



1. 서 론
극한강우사상의 크기와 빈도를 추정하는 것은 홍수예측 및 사회기반시설의 설계를 위해 필수적이다(Gumbel, 1958; Stedinger and Gris, 2008; Luke et al., 2017). 극한사상은 지역의 기반시설과 시민들에게 직접적인 영향을 미치며 높은 경제적 파급효과를 가진다(Fowler and Kilsby, 2000; Cheng and AghaKouchak, 2014). 하지만 관측자료가 충분하지 않은 일부 지역에서는 국지적인 극한사상을 예측하기 어려울 수 있으며, 상대적으로 관측망이 잘 갖춰진 지역일지라도 빈도해석에 기후 및 공간적인 정보를 통합하는 것은 쉬운 일이 아니다(Cooley et al., 2007).
Fisher and Tippett (1928)의 연구를 확장한 Gumbel (1941)의 초기 연구 이후, 지점빈도해석은 다양한 재현기간에 해당하는 강우량을 추정하는 데 널리 사용되어왔다(Davison and Smith, 1990; Bonnin et al., 2006; England et al., 2018). 일반적으로 지점빈도해석은 일반화된 극치 분포 또는 일반화된 로지스틱 분포와 같은 확률분포형에 극한값을 적합시키는 과정이 포함된다(Jenkinson, 1955; Hosking and Wallis, 1993). 그런 다음 적합된 분포형을 사용하여 다양한 크기의 강우량에 대한 발생 확률을 추정한다(Coles, 2001). 하지만 재현기간이 클수록 극한강우량 추정치의 불확실성이 증가하게 된다(Davison et al., 2012; Papalexiou et al., 2018).
극한강우 등의 자연재해는 물리적 과정으로 인해 발생하며 공간적 범위도 넓으므로 공간적 극한 현상에 대한 더 나은 이해와 평가가 요구된다(Davison et al., 2012). 하지만 극한 현상은 드물게 관측되므로 이에 해당하는 관측자료는 많지 않다(Hosking and Wallis, 1997).
공간적인 극한강우를 다루는 이론에는 copulas, max-stable 이론, 지수홍수법으로 대표되는 지역빈도해석, 계층적 베이지안 모형(hierarchical Bayesian model, HBM) 등이 있다(Cooley, 2009). 각 관측소의 자료를 개별적으로 모델링하는 대신에 공간이론을 적용하면서 가지게 되는 가장 중요한 장점은 유사한 관측소들의 정보를 공유하여 확률분포 매개변수 추정의 신뢰도를 향상하는 것에 있다(Casson and Coles, 1999). 지수홍수법을 이용한 지역빈도해석의 경우에는 지점별 연 최대 강수량 자료의 표준화를 통하여 균질한 지역 내의 자료풀링과정을 필수적으로 수행하고 있다(Dalrymple, 1960; Kim et al., 2008; Heo and Kim, 2019). 또한 Renard (2011)가 언급한 바와 같이 공간이론은 측정되지 않거나 불완전하게 측정된 관측소에서 확률분포 매개변수 추정이 가능하다는 장점이 있다. 그뿐만 아니라 베이지안 통계를 사용하면 극한강우를 모델링할 때 발생하는 불확실성을 적절하게 설명할 수 있다(Epstein, 1985).
본 연구에서는 HBM을 이용하여 지역의 극한강우를 설명하고자 한다. HBM은 지역의 극한강우에 영향을 미치는 지형적인 또는 기후적인 요인과 관련된 공변량 정보를 사용하여 공간에서 모형 매개변수를 추정할 수 있다(Wikle et al., 1998; Ribatet et al., 2012; Love et al., 2020). HBM을 이용한 공간적인 극한강우분석의 장점은 아래와 같이 요약될 수 있다. (1) HBM은 연구영역을 균질한 영역으로 분해할 필요가 없다(Cooley et al., 2007); (b) 불확실성 분석이 용이하다(Banerjee et al., 2014); (c) 비정상성분석을 위한 확장이 가능하다(Cheng et al., 2014; Economou et al., 2014); (d) 지역의 지형적인 특징(예: 고도, 위도, 경도 등)과 기후적인 변수(예: 평균 강수량, 지표면 기온, 이슬점 등)를 포함할 수 있다(Ahn et al., 2017). 그러나 공간 HBM을 적용할 때 적절한 공변량을 탐색하고 공변량들과 모형 매개변수들 사이의 구조를 개발하는 것이 잠재적인 어려움으로 작용한다(Najafi and Moradkhani, 2013).
HBM은 세계 여러 지역에서 극한강우를 연구하는 데 사용되어왔다. Cooley et al. (2007)은 미국 콜로라도, Gaetan and Grigoletto (2007)은 이탈리아 Triveneto, Aryal et al. (2009)은 호주 남서부, Renard (2011)는 프랑스 남부, Sun et al. (2014)은 호주 퀸즐랜드 남동부, Dyrrdal et al. (2015) 노르웨이를 대상으로 HBM을 적용한 바 있다. Ragulina and Reitan (2017)은 전 지구영역을 대상으로 적용성을 평가하였다. Armal et al. (2018)은 미국의 극한 강우사상의 연간 빈도의 추세 및 기후 변화 및 기후변동이 기여도를 살펴보기 위해 HBM을 사용한 바 있다. Bracken et al. (2018)은 여러 수문 변수의 비정상성 빈도해석을 수행하기 위한 HBM을 제안한 바 있다. Love et al. (2020)은 HBM 구조에 지리 및 기후정보가 공변량으로 사용되는 경우 극한 강우 의 공간 분석 결과가 개선된다는 것을 확인하였다. 국내에서는 Kim et al. (2014)이 표준화된 연 최대 강우량 시계열을 지형특성과 결합된 HBM에 적용하여 한강유역에서 지역빈도해석을 수행한 바 있으며, Jo et al. (2015)은 Peak-over-threshold 시계열을 이용하여 서울 지점의 비정상성 빈도해석에 HBM을 적용한 바 있다. 또한, Kim et al. (2017)은 강우 극치자료의 Scaling 특성을 고려하여 지역빈도해석을 수행하는 HBM을 제안한 바 있으며, Kim et al. (2018)은 기상변동성을 다양한 시간규모에서 고려하기 위해 HBM을 활용한 바 있다.
이러한 선행연구들을 기반으로 본 연구에서는 HBM을 이용한 지역빈도해석 모형을 개발하고 이를 한반도 동남부 부산-울산-경남지역에 적용해보고자 하였다. 제안된 모형은 다양한 공변량 관계를 수용할 수 있는 유연성을 가지고 있으므로 기후정보와 지형정보를 연계하여 공변량을 선택한 후, 상대적으로 간단한 공변량 구조를 가진 HBM을 구성하였다. 또한 제안된 방법은 연 최대 강우량 시계열에 별도의 정규화 과정을 요구하지 않는다. 이를 통하여 미계측 지역에의 추정 시 정규화 과정에 따른 불확실성을 가능한 방지하고자 하였다. 원칙적으로 제안된 방법은 균질한 영역을 별도로 정의할 필요는 없다. 하지만, 지역빈도해석을 수행하는 적용 영역이 너무 넓을 경우에는 공변량의 종류 및 구성 방법이 더 복잡하게 될 수밖에 없으므로 부산-울산-경남지역으로 적용영역을 한정시켰다.
2. 연구방법
2.1 자료
한국 기상청에서 운영 중인 종관기상관측소(Automated Synoptic Observing System, ASOS)들 중 부산-울산-경남지역의 10개 지점(울산, 부산, 통영, 진주, 거창, 합천, 밀양, 산청, 거제, 남해)의 1973년부터 2015년까지 43년 동안의 연 최대 일 강우량 자료(Annual Maximum Rainfall, AMR)가 사용되었다. Table 1에 사용된 관측소의 기본 정보를 수록하였다.
Table 1
Site Information
2.2 베이지안 계층 모형
본 연구에서는 연 최대 일 강우량 시계열의 빈도해석을 위한 확률분포형으로 일반화된 로지스틱(Generalized logistic, GLO) 분포를 적용하였다. GLO 분포의 확률밀도함수 f(x)는 아래 Eq. (1)과 같다.
여기서 α은 축척 매개변수, k은 형상 매개변수, ξ은 위치 매개변수이다. 연 최대 시계열 x의 범위는 형상 매개변수 k의 부호에 따라 결정된다. 형상 매개변수가 k<0이면 x은ξ+α/k<x<∞의 범위를 가져야 하므로, 연 최대 시계열의 최솟값이 ξ+α/k보다 커야 GLO 분포의 적용이 가능해진다. 만일 k>0이면 x은 -∞< x<ξ+ α/k의 범위를 가지게 되므로, ξ+α/k이 연 최대 시계열의 최댓값보다 훨씬 큰 값이 되어야 GLO 분포를 이용한 빈도해석이 의미를 갖게 된다.
사용된 10개 지점에서 L-모멘트법으로 매개변수를 추정하여 살펴본 결과, 추정된 형상 매개변수는 음의 값이었으며, 각 지점별 연 최대 시계열의 최솟값이 L-모멘트로 추정된 ξ+α/k보다 큰 값을 가지고 있음을 확인하였다. 또한, 적합도 검정 결과에서도 모두 GLO 분포 적용이 가능한 것으로 나타났다. 따라서 부산-울산-경남지역에 GLO 분포를 적용하는 것은 타당한 것으로 판단된다.
HBM의 첫 번째 단계에서 우도함수는 GLO 분포의 시간과 공간에 대한 곱으로 아래와 같이 표현된다.
여기서 i는 시간(year)을 의미하며, j는 공간(site)을 의미한다.
HBM의 두 번째 단계에서 GLO 분포의 매개변수는 아래와 같은 다변량 정규분포를 갖는 것으로 정의된다.
여기서 φj =ln[ αj], ψ j =ln[- kj], ζj=ln[min(xj)-αj/kj-ξj] 이다. 따라서 μφ, μψ, μζ는 1 × S의 차원인 평균 벡터가 되며, Σφ, Σψ, Σζ는 S× S 의 차원인 공분산 행렬이 된다.
GLO 분포 매개변수의 평균 벡터 μφ, μψ, μζ 는 아래와 같은 공변량의 함수로 표현된다.
여기서 a는 평균 초 매개변수(hyper-parameter)이며, cov는 공변량이다. 참고로 공변량은 연평균 강수량과 같은 기후자료 및 위도, 경도, 고도와 같은 지형자료가 이용될 수 있다.
GLO 분포 매개변수의 공분산 행렬 Σφ, Σψ, Σζ 는 아래와 같은 지수 covariogram의 형태로 표현된다.
여기서 b는 공분산 초 매개변수이며, d는 지점들 사이의 거리이다.
HBM의 세 번째 단계에서 초 매개변수 a와 b의 사전분포는 균등분포로서 정의된다. 정리하자면 본 연구에서 구성된 HBM의 평균 초 매개변수 a의 개수는 9개이며, 분산 초 매개변수 b의 개수는 6개이다.
2.3 지역 빈도해석을 위한 마코프 체인 몬테카를로 알고리즘
일반적인 베이지안 추론을 위한 마코프 체인 몬테카를로(Markov Chain Monte-Carlo, MCMC) 방법의 수치적인 구현은 메트로폴리스-해스팅스(Metropolis Hastings, MH) 알고리즘 등이 정형화되어 있으므로 어렵지 않으나, HBM의 경우에는 적절한 절차가 수치적인 구현을 위해 설정되지 않으면 사후분포를 올바르게 추출하는 것이 어려울 수있다(Berger et al., 2001). 따라서 본 연구에서는 MH 알고리즘에 기초하여 아래와 같은 절차를 수립한 후, 매개변수 및 초 매개변수의 사후분포를 추출하였다. MCMC의 초기화 과정은 다음과 같다.
① aφ,k 의 사전분포에서 a ϕ , k 1
② bφ,k의 사전분포에서 b ϕ , k 1
④ Eq. (3)으로부터 ϕ j 1
⑤ 동일한 방법으로 a ψ 1 b ψ 1 μ ψ 1 ∑ ψ 1 ψ j 1
⑥ 동일한 방법으로 a ξ 1 b ξ 1 μ ξ 1 ∑ ξ 1 ξ j 1
초기화된 MCMC를 이용한 반복 추출방법은 다음과 같으며, 우선 매개변수 φj의 갱신은 :
① 제안분포 N ( ϕ j m − 1 , v Σ ϕ m − 1 ) ϕ j ∗
② 매개변수 φj의 갱신을 위한 rφ계산
(12)
③ rφ와 0 중에서 작은 값이 0에서 1 사이에서 무작위로 추출한 균등난수에 자연로그를 취한 값보다 크면 φjm = φj*가 되며, 아니면 φjm = φjm-1이 됨.
다음 매개변수 aφ,k의 갱신의 갱신방법은 :
① 제안분포 N ( a ϕ , k m − 1 , V a ϕ , k ) μ ϕ , k ∗ μ ϕ ∗
② Eq. (6)을 이용하여 μ ϕ ∗
③ 초 매개변수 a ϕ , k ∗ r a ϕ
④ r a ϕ a ϕ , k m = a ϕ , k * μ ϕ m = μ ϕ * a ϕ , k m = a ϕ , k m − 1 μ ϕ m = μ ϕ m − 1
다음 매개변수 bφ,k의 갱신의 갱신방법은 :
① 제안분포 N ( b ϕ , k m − 1 , V b ϕ , k ) b ϕ , k ∗ V b ϕ , k
② Eq. (9)를 이용하여 ∑ ϕ ∗
③ 초 매개변수 b ϕ , k ∗ r b ϕ
④ r b ϕ b ϕ , k m = b ϕ , k * ∑ ϕ m = ∑ ϕ ∗ b ϕ , k m = b ϕ , k m − 1 ∑ ϕ m = ∑ ϕ m − 1
나머지 매개변수 ψj, aψ, k, bψ, k 및 ζj, aζ, k, bζ, k도 유사한 절차를 이용하여 갱신할 수 있다. 이때, 매개변수의 수렴(convergence)을 위해서 서로 다른 초기 값을 가진 3개의 Chain을 구성하였으며 Brooks and Gelman (1998)이 제시한 potential scale reduction factor가 1에 가까이 수렴하는 것을 확인하였다.
3. 연구결과 및 토론
3.1 공변량 선택결과
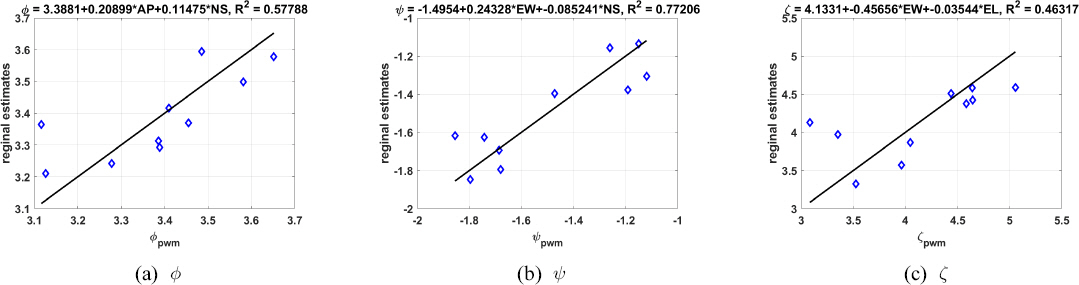
HBM을 구성하기 위해서는 Eqs. (6)~(8)에 명시된 공변량의 선택이 필요하다. GLO 분포의 매개변수의 평균 μφ, μψ, μζ을 위한 공변량을 찾기 위하여 지점별로 L-모멘트법을 이용하여 추정된 매개변수 φ ψ, ζ와 후보 공변량들 사이의 관계를 탐색하였다(Fig. 1 참조). 축척 매개변수의 경우에는 연평균 강수량과 위도를 사용하는 것이 가장 좋은 상관성이 보여주었으며, 형상 매개변수는 경도와 위도, 위치 매개변수는 경도와 고도가 가장 높은 상관성을 나타내었다. 따라서 각 매개변수별로 두 개의 공변량을 사용하여 Eqs. (9)~(11)와 같이 구성하였다. 참고로 Fig. 1에서 연평균 강수량, 위도, 경도, 고도의 값은 모두 표준화 과정을 거친 Z-score 값들(즉, Z=(X- μX )/ σX)을 적용하였다.
3.2 매개변수 사후분포 결과
Fig. 1의 정보에 기초하여 사전 설정된 초 매개변수들의 사전분포와 MCMC를 이용하여 추정된 초 매개변수들의 사후분포를 살펴보면 Fig. 2와 같다. 그림에서 빨간색 점선이 초 매개변수들의 사전분포를 의미한다. 평균 초 매개변수 a는 설정된 사전분포로부터 사후분포가 잘 수렴되었으나, 공분산 초 매개변수 b는 사전분포와 크게 다르지 않은 사후분포가 추정되었다.
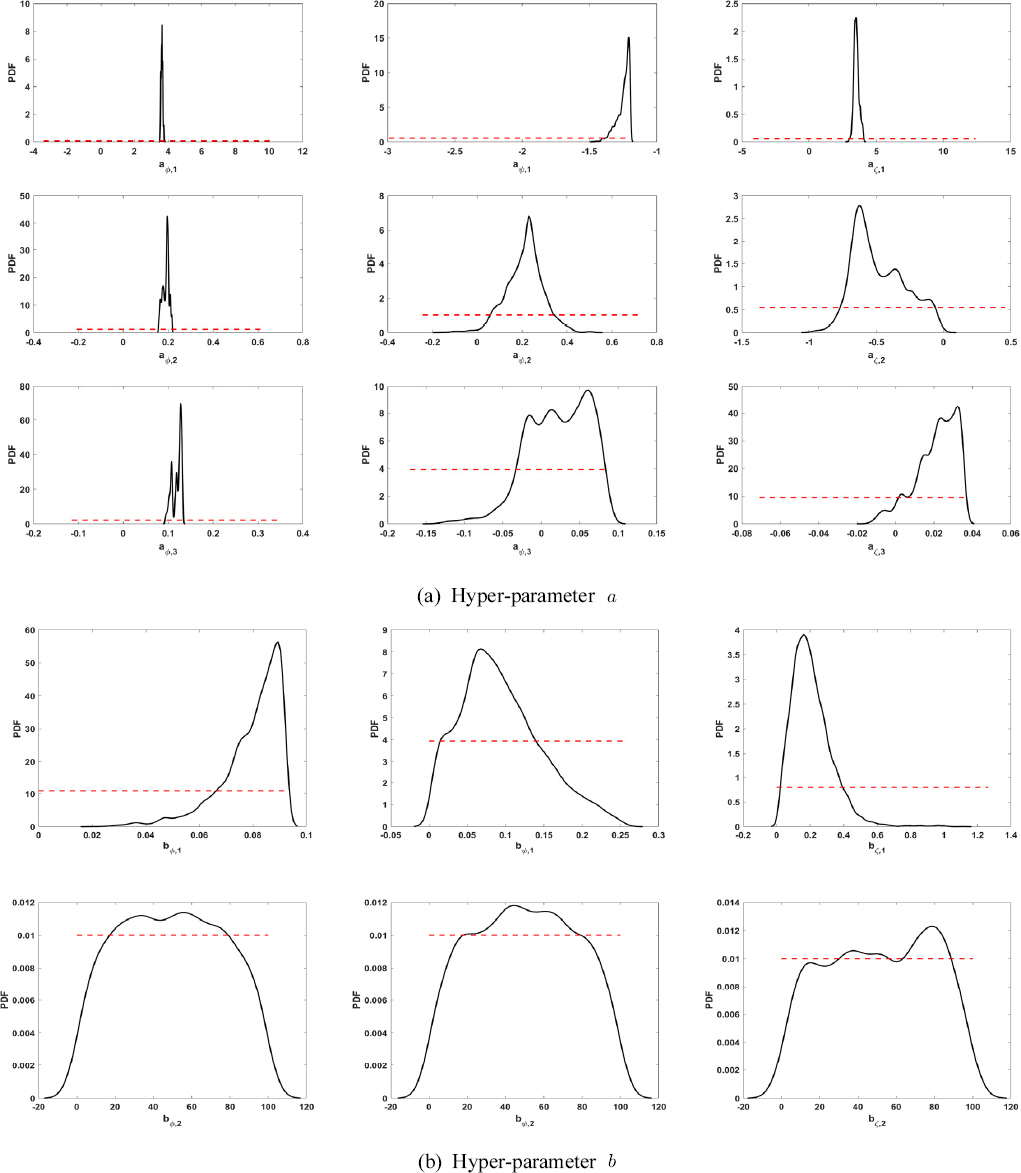
특히 공분산 초 매개변수의 감쇠 매개변수 bφ,2, bψ,2, bζ,2는 사전분포와 사후분포가 거의 같은 형태를 보여주고 있다. 감쇄 매개변수의 사전분포의 범위를 크게 넓히거나 좁혀도 유사한 결과가 획득되었다. 그러나 모형의 최종적인 결과인 극한강우량의 앙상블의 사후분포는 감쇄 매개변수의 사전분포의 범위에 그다지 민감도하게 반응하지 않는다는 것을 확인할 수 있었다. 참고로 본 연구와 동일하게 지수 variogram을 적용한 Cooley et al. (2007)의 연구의 경우에는 감쇄 매개변수의 사전분포의 범위를 0.075에서 0.6으로 매우 좁게 지정하기도 하였다. Eqs. (6)~(11)의 구조를 살펴보면, 평균 초 매개변수 a에 의해 GLO 분포 매개변수의 공간 상관성이 명시적으로 설명될 수 있으며, 공분산 초 매개변수 b는 평균 초 매개변수 a에 의해 설명되지 않는 공간 상관성을 부차적으로 설명하고 있음을 살펴볼 수 있다. Fig. 2의 결과와 감쇄 매개변수의 민감도 분석으로부터 제안된 모형 구조에서 GLO 분포 매개변수의 공간 상관성의 대부분은 평균 초 매개변수 a에 의해 설명되고 있음을 파악할 수 있다.
Fig. 3은 부산 지점만을 이용하여 MH 알고리즘으로 추출한 GLO 분포 매개변수의 사후분포(즉, 지점빈도해석의 결과)와 지역의 모든 자료를 이용하는 HBM 방법으로 추출한 부산 지점 GLO 분포 매개변수의 사후분포를 보여주고 있다. 위치 매개변수는 두 방법 모두 유사한 사후분포의 분산도를 보여주고 있지만, 축척 매개변수와 형상 매개변수의 경우에는 HBM 방법으로 추출한 사후분포의 분산도가 더 작은 것을 확인할 수 있다. 이러한 결과는 HBM 방법이 지역의 모든 이용 가능한 자료를 풀링함으로써 불확실성이 더 작은 매개변수를 추정할 수 있다는 사실을 말해주고 있다.
Fig. 3
Posterior Distribution of Parameters of GLO Distribution for At-Site and BHM-Based Regional Approaches at Busan Site

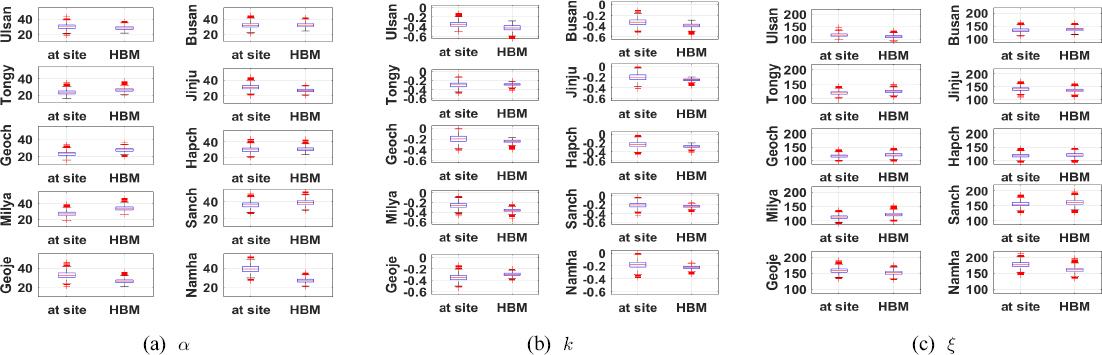
Fig. 4는 두 개 방법별로 부산-울산-경남지역의 모든 지점들에서 추출한 매개변수 앙상블의 box-plot를 보여주고 있다. 부산 지점과 유사하게 축척 매개변수와 형상 매개변수는 HBM 방법에 의한 사후분포의 분산도가 더 작게 나타나고 있음을 발견할 수 있다.
3.3 빈도해석 결과
Fig. 5는 지점빈도해석 및 지수홍수법을 이용한 지역빈도해석, 본 연구에서 제안된 HBM 방법을 이용한 지역빈도해석으로 추정한 재현기간별 확률강우량을 보여주고 있다. 지점에 따라 다소 차이가 있지만, 세 가지 방법 모두 크게 다르지 않은 확률강우량을 나타내고 있음을 살펴볼 수 있다. 전반적으로 지점빈도해석이 가장 작은 확률강우량을 나타내고 있으며, 지수홍수법이 가장 큰 확률강우량을 제시하고 있다. 지역 평균적으로 살펴볼 때, HBM과 지수홍수법에 의한 확률강우량은 서로 크고 작음이 교차하여 1% 이하의 차이를 보였으며, HBM과 지점빈도해석에 의한 확률강우량의 차이는 5% 정도인 것으로 나타났다(Fig. 5(k) 참조).
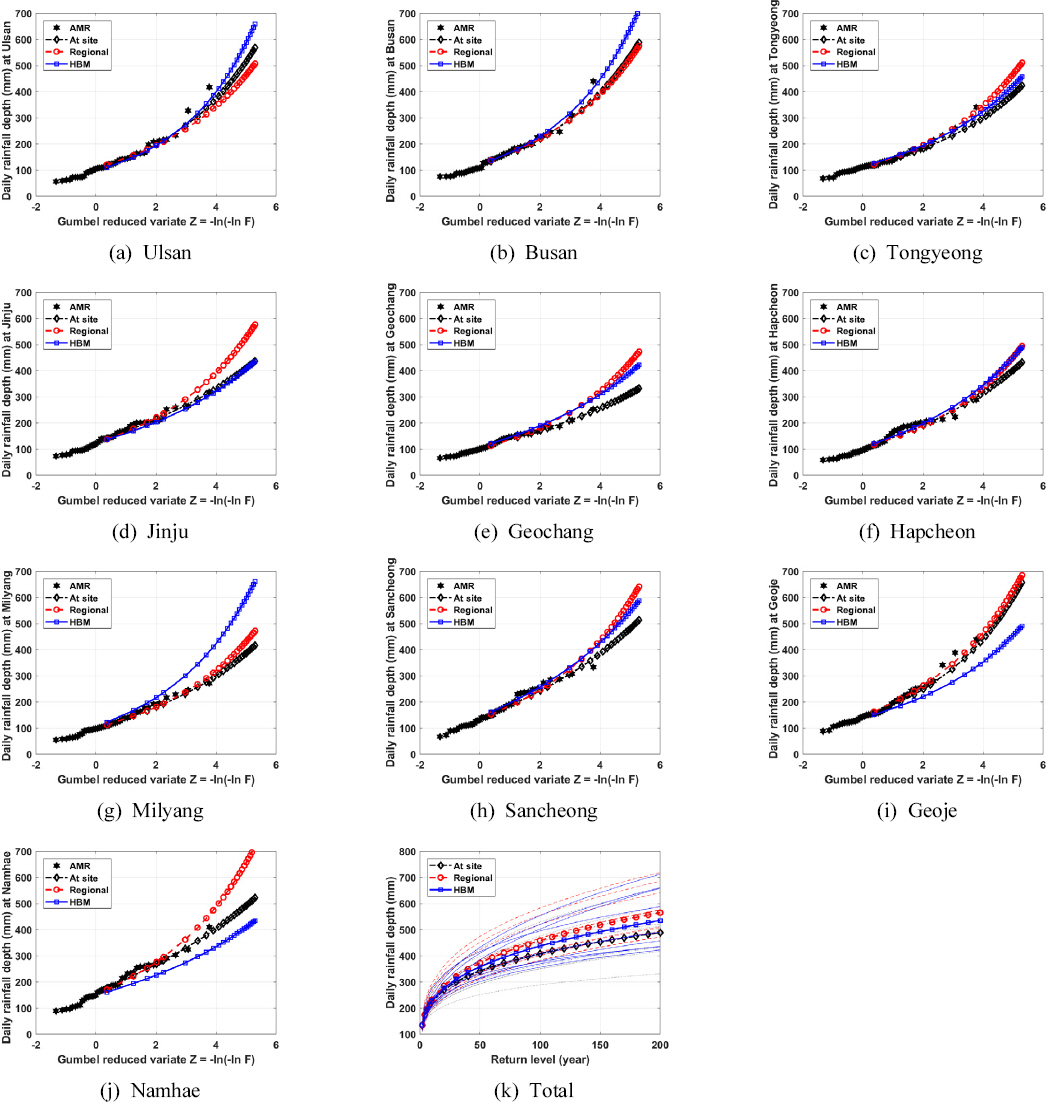
적용된 10개 지점에서 확률강우량의 공간적 변동성은 HBM 방법을 이용한 지역빈도해석이 가장 작게 나타났으며, 지점빈도해석이 가장 큰 공간적 변동성을 보였다. 전체적으로 살펴볼 때, HBM 방법에 의한 확률강우량의 크기는 지수홍수법에 의한 지역빈도해석과 비슷하였으나 공간적인 변동성은 지점빈도해석과 상대적으로 더 유사함을 발견할 수 있었다.
Fig. 6은 지점빈도해석, 지수홍수법, HBM 방법으로 각각 추정된 합천 지점의 재현기간 50년 확률강우량의 사후분포를 보여주고 있다. 합천 지점의 재현기간 50년 확률강우량의 경우, 앙상블 평균의 측면에서는 지점빈도해석과 HBM 방법이 비슷한 값을 주고 있다. 추정된 확률강우량(즉, 앙상블 평균)의 불확실성 측면에서 살펴보면, 지점빈도해석이 가장 큰 불확실성을 보이고 있으며 지수홍수법과 HBM 방법은 비슷한 불확실성을 나타내고 있음을 발견할 수 있다.

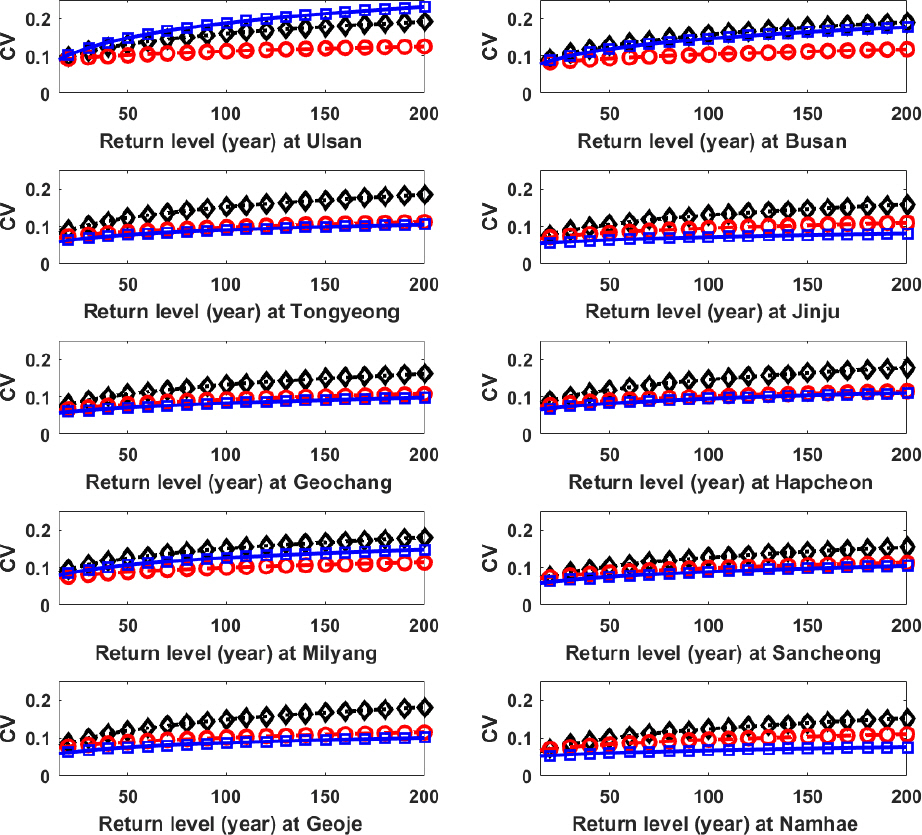
이러한 개념을 확장하여, Fig. 7에 적용된 방법별 재현기간별 확률강우량 앙상블의 변동계수를 지점별로 나타내었다. 추정된 확률강우량의 불확실성이 클수록 앙상블의 변동계수가 크다고 볼 수 있다. 세 방법 모두 재현기간이 증가할수록 변동계수가 증가하고 있음을 파악할 수 있다. 재현기간 10년 이하의 확률강우량에서는 방법별 변동계수의 차이가 크지 않았으며, 재현기간이 증가할수록 지점빈도해석으로 추정된 확률강우량 앙상블의 변동계수가 상대적으로 더 많이 증가하고 있으며, 이는 지점빈도해석의 불확실성이 가장 크다는 것을 의미한다. 지점별로 살펴보았을 경우에는 울산지점, 부산지점, 밀양지점에서는 홍수지수법의 불확실성이 가장 작았으며, 나머지 7개 지점에서는 HBM의 불확실성이 가장 작은 것으로 나타났다.
Fig. 7
Coefficient of Variation of Quantile Ensemble for Various Return Levels. Black‥◇, Red--○, and Blue--□ Lines are Derived from At-Site, IFM-Based Regional, and HBM-Based Regional Frequency Analyses, Respectively
HBM을 이용한 지역빈도해석의 장점들 중 하나는 미계측 지역에서의 확률강우량 추정이 가능하다는 것이다. 부산-울산-경남지역에 적용된 모델의 경우 연평균 강수량, 고도, 위도, 경도에 관한 정보가 주어지면 부산-울산-경남 내 임의의 지역에서 확률강우량을 추정할 수 있다. 고도, 위도, 경도의 경우 GIS 정보로부터 취득이 가능하나, 연 평균 강수량은 지점에서의 정보만 존재한다. 따라서 10개 지점의 연평균 강수량을 크리깅 방법을 이용하여 부산-울산-경남 지역의 격자별(공간 해상도 1 km × 1 km)로 분포시켜 연 평균 강수량을 계산하였다(Fig. 8(a) 참고). 이들 정보를 이용하여 추정한 부산-울산-경남지역의 재현기간 100년 확률강우량을 Fig. 8(d)에 나타내었다. 비교를 위하여 지점빈도해석과 지수홍수법으로 추정된 지점별 확률강우량의 크리깅 결과가 Figs. 8(b)와 8(c)에 도시되었다.

먼저 빈도해석방법에 따른 부산-울산-경남지역의 공간적인 분포를 살펴보면 지점빈도해석, 지수홍수법, HBM을 이용한 지역빈도해석순으로 변동성이 크며 지역적인 편차가 있지만 확률강우량 또한 높게 산정되는 것을 시각적으로 확인할 수 있다. 지점빈도해석 결과의 평균값은 405.8 ㎜, 최소 및 최대값은 각각 294.0 ㎜, 534.5 ㎜였으며, 표준편차는 42.4 ㎜로 나타났다. 지수홍수법에 의한 평균 확률강우량은 449.8 ㎜, 최소 및 최대값은 각각 366.4 ㎜, 588.2 ㎜였으며, 표준편차는 53.4 ㎜로 나타났다. 지수홍수법으로 추정된 확률강우량은 남서방향에서 최대치를 나타내며 북상할수록 낮아지는 공간적 분포를 보여주고 있다. 이는 각 지점들의 평균 연최대 강수량((Fig. 8(a) 참고)의 공간적 분포와 흡사한 형태로 지수홍수법은 평균 연최대 강수량의 수치에 많은 영향을 받는다는 것을 알 수 있다. 마지막으로 HBM을 이용한 지역빈도해석 결과의 평균값은 516.8 ㎜, 최소 및 최대값은 각각 380.9 ㎜, 752.7 ㎜였으며, 표준편차는 70.0 ㎜로 나타났다. 확률강우량은 서쪽에서 동쪽으로 갈수록 높아지는 경향을 확인할 수 있으며, 평균 확률강우량 및 최대값이 다른 빈도해석결과들보다 상대적으로 높은 수치를 나타내며 변동성도 큰 것으로 나타났다. 이는 단순히 연최대 일강우시계열만을 사용하는 것이 아니라 여러 가지 지형 및 기후정보(본 연구에서는 연평균 강수량, 고도, 위도, 경도)를 반영하였기 때문이다. 하지만 그런 점을 감안하더라도 추정된 확률강우량이 다른 빈도해석방법에 비해 높은데, 이에 대한 원인은 우리나라 강우지점들이 대부분 고도가 낮은 지역에 위치함에 따라 실제 매개변수 추정시 사용되는 DEM의 고도 범위가 다르다는 이유도 일부 존재하지만, HBM의 미계측지역의 매개변수 추정과정에서 사용되는 공변량을 이용한 회귀분석식에 내재된 불확실성이 가장 큰 것으로 판단된다. 본 연구에서는 공변량을 선택하기 위해 가장 좋은 상관성을 나타내는 기후 및 지형정보를 이용하였지만 Fig. 1(a)을 참고하면φ와ζ추정에 사용된 회귀분석식의 결정계수가 낮다는 것을 확인할 수 있다. 이러한 한계점은 추후 연구에서 다양한 공변량과 매개변수와의 상관관계를 고려하여 개선될 필요가 있다. 하지만 지점별로 크리깅 하는 경우는 특정지점을 중심으로 확률강우량이 분포되지만, HBM은 확률강우량을 격자별 정보를 바탕으로 추정하기 때문에 확률강우량의 공간적인 거동을 더 우수하게 표현할 수 있음에 따라 기존의 지수홍수법에 의한 빈도해석의 좋은 대안이 될 수 있을 것이라 기대된다.
4. 결 론
기존의 강수량 지점빈도해석 또는 지수홍수법에 의한 지역빈도해석의 한계는 공간 전반에 걸쳐 극한강우에 대한 정보를 통합하는 것이 간단하지 않다는 것이었다. 본 연구에서는 일 강수량의 연 최대 시계열의 공간분석을 위한 HBM 프레임 워크를 적용하여 공간정보 통합의 문제를 풀어보고자 하였다. 본 연구에서 적용된 공간 HBM 프레임 워크에는 사용된 공변량과 관련된 모형 불확실성에 대한 설명이 포함된다.
기존의 선행 국내연구들과 본 연구의 가장 큰 차이는 기후정보와 지형정보가 결합된 베이지안 계층 모형이 적용되었다는 것에 있다. 외국의 경우에는 기후정보와 지형정보를 결합한 사례가 있었으나, 국내의 경우에는 지형정보를 결합한 연구사례는 찾아볼 수 있으나, 기후정보를 매개변수 추정에 결합한 사례는 찾아보기 어렵다. 기후정보(본 연구에서는 연 평균 강수량)와 지형정보(본 연구에서는 고도, 위도, 경도)가 결합된 공간분석을 수행함으로써 기존의 지수홍수법에 의한 지역빈도해석보다 확률강우량의 공간적인 분포를 더 잘 설명할 수 있었다.
지수홍수법을 이용한 지역빈도해석과 비교해볼 때 HBM 방법을 이용한 지역빈도해석의 가장 큰 차이는 지점별 연 최대 강우량 시계열의 정규화가 불필요하다는 것이다. 즉, 극한강우를 공간적으로 해석하면서도 적용된 확률분포형(본 연구의 경우 GLO 분포)의 매개변수가 지점별로 추정될 수 있다. 이러한 차이로 인하여 지점에서의 자료를 최대한으로 반영하면서도 불확실성을 감소시킬 수 있었다. 제안된 방법론을 이용하여 부산-울산-경남지역에 공간적으로 분포된 확률강우량 지도를 제공할 수 있었으며, 다양한 지속기간에 대한 확률강우량 지도를 생성하는데 사용될 수 있을 것이다. 또한 큰 어려움 없이 부산-울산-경남 이외의 지역에 적용하는 것도 가능할 것이다. 더 나아가 연 평균 강수량과 같은 기후정보가 GLO 분포 매개변수 추정을 위한 공변량으로 적용될 수 있기 때문에, 공변량 기반의 미래 확률강우량 전망에도 적용될 수 있을 것으로 기대된다.
본 연구에서는 GLO 분포의 매개변수를 비교적 간단한 방식(두 개 공변량의 선형 방정식)으로 처리하여 지역빈도해석을 수행하였다. 다른 지역 또는 더 넓은 지역에 적용하려면 지역 구분에 대한 명시적인 절차가 필요할 것이며, 확률 분포를 비롯하여 공변량의 개수와 종류, 표현 방정식도 지역에 맞게 다시 구축하는 것이 바람직할 것이다. 또한, 미계측지역 결과에 대한 불확실성을 감안하여 자동기상관측장비(Automatic Weather System, AWS) 자료와의 비교도 방법론의 검증에 도움이 되리라 판단된다.




