 위한 적용성을 검토했다. 셋째로, 훈련되지 않은 임의 석탄회 혼합률 조건에서 필터의 다중 폐색곡선을 추정하기 위한 적용성을 검토했다.
2. 데이터세트
2.1 침투시험 데이터
신경망 모델 개발을 위해 Lee (2021a, 2021b)가 수행한 연구에서 적용한 데이터세트를 사용하였다. 데이터세트는 석탄회 혼합 모래 필터에 대한 실내침투시험(Segismundo et al., 2017)으로부터 구한 침투율과 침투유량의 다변량(multivariate) 상관관계를 가지며 석탄회 혼합률의 변화에 따라 다중(multiple)으로 나타난 폐색곡선으로부터 추출되었다. 데이터세트에서 특성(feature)은 강우유출수 필터의 폐색에 영향을 미치는 침투율(IR), 침투율 증분(ΔIR), 모래 함유량(PS)에 대한 석탄회(저회) 함유량(PA)의 비율로 정의한 석탄회 혼합률(PA/ PS)로 설정했다. 기준(label)은 침투유량(Q)으로 정했다. 여기서 침투유량은 편의상 필터 단면적 0.005027 m2에 대한 물기둥의 높이로 나타냈다. 각 특성과 기준 상호 간의 상관관계를 비선형 상관성 평가에 적절한 Spearman 상관계수로 나타내면 Fig. 1과 같다. Spearman 상관계수는 0.634~0.666의 범위로서 특성과 기준 간에 비선형 상관성이 존재하는 것으로 평가할 수 있었다.
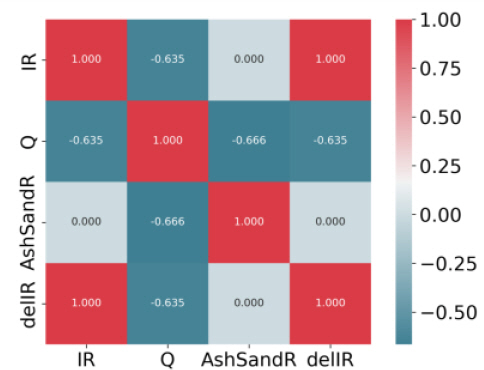
Matrix of the Spearman Correlation Coefficient between Label and Feature
훈련 및 검증에 적용할 데이터세트의 가공에 대한 상세한 설명은 Lee (2021a, 2021b)를 참조할 수 있으며 주요 내용은 다음과 같다. 데이터세트는 석탄회 혼합률에 따른 4가지 침투조건에 대해 각각 Curve0, Curve1, Curve2, Curve3의 기호로 구분했다. 각 데이터세트에 적용한 입력값과 기준값의 범위는 Table 1과 같다. Table 1의 데이터세트에서 폐색곡선의 다변량 관계와 관련한 특성인 침투율(IR)과 침투율 증분(ΔIR)과 기준인 침투유량(Q)의 각 항목 최댓값에 대해 정규화했다. 특성과 기준의 정규화는 딥러닝 모델 학습 및 파라미터 결정 과정에서 가중치 편향을 배제(Chollet, 2018)하기 위함이다. 다만 폐색곡선의 다중특성에 영향을 미치는 석탄회 혼합률은 정규화하지 않았다. 정규화 데이터세트로부터 구한 IR-Q 관계 합성곡선을 Fig. 2에 나타냈다. Fig. 2에 보인 각 합성곡선의 데이터 개수는 58개로서 총 데이터 개수는 232개이다.

Summary of Synthetic IR-Q Curves

Synthetic IR-Q Curves
2.2 데이터세트 분리
모델의 훈련 및 검증을 위해 합성곡선의 데이터를 훈련세트와 테스트세트로 분리하였다. 우선 전체 데이터세트에서 훈련된 모델의 검증을 위한 테스트세트 25%를 추출하였다. 나머지 75%는 모델 훈련세트로 사용하였다. 데이터세트의 분리를 위해 사이킷런(scikit-learn; Pedregosa et al., 2011)의 train_test_split 함수를 사용하였다. 데이터세트의 분리 결과를 예시하기 위해 Fig. 2의 합성곡선의 데이터를 훈련세트와 테스트세트로 분리하여 Fig. 3에 나타냈다. 합성곡선의 총 데이터 개수 232개 중 75%인 174개가 훈련세트, 25%인 58개가 테스트세트로 분리되었다. 훈련세트의 25%는 3.2에서 다룬 하이퍼파라미터 조율을 위한 k-겹 교차검증 및 훈련과정에서 검증세트로 추출하였다.

Training and Testing Datasets after Splitting the Synthetic Clogging Data
3. 신경망모델
3.1 하이퍼파라미터 조율
입력층과 출력층, 은닉층으로 연결된 다층퍼셉트론 구조의 모델을 설정했다. 입력층과 출력층의 뉴런 수는 특성과 기준의 개수와 동일하여 각각 3개와 1개이다. 이 모델의 최적화, 훈련 및 검증에 있어서 Lee (2021c)의 과정을 준용하였다.
그리드 검색(grid search) 방법을 적용하여 Table 2에 보인 하이퍼파라미터(hyperparmeter)에 대해서 최적조건을 결정하였다. 최적 하이퍼파라미터 결정에 소요되는 과다한 검색 부하를 경감하기 위해 각 하이퍼파라미터에 대해 가능한 최소의 종류를 적용하였다. 그리드 검색을 위해 사이킷런의 그리드 검색 클래스를 사용하였다.

Summary of Hyperparameters in Grid Search
그리드 검색 과정에서 파라미터 조율 시 데이터 수가 적으면 검증점수가 검증세트로 선택된 데이터에 의해 큰 영향을 받게 되는 문제점이 있다(Chollet, 2018). 이 문제를 방지하기 위해 k-겹 교차검증(cross validation)을 적용했다. 2.2에서 설명한 훈련세트에 대해서 Table 2의 하이퍼파라미터를 조합한 총 108가지 조건의 모델에 대해 훈련(fit)하였다. 손실함수는 평균제곱오차(mean squared error, MSE)를 적용하고, 측정항목(metrics) 함수로는 평균절대오차(mean absolute error, MAE)를 적용했다.
훈련한 108개 모델의 훈련손실 값을 Fig. 4에 비교하였다. 이들 108개 조합에 대한 검색시간은 인텔 Core (TM) i7-1260P @ 2.10 GHz CPU 컴퓨터에서 7438초가 소요되었다. 이 중 최소 MSE 조건을 만족하는 모델의 하이퍼파라미터는 은닉층의 개수 2, 은닉층의 뉴런수 32, 학습률 0.001, 활성화 함수 ReLU, 옵티마이져는 Adam의 조건으로 결정되었다.

Grid Search Result
최적 하이터파라미터를 적용한 신경망 모델의 모델 구조와 층별 매개변수 수를 Figs. 5(a)와 (b)에 각각 보였다.
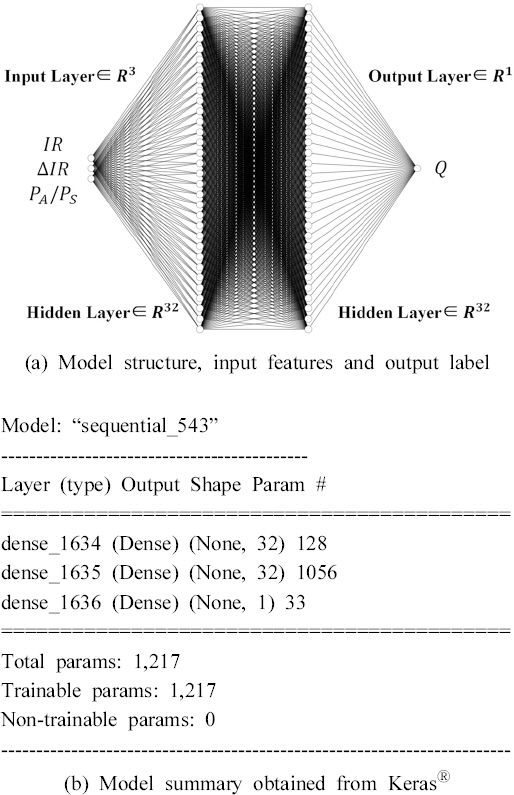
Model Structure and Parameters
3.2 최종모델 훈련 및 평가
최종모델(final model)이란 훈련하지 않은 새로운 데이터를 사용하여 예측할 수 있도록 배포하는 모델이다(Brownlee, 2017). 그리드 검색에서 최적파라미터 조건에 대해 훈련된 모델을 최종모델로 배포할 수 있는지의 여부가 불확실했다. 문헌 및 자료검색 결과 같은 의문점을 가진 연구자들이 많았다(Ng, 2018). Géron (2019)은 그리드 검색에서 구한 최적모델을 테스트세트에 대해 평가한 결과 적절한 성능이 검증되는 경우에 이를 최종모델로서 배포할 것을 제안했다. 반면 Chollet (2018)는 그리드 검색의 최적모델을 훈련데이터세트에 대해서 훈련한 후, 테스트세트에 대한 성능평가에서 적절한 결과를 얻는 경우에 훈련한 모델을 최종모델로서 배포할 것을 제안했다.
전반적으로는 Chollet (2018)가 제안한 바와 같이 결정된 최적하이퍼파라미터를 적용한 모델을 다시 훈련 및 검증하여 최종모델로 배포할 것을 제안하고 있었다. Brownlee (2017), Ng (2018)은 이 제안이 적절한 이유를 다음과 같이 설명하였다. 교차검증은 모델을 구성하는 모든 과정들(알고리즘, 하이퍼파라미터 등)이 미래의 새로운 데이터에 대해서 적절히 구현될 것인지를 평가하는 과정이다. 교차검증에서 훈련된 최종모델은 이러한 목적으로 수행된 것에 불과하다. 따라서 최종모델은 교차검증에서 찾아낸 최적의 과정들로 구성한 모델을 모든 데이터세트에 대해서 새롭게 훈련하여 구한다(Brownlee, 2017; Ng, 2018).
Chollet (2018)가 제안한 최종모델 훈련방법에 따라 3.1에서 구한 최적 하이퍼파라미터를 적용한 신경망 모델을 훈련세트와 테스트세트에 대해 훈련 및 검증하였다. 이 연구에서는 훈련할 수 있는 데이터 수가 비교적 적은 편이므로 과대적합의 문제가 발생할 가능성이 있었다. 따라서 훈련과정에서 조기종료(early stopping)를 적용하고 적정한 에폭(epoch) 수에 대해 검증하였다. 훈련에서 발생할 수 있는 과대적합의 가능성을 예시하기 위해 모델 훈련 시 에폭에 따른 손실의 변화를 Fig. 6에 보였다. Fig. 6의 결과에서 조기종료에 의해 과대적합이 방지되었음을 알 수 있었다.
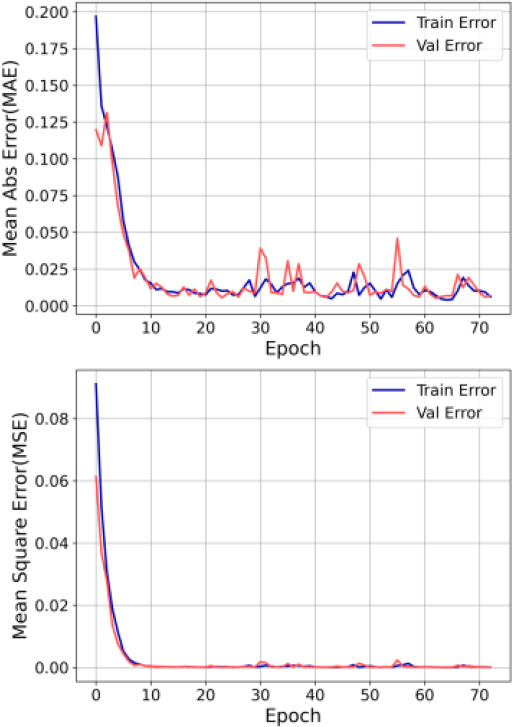
Variation of Errors with Epochs
최종모델의 훈련세트에 대한 MSE는 0.0000320, MAE는 0.00445 (최대 침투유량 98.685 m에 대한 침투유량 절대오차 0.439 m)이었다. 검증세트에 대한 MSE는 0.0000346, MAE는 0.00392였다. 최종모델을 테스트세트에 대해 검증한 결과 MSE는 0.0000402, MAE는 0.00491 (침투유량 절대오차 0.485 m)이었다. 테스트세트에 대한 MAE가 훈련세트 보다 다소 높게 나타났고 조기종료를 적용하여 과대적합이 발생하지 않은 것으로 판단되었다.
최종모델로부터 구한 예측값의 신뢰도를 보기 위해 모든 데이터세트에 대해서 예측값을 기준값과 비교한 결과를 검토하였다. Fig. 7에 예측값과 기준값 간의 오차분포를 나타냈다. Fig. 8에는 예측값과 기준값 간의 상관관계를 나타냈다.

Distribution of Error for the Final Model

Correlation between the Predicted and the Measured Data
Fig. 7의 결과에서 훈련세트와 테스트세트에 대한 오차분포가 유사하게 나타났다. 과대적합이 발생하는 경우에 테스트세트에 대한 오차분포가 훈련세트의 경우보다 넓게 나타날 것이다. Fig. 7에서는 서로 유사한 분포를 보이므로 과대적합의 가능성이 낮은 것으로 판단되었다. 기준값에 대한 예측값의 일치성 수준은 이들 값 간의 상관성을 나타낸 Fig. 8의 결과에서도 확인할 수 있었다. 기준값과 예측값은 훈련세트와 테스트세트에 대해서 Pearson 상관계수로서 각각 0.9999와 0.9996 수준의 일치성을 보였다.
4. 최종모델의 적용성 평가
4.1 시계열 폐색곡선 예측
최종모델은 데이터세트의 시계열과 상관없이 특성(침투율 증분과 침투유량)과 기준(침투율)의 다변량 상관관계에 대해서 훈련되었다. 따라서 시계열 상관관계 특성을 가지는 폐색곡선의 추정을 위한 최종모델의 적용성을 검토하기 위해 최종모델로부터 예측 폐색곡선을 구하고 Fig. 2의 시험 폐색곡선과 비교하여 Fig. 9에 나타냈다. Fig. 9의 결과에서 보듯이 훈련된 석탄회 혼합률 조건에서 최종모델은 시계열 폐색곡선의 기준값을 양호하게 예측했다. 결과적으로 개발한 최종모델은 시계열 특성에 대한 별도의 훈련 없이 훈련된 시계열 구간과 석탄회 혼합률에 대한 폐색곡선의 추정에 적용할 수 있을 것으로 평가되었다. 하지만 훈련되지 않은 시계열 구간 및 임의의 석탄회 혼합률을 가지는 조건까지 최종모델의 적용성을 확대할 수 있는 지의 여부는 불확실하므로 다음 절에서 이에 대한 검토를 수행했다.

Comparison of Clogging Curves Obtained from the Experiment and the Final Model
4.2 미래 시간스텝 시계열 예측
훈련된 시계열 이후의 폐색곡선 추정을 위한 회귀 신경망 모델의 적용성을 검토하기 위해서 시계열 1.0~0.45 침투율 구간의 데이터에 대해서만 훈련한 새로운 모델을 준비했다. 새로운 모델을 이용하여 훈련된 시계열 구간(1.0~0.45)과 훈련되지 않은 시계열 구간(0.45~0.0)까지 포함하여 구한 예측 폐색곡선을 시험 폐색곡선과 비교하여 Fig. 10에 보였다.
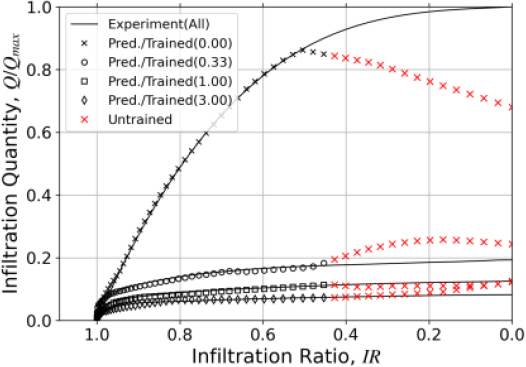
Incorrect Predicted Clogging Curves for the Out of Trained Time Rage
Fig. 10에서 모델은 훈련된 시계열 구간의 시험 폐색곡선을 양호하게 예측했다. 하지만 훈련되지 않는 구간에서는 시험 폐색곡선을 예측하지 못했다. 예측 폐색곡선의 오차는 침투율이 0, 즉 완전폐색 상태에 대한 시험 폐색곡선의 수렴도가 낮을수록(석탄회 혼합률이 낮을수록) 증가하는 것으로 나타났다. 따라서 필터가 완전폐색 되기 전에 침투시험이 종료되었고 이 데이터에만 국한해서 훈련한 회귀 신경망모델은 시험 중단 이후의 침투율 시계열 구간에 대한 폐색곡선 예측에는 적용할 수 없음을 알 수 있었다.
이 경우 시험 중단 이후의 미래 시간스텝을 포함한 시계열 전 구간의 폐색곡선을 예측하기 위해 합성곱신경망( convolutional neural network, CNN) 혹은 장단기 기억 순환신경망(Long Short Term Memory - Recurrent Neural Network, LSTM- RNN) 모델의 적용을 고려할 수 있다. Lee (2021a, 2021b)는 폐색곡선 추정을 위한 이들 모델의 적용을 제안하였다.
4.3 임의 석탄회 혼합률 조건의 필터
임의 석탄회 혼합률에 따른 다중 폐색곡선 예측을 위한 최종모델의 일반화 가능성을 평가했다. 이를 위해 필터조건으로 석탄회 혼합률(PA/PS)을 0.25, 0.43, 2.33, 4.00으로 변화시킨 4가지 필터를 가정하였다. 최종모델을 사용하여 이들 필터에 대한 예측 폐색곡선을 구하고 이를 시험 폐색곡선과 비교하여 Fig. 11에 보였다.

Predicted Multiple Clogging Curves for the Untrained Conditions of Ash Ratio
Fig. 11의 결과에서 석탄회 혼합률이 증가할수록 순차적으로 폐색도가 빠르게 증가하는, 즉 침투율 감소가 상대적으로 빨라지는 전반적 경향을 반영하고 있음을 볼 수 있었다. 따라서 훈련된 시계열 구간에서 최종모델의 석탄회 혼합률에 대한 일반화 가능성이 검증되었다.
4.2에서와 마찬가지로 훈련된 시계열을 벗어난 구간에 대한 폐색곡선의 예측을 위해서는 CNN 혹은 LSTM-RNN 모델의 적용이 필요하다. 석탄회 혼합률에 대한 최종모델의 일반화 가능성이 검증되었으므로 CNN 혹은 LSTM-RNN 모델의 현재 시간스텝 기준값으로 최종모델의 예측값을 적용할 수 있을 것으로 판단되었다.
5. 결 론
신경망 알고리즘을 사용하여 강우유출수 석탄회 혼합 모래 필터의 폐색을 추정하는 모델을 개발하고 적용성을 평가한 연구 결과 다음과 같은 결론을 도출할 수 있었다.
1) 최적 하이퍼파라미터를 적용하여 모든 훈련 데이터세트에 대해 훈련한 최종모델은 훈련세트와 테스트세트에 대해 MAE가 각각 0.00445와 0.00491로 나타났다. 조기종료를 적용한 훈련으로 모델의 과대적합을 방지할 수 있었다.
2) 최종모델의 예측값과 기준값 간의 상관관계는 Pearson 상관계수의 값으로 훈련세트에 대해서 0.9999, 테스트세트에 대해서 0.9996 수준의 일치성을 보였다.
3) 최종모델에서 훈련되지 않은 미래 시간스텝까지 폐색곡선의 확장이 필요한 경우에는 CNN 혹은 LSTM-RNN 모델의 적용을 제안하였다.
4) 최종모델은 훈련된 시계열 구간과 임의 석탄회 혼합률 조건에서 다중 다변량 폐색곡선의 추정을 위해 적용할 수 있을 것으로 평가되었다. CNN 혹은 LSTM-RNN 모델의 적용 시 침투시험을 시행하지 않아 현재 시간스텝에 대한 기준값이 없는 경우에 최종모델의 예측값을 적용할 수 있을 것으로 판단되었다.