



1. м„ң лЎ
2. м—°кө¬л°©лІ•
2.1 мһ мһ¬мҰқл°ңлҹү
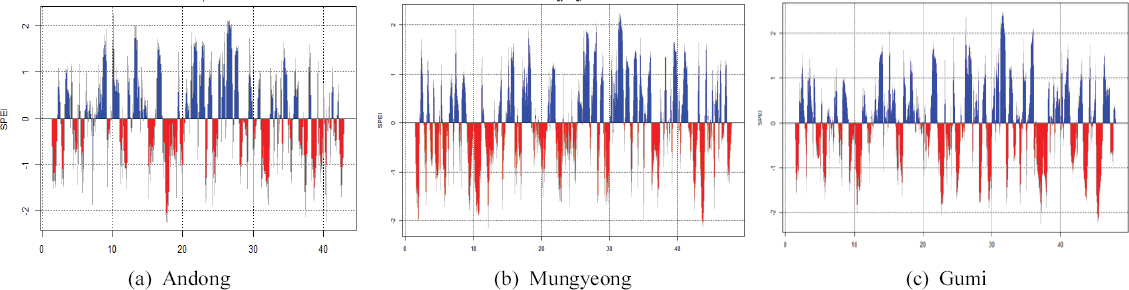
2.2 SPEI
TableВ 1
Hydrometeorological Drought Monitoring System (http://hydro.kma.go.kr)
2.3 м „мІҳлҰ¬
2.4 м •к·ңнҷ”
2.5 лӘЁлҚём„ұлҠҘнҸүк°Җ
2.5.1 MSE
2.5.2 RMSE
2.5.3 R2
3. лҢҖмғҒмң м—ӯ л°Ҹ лӘЁнҳ•м Ғмҡ©
3.1 лҢҖмғҒмң м—ӯ

3.2 мһҗлЈҢмҲҳ집
3.3 лӘЁнҳ•м Ғмҡ©
3.3.1 ANN
3.3.2 SVR
3.3.3 RF
3.3.4 мһ…л ҘліҖмҲҳ
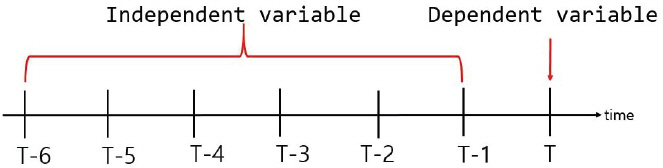
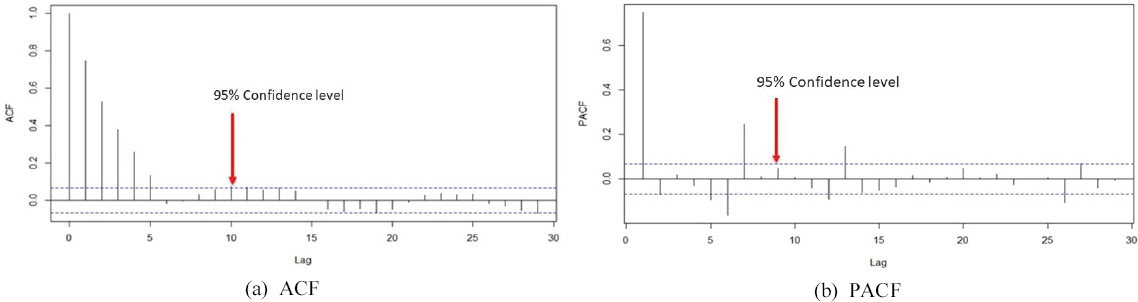
3.3.5 л§Өк°ңліҖмҲҳ кІ°м •
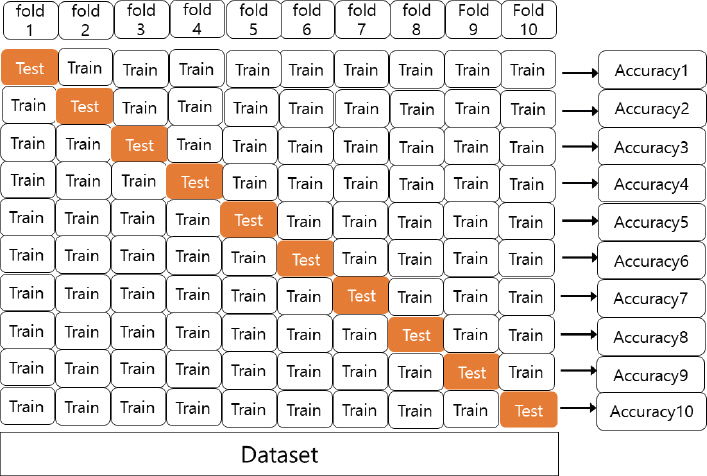
3.3.6 кё°кі„н•ҷмҠөм Ғмҡ©
TableВ 2

4. кІ° лЎ
(1) кё°мЎҙ мӣ”мһҗлЈҢ к°Җлӯ„м§ҖмҲҳлҘј мӮ¬мҡ©н•ҳм—¬ мҳҲмёЎмқ„ лҶ’мқҙлҠ” м—°кө¬к°Җ мқҙлЈЁм–ҙм§Җкі мһҲмңјлӮҳ, м„ұлҠҘнҸүк°Җм—җм„ңлҠ” м—¬м „нһҲ лӮ®мқҖ мҳҲмёЎм—җ кі м „н•ҳкі мһҲлӢӨ. көӯлӮҙм—җм„ң л°ңмғқн•ҳлҠ” к°Җлӯ„ л№ҲлҸ„мҷҖ нҢЁн„ҙмқҙ л¶Ҳк·ңм№ҷм ҒмңјлЎң ліҖн•ҳл©° м§Җм—ӯлі„ к°•мҲҳлҹүмқҳ м–‘к·№нҷ”к°Җ мӢ¬нҷ”лҗЁм—җ л”°лқј кё°мЎҙ мӣ”мһҗлЈҢлҘј мқҙмҡ©н•ҙм„ңлҠ” лҶ’мқҖ мҳҲмёЎк°’мқ„ кё°лҢҖн•ҳкё° м–ҙл өлӢӨ. л”°лқјм„ң, ліё м—°кө¬м—җм„ңлҠ” SPEI мӣ”мһҗлЈҢмҷҖ мқјмһҗлЈҢлҘј кё°кі„н•ҷмҠөм—җ м Ғмҡ©н•ҳм—¬ мқҙлҘј м„ұлҠҘнҸүк°Җ н•ҳм—¬ лӮҳнғҖлғҲлӢӨ.
(2) м „л°ҳм ҒмңјлЎң, мӣ”мһҗлЈҢ мӮ¬мҡ©н•ҳм—¬ кё°кі„н•ҷмҠөмқ„ н•ҳмҳҖмқ„ кІҪмҡ° ANNмқҙ 3к°ңм§Җм җ лӘЁл‘җ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, мқјмһҗлЈҢлҠ” кө¬лҜё ANNмқҙ, м•ҲлҸҷ, л¬ёкІҪм§Җм җмқҖ SVR мҳҲмёЎк°’мқҙ мөңмғҒмқҳ кІ°кіјлҘј м ңкіөн•ҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. мқјмһҗлЈҢ мҳҲмёЎк°’мқҙ мӣ”мһҗлЈҢ мҳҲмёЎк°’ ліҙлӢӨ лӘЁл“ м§Җм җм—җм„ң R2к°Җ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, нҷ•лҘ мҳӨм°Ё нҶөкі„мқёRMSE, MSEлҸ„ мқјмһҗлЈҢк°Җ н•ӯмғҒ лӮ®м•ҳкі , RFлҠ” лӘЁл“ м§Җм җм—җм„ң ANN, SVRліҙлӢЁ лӘЁлҚём„ұлҠҘ분м„қм—җм„ң 비көҗм Ғ лӮ®кІҢ лӮҳнғҖлӮ¬м§Җл§Ң, мӣ”мһҗлЈҢмҷҖ 비көҗмӢң лӘЁлҚём„ұлҠҘнҸүк°Җм—җм„ңлҠ” лӘЁл‘җ лҶ’мқҖ мҳҲмёЎл Ҙмқ„ лӮҳнғҖлӮ¬лӢӨ. нҠ№нһҲ, м•ҲлҸҷ, л¬ёкІҪм§Җм җмқҳ кІҪмҡ° SVRмқҙ м„ұлҠҘнҸүк°Җм—җм„ң лҶ’кІҢ лӮҳмҳЁ мқҙмң лҠ” м „нҳ•м Ғмқё л°©лІ•лЎ мқё ANNмқҙ кіјлҸ„н•ң н•ҷмҠөмңјлЎң кіјлҢҖм Ғн•©мқҳ л¬ём ңк°Җ л°ңмғқн• мҲҳ мһҲм–ҙ мқҙлҹ¬н•ң лӢЁм җмқ„ ліҙм•Ҳн•ң л°©лІ•мқё SVRмқҙ лҶ’мқҖ мҳҲмёЎмқ„ н•ң кІғмңјлЎң мӮ¬лЈҢлҗңлӢӨ.
(3) мқјл°ҳм ҒмңјлЎң кё°кі„н•ҷмҠөмқ„ н• л•Ң, мһ…л ҘмһҗлЈҢлҘј мӣҗмӢңмғҒнғңм—җм„ң мһ…л Ҙн•ҳм—¬ лҶ’мқҖ мҳҲмёЎл Ҙмқ„ кё°лҢҖн•ҳкё° м–ҙл Өмӣ мңјлӮҳ, м „мІҳлҰ¬ кіјм •м—җм„ң 분н•ҙлЎң SPEI мӢңкі„м—ҙмқ„ вҖҳмһЎмқҢ м ңкұ°вҖҷн•ҳм—¬ мӣҗлһҳмқҳ SPEI мӢңкі„м—ҙмқ„ м „мІҳлҰ¬н•ЁмңјлЎңмҚЁ ANN, SVR, RFк°Җ мһЎмқҢ м—Ҷмқҙ мЈјмҡ” мӢ нҳёлҘј лӘЁлҚёл§Ғ н• мҲҳ мһҲлҸ„лЎқ н•ЁмңјлЎңмҚЁ лӘЁлҚёмқҙ м •нҷ•н•ң кІ°кіјлҘј м ңкіөн• мҲҳ мһҲм—ҲлӢӨ.




