



1. 서 론
공학적 문제의 제반 물리현상을 예측하는 수학적, 시험적 상관관계를 머신러닝과 딥러닝 인공지능 모델로 대체하려는 연구가 다양한 분야에서 널리 수행되고 있다(Dramsch, 2019; Zhou et al., 2019; Wei et al., 2020). 이 논문에서 다루는 필터폐색 문제와 더불어서 다공성 필터, 정수시스템, 대수층 투수 등 유사한 문제들에 대한 연구도 수행되고 있다(Lin et al., 2018; Meade et al., 2018; Chew and Law, 2019; Sliwinski, 2019; Wu et al., 2019).
공학 분야에서 인공지능모델의 적용에 대한 연구 빈도가 증가되고 이유로는 고전적 모델과 비교하여 인공지능모델이 가진 본질적 장점 때문으로 생각된다. 고전적 이론모델에서는 데이터로부터 현상을 추정할 수 있는 수학적 규칙을 추출한다. 모델의 정확성을 향상시키기 위해서는 일반적으로 수식이 복잡해지고 더 많은 수의 입력자료가 요구된다. 적절한 입력자료를 결정하는 것이 결과의 신뢰도를 크게 좌우한다. 하지만 입력자료 결정을 위해서는 시험결과나 경험적 자료들이 필요하며 일반적으로 결정하기가 쉽지만은 않은 것이 사실이다. 인공지능모델은 설정한 특성(features)과 기준(labels) 간의 관계를 축적한 데이터를 훈련하여 개발된다. 개발된 모델의 적용단계에서는 특성변화에 대한 예측값(prediction)을 추정하고 기준값에 대한 예측값의 오차로 모델의 신뢰도를 평가한다. 인공지능 모델의 성패는 신뢰성 있는 데이터의 확보 여부에 영향을 받는다는 점에서 한계가 있다. 그럼에도 불구하고 고전적 이론모델에서 요구되는 복잡한 입력변수의 결정을 배제할 수 있다는 장점이 있다.
다공질 여재를 사용하는 필터에서 폐색도를 예측할 수 있는 모델을 개발하기 위한 연구가 꾸준히 수행되어 왔다(Blazejewski and Murat-Blazejewska, 1997; Du et al., 2013; Hua et al., 2013; Wang et al., 2013). Lee et al. (2014)은 기존 폐색모델의 적용성을 검토하였으며 전반적으로 모델의 신뢰도 확인이 어렵고 요구되는 자료입력이 난해함을 확인하였다.
필터폐색 정보는 강우유출수 처리시설의 효율적 운영과 기능유지를 위한 의사결정과정에서 필수적인 요소이다. 따라서 기존 이론모델의 약점을 보완하고 필터폐색 정보를 상대적으로 용이하게 추정할 수 있는 모델개발의 필요성이 있다. 필터 폐색은 시계열 상관관계 문제로서 다양한 인공지능 알고리즘(Géron, 2019)을 적용하여 해석이 가능할 것으로 예상되었다.
필터 폐색문제를 다루는 인공지능 모델 개발에 대한 문헌조사 결과 다음과 같은 연구들이 수행되었음을 알 수 있었다. Wu et al. (2019)은 다공성 매질의 유효투수계수를 2차원 단면영상으로부터 예측하는 CNN 모델을 제안하였다. 모델은 lattice Boltzmann model (LBM)모사를 통한 예측보다 경제적인 해석방법으로 평가되었다. 또한 기존 경험식보다 정확한 예측결과를 나타냈다. 따라서 다공성매질의 투수성 예측에 유용한 기술로서 현장 학습된 딥러닝 모델의 적용을 제안했다. Sliwinski (2019)는 선박 평형수 처리를 위한 필터시스템에서 발생하는 폐색을 예측하기 위해 long short term memory (LSTM) 모델과 CNN 모델을 개발했다. 두 모델 모두 폐색도 예측에 유용하게 활용할 수 있었지만 최적화를 위한 추가 연구의 수행을 제안했다. Ahmadi and Chen (2019)은 지질정보와 conventional ANN, fuzzy decision tree, imperialist competitive algorithm (ICA), particle swarm optimization (PSO)와 같은 머신러닝 방법을 융합하여 원유저장시설 지질의 공극과 투수성을 예측하는 모델을 개발했다. 개발한 모델을 보다 확실하고 안정적인 저장시설 건설을 위해 활용할 것을 제안했다. Lin et al. (2018)은 폐색예측을 위한 방안으로 artificial neural network (ANN)을 적용한 모델개발을 시도했다. 개발된 모델을 다양한 운영조건의 강우유출수 필터에서 발생하는 폐색을 추정하여 시험자료와 비교하였다. 그 결과 미미한 오차가 있었지만 다양한 조건의 필터에 대한 설계와 운영에서 모델적용의 이점을 확인하였다.
이와 같이 다양한 분야의 필터폐색 문제에서 머신러닝, 딥러닝 모델이 개발되고 있음에도 불구하고 개발 및 응용수준은 아직 초기단계인 것으로 판단되었다. 이와 같은 연구의 일환으로 이 논문에서는 강우유출수 침투시설에서 빈번히 적용되는 저회 혼합 모래 필터에서 발생하는 공극폐색을 추정하는 합성곱신경망(CNN)모델을 개발하였다. 개발한 모델에 대해서 필터 폐색 예측 문제에 대한 신뢰도와 효율성 및 일반화 가능성을 검토하였다. 이 결과를 바탕으로 다양한 공학모델 개발을 위한 도구로서 인공지능 알고리즘 적용의 타당성을 점검해 보았다.
2. 데이터
합성곱신경망 폐색모델의 훈련 및 검증을 위한 데이터로는 Lee (2021)가 구축한 데이터셋트를 사용하였다. 현재 데이터셋트의 샘플수가 충분히 축적되지는 않았지만 이러한 유형의 데이터가 지속적으로 축적된다면 향후 다양한 인공지능 폐색모델 개발을 위한 빅데이터로 활용할 수 있을 것으로 판단되었다. 이 절에서는 데이터셋트 적용에 있어서 용이하게 참조할 수 있도록 관련한 주요 내용을 재기술하였다.
2.1 침투시험 데이터
데이터셋트는 강우유출수 침투시설 필터에서 발생하는 폐색현상을 조사하기 위해 Segismundo et al. (2017)이 수행한 일련의 시험실 침투시험 결과로부터 도출되었다. 4종의 모래-저회 혼합 필터에 대한 시험결과를 데이터셋트로 가공하여 적용하였다. 시험결과로부터 침투시간에 따른 필터의 폐색도를 나타내는 폐색곡선을 구할 수 있으며 결과는 Fig. 1에 보인 바와 같다.
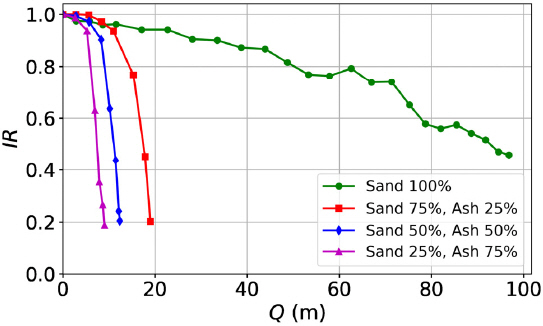
폐색곡선은 침투시간에 따라 증가하는 침투유량(Q)과 임의 시간에 토출되는 침투유량을 초기침투유량에 대해 정규화한 값인 침투율(IR)의 관계를 나타낸다. Fig. 1의 결과에서 저회 함유율이 증가할수록 침투율의 감소율이 증가함을 볼 수 있다. 이는 저회 함유율이 증가할수록 상대적으로 입경이 작은 저회 입자의 이동으로 인해 모래의 공극이 폐색될 가능성이 높아지기 때문이다.
2.2 데이터 가공
2.2.1 특성(feature)과 기준(label)
강우유출수 필터의 폐색에 영향을 미치는 침투율(IR), 침투율 증분(ΔIR), 모래함유율(PS), 저회함유율(PA)을 데이터셋트의 입력특성으로 설정했다. 기준은 침투유량(Q)으로 정해 침투 진행에 따른 Q의 증가와 폐색 진행에 따른 IR의 감소관계를 추정하는 회귀(regression) 모델을 개발하였다. 모델 훈련과 검증을 위한 데이터셋트는 이들 특성과 기준에 대한 시간 데이터인 입력값과 기준값으로 구성하였다. 2.1에서 설명한 4가지 침투조건은 모래와 저회의 함유율 PS와 PA를 적용하여 구분하였다.
2.2.2 데이터셋트 가공
모델학습을 위한 침투율(IR)은 Fig. 1에 보인 모든 침투조건에 대한 시험결과를 포함할 수 있도록 0.17~1.0 구간으로 설정했다. 이 구간에서 침투율증분(ΔIR)을 단계별로 0.0005의 크기로 증가시키면서 58단계로 나누고 각 단계에서 추출한 값을 입력 침투율(IR) 값으로 정했다. 침투율증분(ΔIR)을 단계적으로 증가시키는 경우에 IR-Q 관계곡선의 초기단계 곡선부의 변화양상을 보다 효과적으로 반영할 수 있었다. 또한 비교적 적은 훈련데이터로도 양호한 훈련결과를 얻을 수 있는 것으로 연구되었다(Shahin, 2014a).
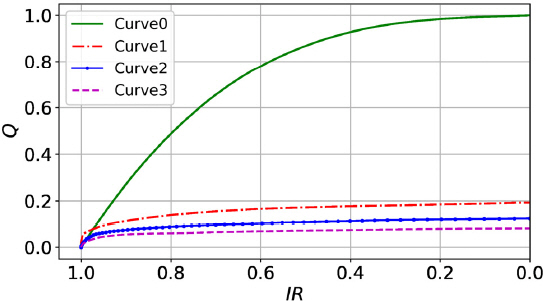
58개의 각 침투율(IR)에 대해 침투시험 결과를 기반으로 침투유량(Q)을 정해 침투율(IR)-침투유량(Q) 관계의 합성곡선을 도출했다. 4가지 침투조건에 대해 각각 Curve0, Curve1, Curve2, Curve3으로 칭한 합성곡선을 도출하였다. 각 합성곡선 데이터셋트에 적용한 입력값과 기준값의 범위는 Table 1에 정리한 바와 같다. 이들 값에서 IR, Q와 ΔIR은 시간에 따라 변화하는 현시값(current state units)을 가진다. 반면에 PS와 PA는 전 시간구간에서 일정한 고정값(plan units)을 가진다.
Table 1
Summary of Synthetic IR-Q Curves (Lee, 2021)
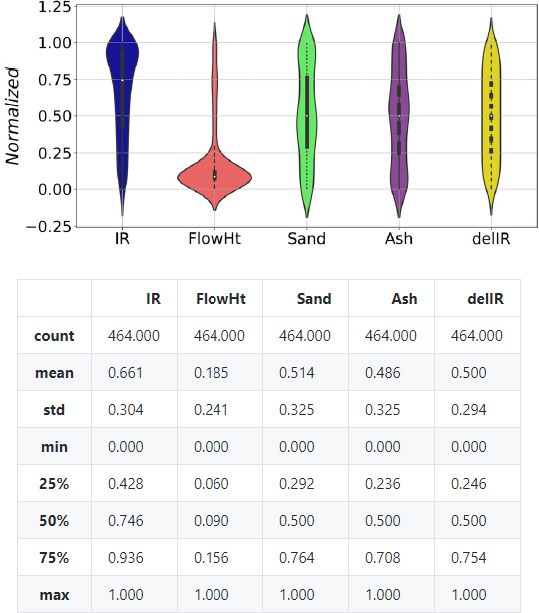
Table 1에 보인 합성곡선의 데이터셋트를 각 특성값 항목에서 최소값 0과 최대값 1을 갖도록 정규화하였다. 정규화 데이터를 사용하는 경우에 딥러닝 모델 학습 및 파라미터 결정과정에서 가중치 편향을 배제할 수 있다(Chollet, 2018). 데이터셋트를 정규화하여 분포특성을 나타내면 Fig. 2와 같다. 정규화한 데이터셋트의 분포특성 같은 그림에 보인 Panda Frame 추출 결과에서 확인할 수 있다.
3. 모 델
3.1 합성곱신경망 모델
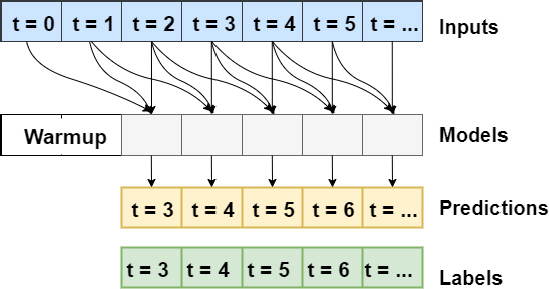
필터 폐색 현상을 딥러닝으로 모델링하기 위해 합성곱신경망(convolutional neural network, CNN)을 사용하였다. 시계열 예측을 위한 합성곱신경망은 1차원이다. 합성곱의 폭은 3을 적용하였다. 입력창의 폭도 합성곱의 폭과 동일하게 3을 적용하였다. 따라서 모델은 3시간간격의 입력창으로 입력된 3개의 단일시간간격(single-time-step) 입력값에 대해서 1개의 단일출력 (single-output)인 예측값(Q)을 추정한다. 최초 2시간간격은 warmup 데이터가 되고 전체적인 데이터 전이는 1시간간격이다. 입력창의 폭을 증가시키는 경우에 모델은 여러 시간간격에 대해 동시에 예측값을 구할 수 있다. 입력값, 모델, 예측값과 기준값 간의 데이터 흐름을 개략도로 나타내면 Fig. 4와 같다.
합성곱신경망모델은 각 1층의 입력층, 은닉층과 출력층으로 구축했다. 입력층의 노드 수는 3개이고 이는 데이터 입력창의 폭과 같다. 은닉층은 각각 32개의 셀을 가진 Conv1D층과 밀집층(dense)로 설계하였다. 출력층은 밀집층으로 예측값에 해당하는 1개의 셀을 가진다. 데이터셋트가 모델에 입력되면 은닉층과 출력층의 텐서는 노드 수로 나타낸 특성에 따라 [배치, 시간, 특성]의 차원을 갖는다. 모델 형성 및 최적화는 머신러닝, 딥러닝 프로그래밍 인터페이스 TensorFlow (Abadi et al., 2015)의 파이썬 API인 Keras (), 2015)를 이용하여 개발하였다. Keras에서 도출한 개발모델의 층 구조 및 각 층의 입출력 텐서의 차원을 Fig. 5에 보였다. 같은 그림에 모델의 각 층에 대한 매개변수의 수를 함께 나타냈다.
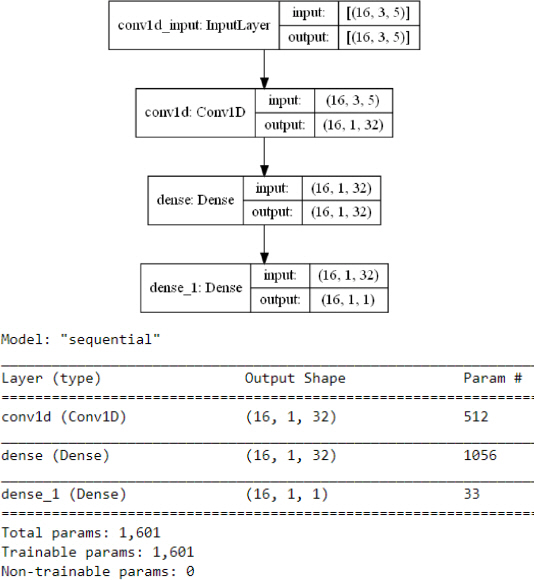
모델 구축 시에 적용한 활성화함수(activation function)는 Relu (Rectified Linear Unit)이다. 훈련 최적화는 Adam 알고리즘을 사용하였다. 손실(loss)은 Mean Absolute Error (MAE)를 적용하고, 훈련과 검증과정에서 평가할 메트릭(metric)도 Mean Absolute Error (MAE)를 선택하였다. 모델 컴파일 시 이들 각 입력항목(argument)에 대한 선택값은 기본값(Abadi et al., 2015)을 적용하였다.
3.2 데이터셋트
모델 훈련 및 검증에 사용할 Fig. 3의 합성곡선 데이터는 [시간, 특성]의 2차원 배열인 데이터프레임 형식으로 정리되었다. 모델훈련에서 데이터는 각 배치에서 시간에 대한 입력(input), 출력(label)을 포함한 특성의 관계를 나타내는 [배치, 시간, 특성]의 3차원 텐서로 변환하였다. 배치별 시간에 대한 매핑은 TensorFlow함수(Abadi et al., 2015)를 이용하였으며, 매핑한 데이터를 입력과 출력데이터로 분리하였다. Fig. 4에 보인 바와 같이 시계열에서 입력창과 출력창이 3시간간격인 슬라이딩창을 적용하여 시간전이(offset) 1시간 간격으로 매핑했다. 시계열 의존성 데이터를 다루므로 shuffle하지 않는 조건에서 batch 크기를 16으로 적용하였다. 따라서 1배치는 임의 시계열 구간에서 윈도우를 통해 순차적으로 매핑한 16 셋트의 데이터를 포함하였다.
3.3 훈련 및 검증계획
데이터셋트는 훈련셋트와 테스트셋트로 분리하여 훈련셋트로 모델을 훈련하고 훈련된 모델의 적합성을 테스트셋트로 테스트하여야 한다. Lin et al. (2018), Shahin (2014a), Shahin (2014b) 등은 말뚝지지력 신경망모델 개발에서 전체 독립적 데이터셋트 중 80~90%를 훈련셋트로 나머지는 테스트셋트로 구분하고 별도의 검증셋트를 설정하지 않았다. 하이퍼파라미터 튜닝을 하는 경우에 과적합(over fitting)이 발생할 우려가 있으므로 Chollet (2018)는 훈련셋트를 분리하여 설정한 검증셋트의 필요성을 언급하였다.
Lee (2021)는 이러한 점들을 감안한 데이터셋트 분할 방법을 제안하였다. 더불어서 모델성능 향상을 위해 시계열 데이터에 대해서 교차검증에 상응하는 단순 홀드아웃(hold-out validation)방법(Chollet, 2018)을 적용한 훈련 및 검증과정을 제안하였다. 제안된 데이터 분할과 훈련 및 검증과정을 재기술하면 다음과 같다.
Lee (2021)는 이 방법을 적용하여 Table 1에 보인 4가지 합성곡선을 Fig. 6에 보인 바와 같이 훈련 및 검증셋트와 테스트셋트로 분리하여 모델을 훈련하였다. 이 논문의 합성곱신경망모델의 개발을 위해서도 동일한 데이터셋트와 훈련 및 검증방법을 적용할 수 있었다.

4. 결과 및 분석
4.1 훈련 및 검증
3.1에서 구축한 합성곱신경망모델을 3.2의 데이터셋트에 대해 3.3에서 설명한 과정에 의거하여 훈련 및 검증하였다. 훈련 및 검증은 Fig. 6의 합성곡선 Curve1로부터 Curve0, Curve3의 순서로 수행했다. 이렇게 훈련 및 검증된 모델을 Curve2로 테스트하여 최종 적합모델로 제안하였다. 모델 개발 및 검증 과정에서 얻은 결과 및 분석에 대한 상세한 내용은 다음에 기술한 바와 같다.
Curve1, Curve0, Curve3에 대한 훈련 및 검증 과정에서 훈련 epoch에 따른 평균제곱근편차(mean squared error, MSE)로 나타낸 손실 변화와 수렴 시 IR-Q 관계곡선을 검토하였다. 이 중 대표적인 예로 Curve1에 대한 결과를 Fig. 7에 보였다.
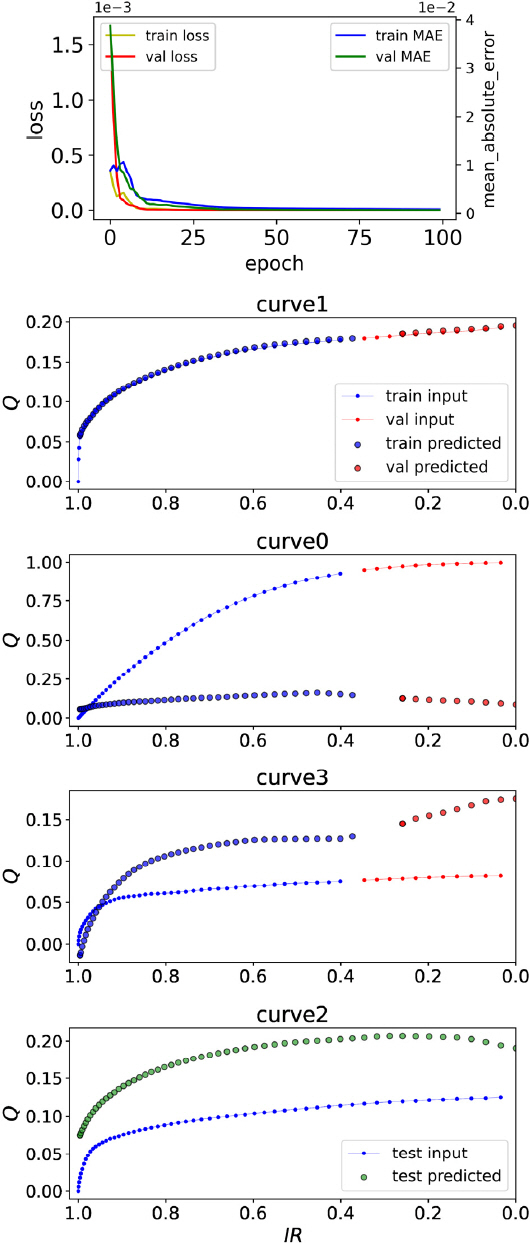
Fig. 7의 결과에서 Curve1에 대한 손실변화 곡선을 보면 약 50 epoch 이후에서 훈련 및 검증 시 손실이 충분히 수렴하였음을 알 수 있다. 또한 훈련 및 검증손실이 역전되거나 부분적 최소값을 가지는 구간이 보이지 않으므로 과대적합의 문제가 발생하지 않은 것으로 판단되었다. IR-Q 관계곡선에서는 Curve1에 대한 모델의 적합성을 볼 수 있다. 이 모델은 아직 Curve0, Curve3 및 Curve2에 대해서는 훈련되지 않았으므로 기준값을 적절히 추정하지 못한다. 이와 같은 사실은 현 훈련단계 모델을 적용하여 Curve1 이외 다른 합성곡선들의 데이터셋트에 대해서 구한 예측값과 기준값을 비교한 Fig. 7의 결과에서 확인할 수 있다. 예상한 바와 같이 Fig. 7에서 Curve1을 제외한 모든 합성곡선에 대해서 모델은 기준값을 적절히 예측하지 못했다. 같은 그림에 Curve2에 대한 테스트 결과를 함께 나타냈다.
모든 합성곡선에 대해서 적정 수준의 오차범위 내에서 기준값과 일치하는 예측값을 추정할 수 있는 모델을 적합모델로 정의하였다. 적합모델은 훈련 및 검증 데이터셋트에 대한 훈련 과정을 반복 수행하여 결정하였다. Curve1, Curve0, Curve3의 순서로 모든 데이터셋트에 대해서 손실이 수렴할 때 까지 훈련과정을 반복하여 모델을 훈련했다. 수렴 단계까지 훈련한 모델을 Curve2 데이터셋트에 대해서 테스트하여 적합한 경우에 최종 적합모델로 결정하였다. 최종 적합모델을 구하기 위해서 총 23단계의 반복 훈련단계를 거쳤다. 훈련의 적정성을 검토하기 위해 훈련과정의 각 단계에서 나타난 훈련 및 검증 손실 값의 단계별 변화를 Fig. 8에 보였다. 편의상 각 단계에서 얻은 모델을 Curve2 데이터셋트에 대해서도 테스트하고 결과를 Fig. 8에 함께 나타냈다.

Fig. 8의 결과에서 Curve0, Curve1, Curve3에 대한 손실이 초기 훈련단계에서는 단계 별로 크게 변동하였다. 이러한 결과는 각 훈련단계에서 모델이 선정한 훈련 대상 입력데이터셋트에 대해서는 잘 수렴하지만 다른 데이터셋트에 대해서는 손실이 크게 나타나기 때문으로 판단되었다.
이러한 손실 폭은 훈련과정을 경험하면서 모델이 모든 데이터셋트에 대해서 훈련되어 가는 영향을 반영하여 점차로 감소되었다. 15번째 훈련단계를 지나면서 모델은 점차적으로 모든 입력데이터셋트에 적합한 모델로 수렴하고 있는 것으로 판단할 수 있었다. Fig. 8에 함께 나타낸 Curve2에 대한 테스트 결과도 훈련단계에 따라 감소하는 경향을 보였다. 이 결과는 훈련단계에 따라 훈련된 모델의 적합성이 지속적으로 개선되고 있음을 나타내는 것으로 판단되었다.
앞서 설명한 바와 같이 Fig. 8에 보인 훈련단계는 Curve1, Curve0, Curve3 순으로 훈련하였다. 각 데이터셋트가 독립시계열 데이터이므로 데이터셋트의 훈련순서가 최종 적합모델에 미치는 영향은 없을 것으로 예상되었다. 하지만 이의 검증을 위해 Curve0으로부터 시작하여 Curve3, Curve1의 순서로 훈련 및 검증하고 Curve2로 테스트한 결과, 결정된 모델도 위의 최종 적합모델과 유사하게 수렴하는 것으로 확인하였다.
4.2 개발 모델의 적합성 검토
이와 같이 완성한 최종모델의 적합성을 평가하기 위해 모델 적용 결과를 다음의 3가지 그림으로 나타내 검토하였다. 첫째로 입력값의 순서에 따른 입력값, 기준값, 예측값의 변화를 전체 배치에 대해 나타냈다. 이로부터 모든 단계에서 입력값과 예측값의 오차를 검토하였다. 둘째로, 입력값과 예측값의 상관관계를 나타내 오차를 정량적으로 검토하였다. 마지막으로 기준값과 예측값으로 구한 IR-Q 관계곡선을 비교하였다. 이들 세 가지 그림은 검토 목적 상 다르게 표현할 뿐 근본적으로 동일한 결과이다.
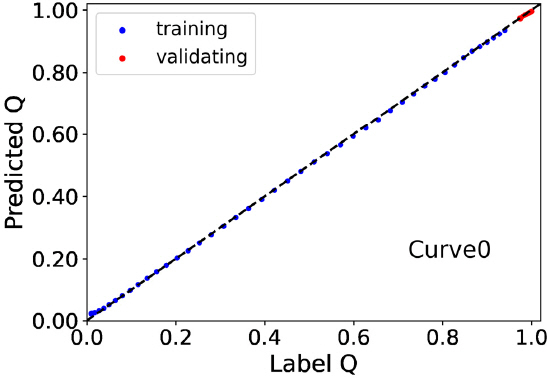
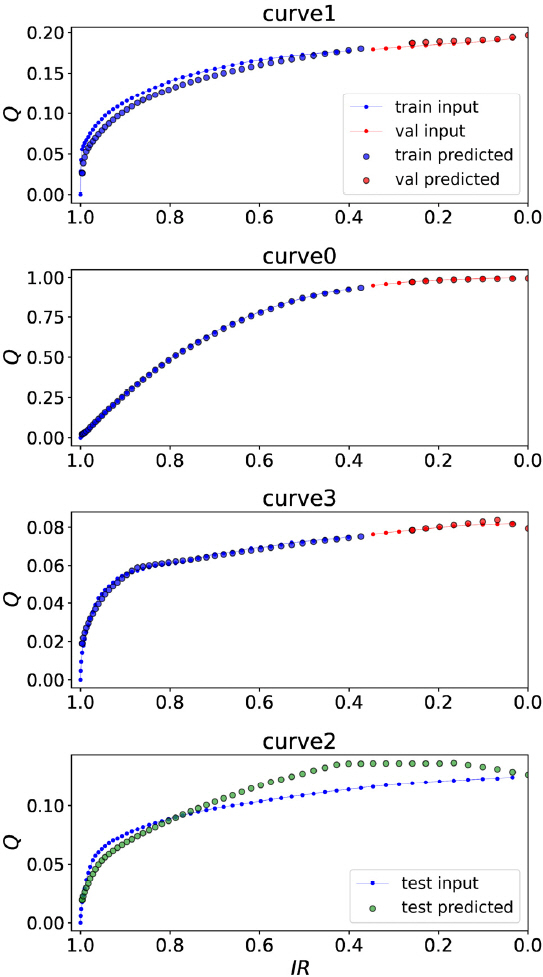
첫 번째 결과그림의 대표적인 예로서 Curve0에 대한 결과를 Fig. 9에 보였다. 그림의 결과로부터 개발모델은 배치 전 구간에 걸쳐서 기준값과 예측값의 오차가 크지 않음을 알 수 있었다. 이러한 결과는 두 번째 결과 그림인 Fig. 10에서도 반영되고 있다. Fig. 10의 결과에서 기준값과 예측값의 상관관계가 매우 높음을 알 수 있었다. 개발모델을 이용해 구한 IR-Q 관계곡선을 나타내는 세 번째 결과그림을 Fig. 11에 보였다. Fig. 11에서 볼 수 있듯이 개발모델은 모든 합성곡선에 대해서 IR-Q 관계곡선을 만족할 만한 수준의 오차범위 내에서 예측하였다. 테스트 데이터셋트인 Curve2에 대해서도 부분적인 구간의 오차를 제외하고는 대체적으로 적정한 수준의 결과를 나타냈다. 개발모델의 신뢰도를 정량적으로 평가하기 위해서 Fig. 11의 결과를 기준값과 예측값의 상관관계로 Fig. 12에 나타냈다. 그림의 결과에서 상관계수는 0.9550으로 구해져 개발모델이 기준값을 적정한 수준으로 예측하고 있음을 볼 수 있었다.


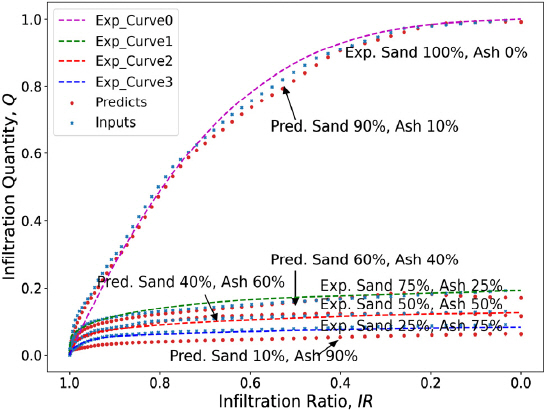
개발한 모델의 적합성, 민감도, 오차를 평가하여 모델의 일반화를 위한 검토를 수행하였다. 필터조건으로 모래와 저회의 혼합율 90:10, 60:40, 40:60, 10:90으로 변화시킨 4가지 필터를 가정하였다. 이들 필터에 대한 폐색도를 개발한 모델을 이용하여 추정해 보았다. 이들 조건에 대한 시험자료가 없으므로 입력값을 추정하여 입력해야 했다. 최초 검증단계에서는 모델의 입력값을 임의로 추정하여 결정한 값을 적용하였다. 이 입력값에 대해 모델로부터 구한 예측값으로 만든 IR-Q 관계곡선을 Fig. 3의 시험결과와 비교한 결과 모래와 저회의 혼합율이 어느 정도는 결과에 반영되고 있는 것으로 확인되었다. 하지만 결과의 신뢰도는 낮은 편으로 판단되었다. 신뢰성 있는 예측값을 얻기 위한 입력값을 결정하기 위한 방법을 검토하였다. 결과적으로 Fig. 3의 시험결과를 바탕으로 혼합율을 감안하여 실제와 유사할 것으로 추정되는 입력값을 적용할 때 가장 좋은 결과를 얻을 수 있었다. 이렇게 얻은 결과를 입력값과 예측값, 시험값과 함께 비교하여 Fig. 13에 보였다.
5. 결론 및 제언
도심강우유출수 침투시설 필터의 효율적 운영과 유지관리를 위해서는 신뢰할 만한 폐색 정보가 필요하다. 이 논문에서는 최근 적용사례가 증가하고 있는 딥러닝 알고리즘을 적용하여 폐색을 추정하기 위한 합성곱신경망 모델을 개발하였다. 개발모델의 적용성과 신뢰성을 검토한 결과 다음과 같은 결론 및 제언을 할 수 있었다.
1) 개발한 적합모델의 신뢰도를 기준값과 예측값의 상관관계로부터 평가한 결과 상관계수가 0.9550으로 구해져 신뢰성을 확인하였다.
2) 개발한 모델은 초기단계 연구로서 폐색에 영향을 미치는 특성으로 모래와 저회 혼합율만을 다루었다. 향후 연구에서 이를 확장한 여재 특성, 필터층 조합, 오염물질부하량, 오염물 종류, 침투 수리조건 등에 대한 특성분석을 수행할 필요가 있다. 특성분석 결과에 의거하여 중요한 특성들을 고려하는 모델을 개발해야 할 것이다.
3) 보다 효과적인 모델개발을 위해서는 학습 및 검증 과정에서 하이퍼파라미터 검토가 보완되어야 할 것이다. 이를 위해서는 개발기반에 대한 충분한 이해와 연습이 필요하다.
4) 모델 훈련을 위한 데이터셋트의 개수가 비교적 적은 편이다. 모델의 신뢰도 및 적합성 일반화를 위해서는 의미 있는 데이터셋트의 지속적 축적이 요구된다.
5) 이러한 문제점에도 불구하고 개발한 모델의 신뢰도와 적용범위 확대 가능성을 확인하였다. 또한 기존 이론모델과 시험폐색모델들의 보완 및 대체 기법으로 딥러닝 신경망 모델의 활용 잠재력을 확인하였다. 향후 다양한 딥러닝 알고리즘을 이용한 모델개발을 지속적으로 수행하여 모델 개발기법의 적합성을 평가해야 한다는 결론을 얻었다.




