인공신경망을 이용한 중소하천 수위예측
Water Level Prediction of Small and Medium-Sized Rivers Using Artificial Neural Networks
Article information
Abstract
우리나라는 여름(6월~8월)에 태풍과 장마전선에 의한 강우발생이 빈번하게 일어나는 기후양상을 갖고 있으나 최근 몇 년간 기후변화로 인하여 국지성호우가 돌발적으로 발생하는 일이 빈번하게 일어나고 있다. 이러한 국지성 호우 및 돌발 홍수는 짧은 시간 안에 많은 강우를 내리기 때문에 하도 폭이 좁은 중⋅소하천의 경우 하천 수위가 급격하게 상승하여 많은 피해를 발생시킨다. 대부분의 대하천의 경우 물리적인 모형인 강우-유출 모형을 활용하여 강우사상에 따른 하천수위를 예측하고 홍수 예⋅경보를 통하여 피해를 최소화한다. 하지만 중⋅소하천의 경우 대 하천에 비하여 하천에 대한 데이터 구축이 미비하고 이는 물리적 모형을 통한 정확한 홍수 예⋅경보의 어려움으로 이어지고 있다. 이에 본 연구에서는 환경부에서 제공하는 최소한의 수문 정보와 인공신경망을 활용하여 중⋅소하천의 수위를 예측하여 선행시간(Lead Time)을 확보하고자 한다.
Trans Abstract
Typhoons and rainy seasons are typically a frequent occurrence in Korea’s summer climate (June to August); however, the frequency of local heavy rains has increased in recent years owing to climate change. These heavy rains are characterized by substantial rainfall within a short period of time, causing flash flooding. This in turn causes the water level of small and medium-sized rivers with a narrow river channel to increase rapidly, resulting in considerable damage. The rainfall-runoff model is a physical model that is used to predict the river level of most large rivers according to rainfall events, and damage is consequently minimized through flood forecasting and warning. However, data construction on small and medium-sized rivers is insufficient compared to that on large rivers, thereby leading to difficulties in accurate flood forecasting and warning through physical models. This study, therefore, attempts to predict the river level of small and medium-sized rivers using minimal information provided by the Ministry of Environment and artificial neural networks.
1. 서 론
우리나라를 포함한 전 세계적으로 기후변화로 인한 국지성호우 및 집중호우가 돌발적으로 발생하는 일이 빈번하게 일어나고 있다. 이러한 국지성 호우 및 돌발 홍수는 비교적 짧은 시간 안에 많은 강우를 내리기 때문에 큰 규모의 피해를 발생시킨다. 대부분의 대하천의 경우 강우-유출 모형과 같은 수치모형을 활용하여 홍수예경보가 이뤄진다. 이러한 모형은 수문학적 특성을 매개변수 화하여 해당 지역에 국한된 모형을 구성하게 된다. 하지만 해당 시점에 따른 매개변수 최적화는 이뤄지기 어려우며 이로 인한 모의결과는 정확성이 떨어지기도 한다. 그러나 최근 다양한 센서들이 설치가 이루어지며 빅데이터들이 생성되고 전산데이터를 처리하는 컴퓨팅이 발달함에 따라 인공신경망을 이용한 홍수 예측 연구가 활발히 이뤄지고 있다.
국외에서는 Elsafi (2014)은 최소한의 정보를 이용하여 물리적 모델보다 빠른 예측이 가능한 ANN 모델을 다양하게 구성하여 다양한 수위 관측소 조합을 이용하여 최적의 예측 모델을 구축하여 높은 정확도를 보였으며 물리적 모델 대체 가능성을 제시하였다. Bustami et al. (2006)이 말레이시아 일 수위를 순방향 인공신경망을 통해 예측한 연구를 수행하였다. 또한 Tsakiri et al. (2018)은 ANN과 MLR을 이용하여 홍수위 예측하는 연구를 진행하였다. Thirumalaiah and Deo (1998)은 3가지의 인공신경망 알고리즘을 활용하여 홍수기의 홍수예측 연구를 하여 인공신경망의 활용가능성을 확인하였으며 Chen et al. (2012)는 ANN을 활용하여 태국의 하천 수위를 예측하고 2D와 3D 유체동역한 모델과 결과를 비교하여 ANN의 효과성을 입증하였다. 홍수위를 예측하는 연구이외에 Aichouri et al. (2015)는 강우-유출의 물리적 거동을 학습하고 유속을 예측하는 연구를 진행하여 ANN의 효율성을 입증하였다. 더불어 국내에서는 Jung et al. (2018) 딥러닝 기반의 LSTM 모형을 이용하여 감조하천 수위를 예측하였으며 Lee et al. (2018)은 메콩강 유역에 대하여 인공신경망과 물리적 모형의 정확도를 비교하여 데이터기반의 모형 적용 가능성을 입증하였다. Yu et al. (2021)은 물리적 모형보다 입력 자료가 적어 빠른 시간안에 학습과 예측이 가능한 인공신경망 모델의 장점을 이용하여 3시간에서 6시간의 선행시간으로 금강 유역의 하천 수위를 예측하도록 최적의 모형을 구축한 연구를 진행하였다.
국내를 비롯한 국외에서 인공신경망을 기반으로 한 다양한 하천 수위예측 모델이 제시 되었으나 대부분의 대상유역은 대하천으로 국한되어있다. 대부분 대하천의 수위는 하폭이 크므로 시간별 변동성이 적고 물리적 모델에 적용 가능하도록 관련 수문데이터가 다양하다. 하지만 대하천이 아닌 중소하천의 경우 비교적 자료가 부족하고 리드타임의 부족으로 인하여 정확한 홍수 예⋅경보가 어려운 실정이다. 또한 중⋅소하천은 하도 폭이 좁아 국지성 호우 및 돌발홍수 발생 시 하천 수위가 급격하게 상승하여 많은 피해를 야기한다. 따라서 본 연구에서는 물리적 모델을 적용하기 위한 데이터 구축 및 예측 결과 도출에 소요되는 시간을 줄일 수 있도록 최소한의 데이터만으로 정확하고 신속한 예측이 가능한 인공신경망 모델을 활용하여 중⋅소하천에 대한 홍수위예측을 하고자 한다. 본 연구에서는 환경부에서 제공하는 하천 수위 및 강우량 정보를 활용하여 최적의 입력 자료를 구성하고 인공신경망 모델을 적용하여 문경시 영강의 수위를 예측 하고자 한다.
2. 본 론
2.1 연구 방법론
2.1.1 Artificial Neural Network (ANN) model
본 연구에서는 인공신경망(Artificial Neural Network, ANN)을 활용하여 하천 하류 수위를 예측하였다. 인공신경망은 생물학적 신경망의 구조와 기능을 기반으로 한 계산 모델이다. Fig. 1에서 볼 수 있듯, ANN 모델은 입력층과 출력층, 이 사이에 있는 은닉층으로 구성되어있으며 각 층은 가중치를 가진 뉴런들로 연결되어있는 모델이다. 선형데이터뿐만아니라 이미지, 음성 인식 등과 같은 비선형관계를 가진 데이터 예측 및 분류에 모두 사용될 수 있는 장점을 가진 모델이다. 본 연구에서는 비선형관계를 가진 각각의 데이터를 활용하여 수위를 예측하는 데 사용될 기법이다.
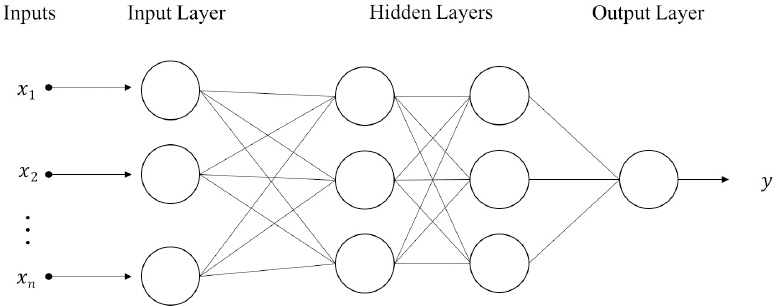
Structure of ANN Model
2.1.2 정확도 분석 기법
본 연구에서는 강우데이터와 하천 수위 데이터로 이루어진 입력자료를 다층퍼셉트론 ANN 모형으로 학습시키고 하천 하류 예측 결과에 대한 통계적인 분석을 통하여 입력데이터 조합에 따른 예측 정확도를 비교하고자 한다. 이에 대한 판단 지표로 평균제곱근오차(Root Mean Square Error, RMSE), Nash-Sutcliffe 효율성계수(The Nash-Sutcliffe efficiency Coefficient, NSE)와 피어슨 상관 계수(Pearson Correlation Coefficient, CC)을 사용하였으며, 각각의 공식은 Eqs. (1)~(3)과 같다.
정량적인 오차분석을 위한 RMSE은 실제 관측 수위 값과 예측 수위 값의 오차를 나타내므로 예측 모델의 정확성을 판단할 수 있다. Eq. (1)의 xp,i는 i번째 예측(Prediction)값을, xo,i i번째 관측(Observation)값을 나타내며 n은 데이터의 총 개수이다. 모델의 정확도를 판단하기 위하여 Nash-Sutcliffe 효율성 분석도 진행하였다. NSE는 실측값과 시계열 모델로 예측한 값과의 오차에 대한 분산을 관측 값의 분산 값으로 나눈 값으로 수문학 모델의 예측 정확도를 나타내는 지표이다. 추정한 값의 오차 분산이 0에 가까운 모형일수록 NSE는 1과 가까운 값을 나타낸다(Nash and Sutcliffe ,1970). Eq. (2)의 xp과 xo은 각각 예측 값과 관측 값을 의미한다. 마지막으로 피어슨 상관계수인 CC를 통하여 두 변수간의 상관관계를 정량화한 통계적인 분석을 진행하였으며 1에 가까울수록 예측 값과 실측값의 상관이 높음을 판단할 수 있다.
2.2 모형 적용
2.2.1 입력 자료 구축
Fig. 2는 경상북도 문경시에 위치한 영강이다. 농암 강우관측소와 김용리 강우관측소의 위치를 삼각형으로 표시하였으며 원형 마커는 갈마교, 불정동, 김용리에 위치한 수위 관측소의 위치를 나타낸다. 본 연구에서는 입력데이터로 상류에 위치한 갈마교와 불정동 수위, 농암 및 김용리 강우자료를 사용하였으며 하류에 위치한 김용리 수위를 예측하였다. 수위 예측 시 사용한 자료는 2016년부터 2020년까지 장마기간(06월~08월)의 10분 단위 수위와 강우 데이터이며 모든 자료는 환경부의 낙동강홍수통제소 홈페이지에서 확보하였다. 각각의 자료의 출처와 기간에 대해 Table 1과 같이 정리하였다.
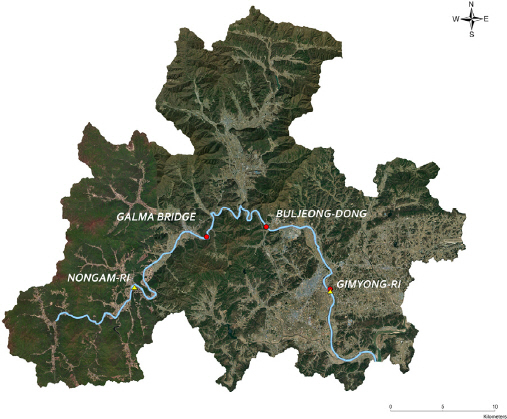
Young River Catchment

Input Data Characteristics
수위 데이터에 대한 상관성 분석을 진행하기 위해 Fig. 3과 같이 동시간대의 세 관측소의 하천 수위를 비교하였다. 각 관측소들의 도달시간을 알기위해 갈마교와 불정동, 갈마교와 김용리, 불정동과 김용리 관측소를 비교하였다.

Water Level of Observation Stations
갈마교와 불정동은 대략 120분, 불정동과 김용리는 130분, 갈마교와 김용리는 첨두 수위의 시간차가 약 250분이었다. 선행시간을 확보하기 위해서 김용리에서 가장 멀리 위치하여 있는 갈마교 수위관측소의 현재시점에서 약 2시간의 선행시간을 가진 예측을 하고자 도달 시간만큼의 시간차이를 미리 계산하여 학습 데이터로 구성하였다. 관측소의 각 시간대의 차이는 Table 2와 같이 정리된다.

Input Dataset Case
입력 데이터 구성의 최적화를 위하여 각 관측소의 도달시간을 적용한 10가지의 입력데이터 케이스를 구성하였으며 Table 3와 같이 정리하였다. 강우데이터의 유무 및 각 수위 데이터의 유무로 하여 총 10가지의 케이스를 구성하였다.

Input Dataset Case
2.2.2 예측 모델 구축
총 10가지의 입력데이터 케이스를 이용하여 김용리의 수위관측소의 수위를 예측하기 위한 신경모형을 ANN 모형을 구축하였으며 2016년부터 2020년까지의 10분 단위 자료에 대한 예측 수위와 관측 수위값을 비교⋅분석하였다. 최적화 알고리즘은 Adam모형을 사용하였으며 활성함수로는 Rectified Linear Unit (ReLU) 함수를 활용하였다. ReLU 함수는 Fig. 4와 같이 입력변수 x에 따른 함수 F(x)값이 0보다 작으면 가중치가 0이 되고 0보다 크면 입력 값을 그대로 유지하여 기존의 Sigmoid 함수와 Tanh 함수보다 학습이 빠르고 연산비용이 적으며 기울기 소실 문제를 해결하여 가장 많이 사용되는 함수이다. 모형 구축은 Python 오픈소스 라이브러리인 Keras를 사용하였다.
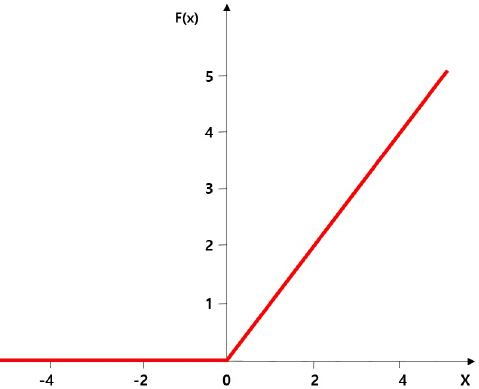
ReLU Activation Function
각 수위관측소와 강우량의 단위가 달라 학습에 방해가 될수 있으므로 Standard Scaler를 사용하여 데이터 값의 정규화(Normalization)를 진행한 후 입력데이터로 구축하였다. 표준정규화 방법은 Eq. (4)를 이용하여 평균을 0, 분산을 1이 되도록 정규화시키는 과정이다. Eq. (4)의 μ은 평균값이며 σ은 표준편차를 의미한다. 이러한 스케일링(Scaling) 과정은 변수들의 단위 차이로 인한 학습 오류를 방지하고 최적화 과정에서의 안정성과 수렴 속도를 향상시킬 수 있어 모든 입력변수들에 대한 정규화를 진행해주었다. 또한 은닉층의 경우 ANN 모델의 경량화와 Over-fitting의 문제를 고려하여 3개의 층으로 구성하도록 하였다.
3. 모의 결과 및 분석
본 연구에서는 문경시에 위치한 두개의 수위관측소의 수위 데이터와 강우관측소 데이터를 활용하여 김용리 관측소의 수위를 예측하였다. 입력자료 전 기간의 70%를 모형의 학습 자료로 사용하였으며 20%를 검증자료로 사용하고 10%의 입력 데이터에 대한 예측을 진행하고 정확도를 평가하였다. Table 4는 영강에 위치한 김용리 수위관측소의 수위를 예측하고 각 데이터 세트에 따른 예측값과 실측값의 평균제곱근오차(RSME)와 Nash-Sutcliffe 효율성계수(NSE)와 피어슨 상관 계수(CC) 분석 결과를 나타낸다. 그 결과 두 개의 강우관측소 자료와 수위 관측소의 데이터를 모두 활용한 데이터 Case 10이 가장 높은 정확도를 보여주는 것을 확인하였다.

Comparison of Accuracy about Dataset Cases
Figs. 5와 6은 Case 1에서 10까지 각각 데이터 세트의 예측 결과 값을 나타낸다. Case 1과 Case 4의 NSE 값을 비교하였을 때 김용리 관측소에서 비교적 가까운 불정동 관측소보다 갈마교 수위 데이터로 예측한 값이 수위의 증감 패턴을 가장 좋은 정확도를 보이는 것으로 확인하였다. 또한 갈마교 수위 데이터에 강우 데이터를 추가한 Case 2, Case 3의 경우 정확도가 상승하지만 불정동 수위 데이터에 강우 관측 데이터를 추가한 Case 4, Case 5의 경우 RMSE가 높아진다. 이는 단순히 데이터양의 증가가 정확도를 높이는데 기여하는 것이 아닌 데이터의 조합에 따라 보다 정확한 예측이 가능하다는 것을 보여준다. Case 4, Case 5과 Case 6의 그래프를 Fig. 5에서 비교하였을 때 모두 동일한 그래프 양상을 가진 것을 확인 할 수 있는데, 정확도는 낮아지지만 CC값이 일정하게 유지되는 것으로 보아 인공신경망 모델에서 하천 수위 데이터의 가중치가 가장 큰 것을 유추해볼 수 있다. 농암리 강우관측소의 자료를 제외한 Case 9와 모두 포함한 Case 10 데이터 세트가 서로 비슷한 NSE와 CC 값을 보였으나 Case 9가 Case 10 데이터 세트에 비해 실제 관측 값보다 작게 예측하여 RMSE가 크게 나온 것으로 판단된다. 또한 관심 수위인 2.9 m를 넘어가면 예측 값의 정확도가 떨어지는 것을 확인 할 수 있었으며 이는 관심 수위를 넘어가는 수위 데이터의 양이 적은 점과 모델의 활성 함수인 Relu 함수의 양극단 값을 포함하여 계산하는 특징 때문에 오차가 커지는 것으로 판단된다. 다만 Case 10 데이터 세트의 경우 관심 수위를 넘어서는 관측 값과 예측 값의 편차가 다른 데이터 케이스에 비해 적은 것을 확인할 수 있으며 해당 지역 수위 하천 예측을 위해서는 Case 10의 데이터 조합이 가장 효과적인 예측을 할 수 있음을 알 수 있었다.
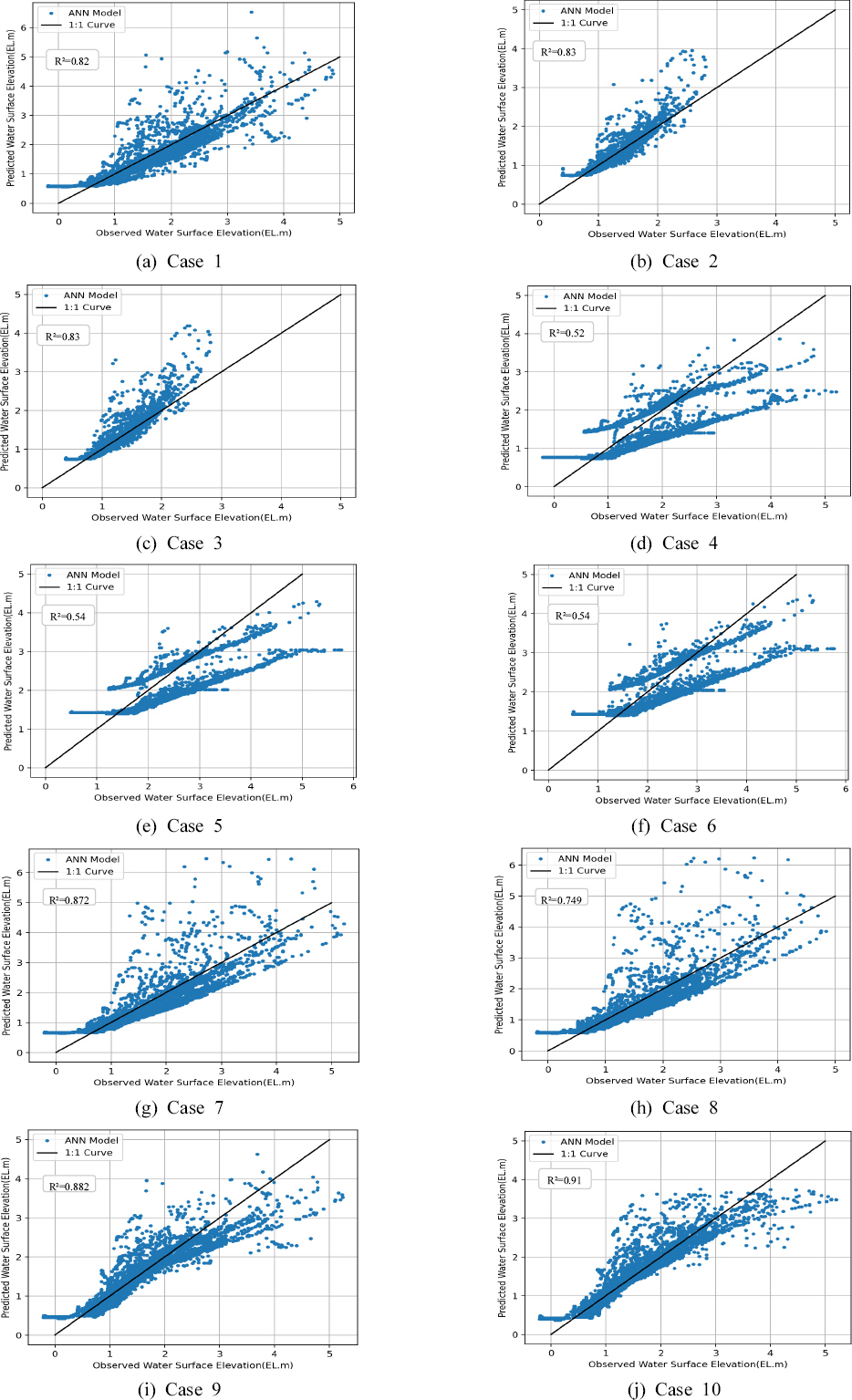
Scatter Plot of Predicted Water Surface Elevation and Observation
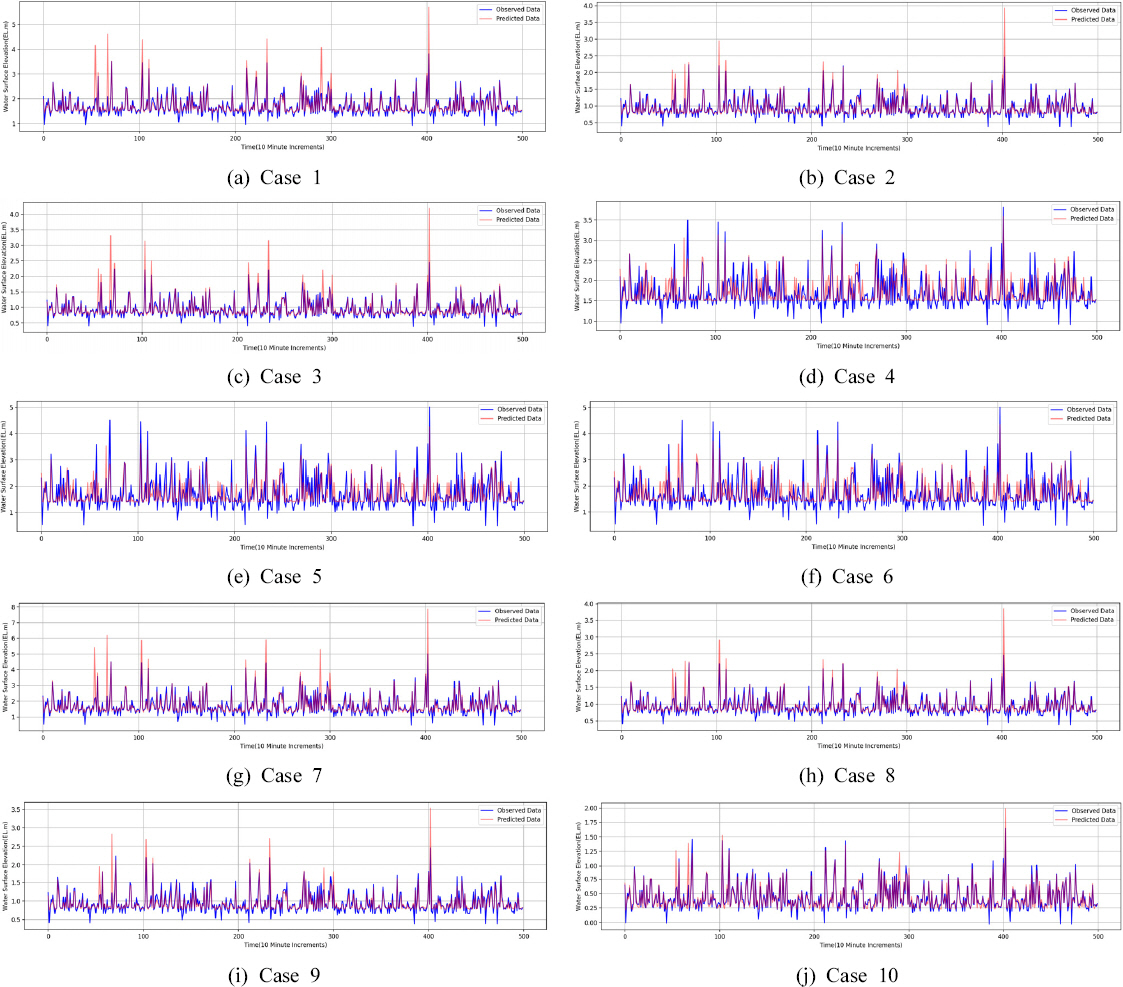
Line Graph of Predicted Water Surface Elevation and Observation
4. 결 론
본 연구에서는 문경시에 위치한 지류하천에 대하여 강우데이터와 하천 수위 데이터로 이루어진 입력 자료를 ANN 모형으로 학습시키고 하천 하류인 김용리 관측소의 수위를 예측하였다. 입력 데이터는 각 관측소의 도달시간을 고려한 총 10개의 조합의 데이터 세트를 구성하였다. 이에 포함된 수위 데이터는 갈마교, 불정동 관측소와 김용리 관측소의 10분 수위 데이터를 활용하였으며 강우자료는 농암리와 김용리 강우 관측소 데이터를 활용하였다. 입력 자료의 경우 70%를 학습에 사용하였으며 20%와 10%를 각각 검정과 평가에 사용하였다. 각 데이터 조합의 결과는 평균제곱근오차, Nash-Sutcliffe 효율성 분석과 피어슨 상관성을 분석하고 비교하였다. 그 결과 갈마교와 불정동 수위 데이터만을 이용하여 수위를 예측한 경우 RMSE, NSE와 CC는 각각 0.21 m, 0.66, 0.85와 0.27 m, 0.06, 0.73이 도출되었으며 이 두 가지 수위관측소의 수위를 모두 활용한 결과는 RMSE 0.31 m, NSE 0.6 그리고 CC는 0.86로 두 데이터 조합의 결과와 비슷한 오차를 보였다. 각 수위 관측소와 강우데이터를 함께 입력 자료를 구성한 경우 갈마교와 강우량의 조합이 불정동과 강우량 데이터의 조합보다 나은 정확도를 보였으며 강우 데이터를 제외한 경우보다 높은 정확도를 보여 데이터의 양보다 입력 데이터의 조합이 정확도에 미치는 영향을 더 큰 것을 알 수 있었다. 또한 불정동 하천수위 데이터와 불정동, 각 강우 관측소 데이터의 조합을 입력 자료로 활용하였을 경우의 그래프와 정확도를 비교하였을 때 그래프의 양상이 동일함을 확인 하였으며 하천 수위 데이터가 전체적인 수위 예측 패턴에 큰 영향을 미치는 것과 강우가 세밀한 수위 예측에 보다 관여하는 것을 알 수 있었다. 또한 모든 데이터를 활용하였을 때의 정확도가 가장 높은 것과 관심 수위를 넘어서는 수위의 예측 정확도가 높은 점을 통하여 김용리 관측소와 불정동 관측소, 두 개의 강우 관측소를 모두 조합한 입력데이터가 가장 효과적인 데이터 조합이라는 것을 확인하였다. 모델의 경량화와 정확도를 고려하였을 때 강우 발생 시 빠른 속도로 수위가 상승하는 중소하천 예측에 선행시간 이 확보가능하고 적은 자료로도 높은 정확도를 보이는 인공신경 모델을 적용 가능하다고 사료된다.
감사의 글
본 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구입니다(No.2020R1A2C2014937).