


1. ņä£ļĪĀ
ņĀä ņäĖĻ│äņĀüņ£╝ļĪ£ ņ×¼ļé£ņ£╝ļĪ£ ņØĖĒĢ£ ņŗ¼Ļ░üĒĢ£ Ļ▓ĮņĀ£ņĀü ņåÉņŗżĻ│╝ ņØĖļ¬ģĒö╝ĒĢ┤Ļ░Ć ļ░£ņāØĒĢśĻ│Ā ņ׳Ļ│Ā, ĻĖ░Ēøäļ│ĆĒÖöņÖĆ ĻĖēĻ▓®ĒĢ£ ļÅäņŗ£ĒÖöļĪ£ ņØĖĒĢ┤ Ēö╝ĒĢ┤ ĻĘ£ļ¬©Ļ░Ć ļŹöņÜ▒ ņ╗żņ¦ĆĻ│Ā ņ׳ļŗż. ņäĖĻ│äņØĆĒ¢ē(World Bank)ņØś ņĪ░ņé¼ņŚÉ ņØśĒĢśļ®┤ ņ¦Ćļé£ 39ļģäĻ░ä(1970Ōł╝2008ļģä) ņĀä ņäĖĻ│äņĀüņ£╝ļĪ£ ņ×ÉņŚ░ņ×¼ĒĢ┤ļĪ£ ņØĖĒĢ┤ 330ļ¦ī ļ¬ģņØś ņé¼ļ×īņØ┤ ļ¬®ņł©ņØä ņ×āĻ│Ā, Ēö╝ĒĢ┤ĻĖłņĢĪņØĆ 2ņĪ░ 3ņ▓£ņ¢Ą ļŗ¼ļ¤¼ņŚÉ ņØ┤ļź┤ļŖö Ļ▓āņ£╝ļĪ£ ļéśĒāĆļéś ņ×¼ļé£Ļ┤Ćļ”¼ ņ▓┤Ļ│äņŚÉ ļ¦ÄņØĆ ļ¼ĖņĀ£ņĀÉņØ┤ ņ׳ņØīņØ┤ ļō£ļ¤¼ļé¼ļŗż(World bank and United Nations, 2010). ņÜ░ļ”¼ļéśļØ╝ļŖö ņ×ÉņŚ░ņ×¼ļé£ņ£╝ļĪ£ ņØĖĒĢ┤ ņĄ£ĻĘ╝ 10ļģä(2006~2015)Ļ░ä ņŚ░ ĒÅēĻĘĀ ņĢĮ 5ņ▓£ 5ļ░▒ņ¢ĄņøÉņØś Ēö╝ĒĢ┤ņĢĪņØ┤ ļ░£ņāØĒĢśņśĆĻ│Ā, ĻĘĖ ņżæ 65%ļŖö ĒśĖņÜ░ļĪ£ ņØĖĒĢ£ Ēö╝ĒĢ┤ņØĖ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż(MPSS, 2016). ļ¦īņĢĮ ĻĖ░ņĪ┤ņŚÉ ļ░£ņāØĒĢ£ ņ×¼ĒĢ┤ĒåĄĻ│äņ×ÉļŻīļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ņ×¼ļé£Ēö╝ĒĢ┤ ļ░£ņāØ ņĀäņŚÉ Ēö╝ĒĢ┤ļ▓öņ£ä ļ░Å ņśüĒ¢źņØä ņśłņĖĪĒĢĀ ņłś ņ׳ļŗżļ®┤ ĒÜ©ņ£©ņĀüņØĖ ņ×¼ļé£Ļ┤Ćļ”¼ļź╝ ĒåĄĒĢ┤ Ēö╝ĒĢ┤ņĢĪņØĆ Ēü¼Ļ▓ī Ļ░ÉņåīļÉĀ Ļ▓āņØ┤ļŗż. ņØ┤ņÖĆ Ļ░ÖņØ┤ ņ×¼ļé£ņŚÉ Ļ┤ĆĒĢ£ ņĀĢļ│┤ņØś ņłśņÜöĻ░Ć ĻĖēņ”ØĒĢśĻ│Ā ņ׳ņ£╝ļéś ĻĄŁļé┤ņŚÉļŖö ņĢäņ¦ü ĒåĄĻ│äĻĖ░ļ░ś ņĀĢļ│┤ņ▓┤Ļ│äļź╝ ĒåĄĒĢ£ Ēö╝ĒĢ┤ ņśłņĖĪ Ļ┤ĆļĀ© ņŚ░ĻĄ¼Ļ░Ć ļ»Ėļ╣äĒĢ£ ņāüĒā£ņØ┤ļŗż.
ņ×¼ĒĢ┤ĒåĄĻ│äņ×ÉļŻīļź╝ ĻĖ░ļ░śņ£╝ļĪ£ Ēö╝ĒĢ┤ņĢĪņØä ņśłņĖĪĒĢśļŖö ĻĄŁņÖĖņØś ņŚ░ĻĄ¼ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ Davis and Skaggs(1992)ļŖö ļ»Ėņ£ĪĻĄ░Ļ│Ąļ│æļŗ©(U.S. Army Corps of Engineers, USACE)ņŚÉņä£ ņĪ░ņé¼ĒĢ£ ņ¦ĆņŚŁļ│ä ĒÖŹņłś Ēö╝ĒĢ┤ņĀĢļ│┤ļź╝ ņäżļ¬ģļ│ĆņłśļĪ£ ĒĢśĻ│Ā ĒÜīĻĘĆļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśņŚ¼ ņŻ╝Ļ▒░ņ¦Ć ĻĄ¼ņĪ░ļ¼╝Ļ│╝ ļé┤ņÜ®ļ¼╝ņŚÉ ļīĆĒĢ£ ņ╣©ņłśņŗ¼ļ│ä ĒÖŹņłśĒö╝ĒĢ┤ ĒĢ©ņłśļź╝ ņĀ£ņĢłĒĢśņśĆļŗż. Dorland et al.(1999)ņØĆ ļäżļŹ£ļ×Ćļō£ņŚÉņä£ 1987~1992ļģä ļÅÖņĢł ļ░£ņāØĒĢ£ ĒÅŁĒÆŹņÜ░ Ēö╝ĒĢ┤ņĢĪņØä ņóģņåŹļ│ĆņłśļĪ£ ņäĀņĀĢĒĢśĻ│Ā, ņŗ£Ļ░äļŗ╣ ņĄ£ļīĆ ĒÆŹņåŹ ļō▒ņØś ĻĖ░Ēøäļ│ĆņłśņÖĆ ņŻ╝ĒāØ ļ░Å ņé¼ņŚģņ▓┤ ņłś ļō▒Ļ│╝ Ļ░ÖņØĆ ņé¼ĒÜīŌŗģĻ▓ĮņĀ£ņĀü ļ│Ćņłśļź╝ ņäżļ¬ģļ│ĆņłśļĪ£ ņäĀņĀĢĒĢśņŚ¼ ĒÅŁĒÆŹņÜ░ Ēö╝ĒĢ┤ņĢĪ ĒÜīĻĘĆļ¬©ĒśĢņØä ņĀ£ņĢłĒĢśņśĆļŗż. ļČäņäØ Ļ▓░Ļ│╝ ņŗ£Ļ░äļŗ╣ ņĄ£ļīĆ ĒÆŹņåŹņØ┤ ĒÅŁĒÆŹņÜ░ Ēö╝ĒĢ┤ņĢĪņŚÉ Ļ░Ćņן Ēü░ ņśüĒ¢źņØä ļ»Ėņ╣śļŖö Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼Ļ│Ā, ņé¼ĒÜīŌŗģĻ▓ĮņĀ£ņĀü ļ│ĆņłśļōżņØś ņśüĒ¢źņØĆ ļ»Ėļ╣äĒĢ£ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż. Toya and Skidmore(2007)ņØś ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĒÜīĻĘĆļ¬©ĒśĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ OECDĻĄŁĻ░ĆņÖĆ Ļ░£ļ░£ļÅäņāüĻĄŁņØä ļīĆņāüņ£╝ļĪ£ ņ×ÉņŚ░ņ×¼ĒĢ┤ņŚÉ ļö░ļźĖ GDPļŗ╣ Ēö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśņśĆļŗż. ņé¼ĒÜīŌŗģĻ▓ĮņĀ£ņĀü ņÜöņØĖņØä Ļ│ĀļĀżĒĢśņŚ¼ ļČäņäØĒĢ£ Ļ▓░Ļ│╝, ĻĄÉņ£ĪņłśņżĆĻ│╝ Ļ▓ĮņĀ£ņØś ĻĘ£ļ¬©Ļ░Ć ļåÆņØĆ ĻĄŁĻ░ĆņØ╝ņłśļĪØ ņ×ÉņŚ░ņ×¼ĒĢ┤ļĪ£ ņØĖĒĢ£ Ēö╝ĒĢ┤Ļ░Ć ņĀüņØĆ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż. Mendelsohn and Saher(2011)ņØĆ ĒÜīĻĘĆļ¬©ĒśĢņØä ĒåĄĒĢ┤ ĻĄŁĻ░Ćļ│ä ņ×¼ļé£Ēö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśņśĆļŖöļŹ░, ĻĄŁņĀ£ņ×¼ļé£ņŚŁĒĢÖņŚ░ĻĄ¼ņä╝Ēä░ņŚÉņä£ ņĀ£Ļ│ĄĒĢśļŖö ņĀä ņäĖĻ│ä ņ×¼ļé£Ēö╝ĒĢ┤ ņ×ÉļŻīņÖĆ ņØĖĻĄ¼, ņåīļōØ ņ×ÉļŻī, ĻĖ░ņāü Ļ┤ĆņĖĪņ×ÉļŻī(Ļ░Ģņłśļ¤ē, ĻĖ░ņś© ļō▒)ļź╝ ņäżļ¬ģļ│ĆņłśļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. Murnane and Elsner(2012)ļŖö ļ»ĖĻĄŁņŚÉņä£ ļ░£ņāØĒĢ£ 1900ļģäļīĆļČĆĒä░ 2000ļģäļīĆĻ╣īņ¦ĆņØś ĒŚłļ”¼ņ╝ĆņØĖ Ēö╝ĒĢ┤ņÖĆ ĒÆŹņåŹ ņ×ÉļŻīļź╝ ļ░öĒāĢņ£╝ļĪ£ ļČäņ£äĒÜīĻĘĆļ¬©ĒśĢ(quantile regression model)ņØä ĒåĄĒĢ┤ ĒÆŹņåŹņŚÉ ļö░ļźĖ ĒŚłļ”¼ņ╝ĆņØĖ Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪ ĒĢ©ņłśļź╝ ņĀ£ņĢłĒĢśņśĆĻ│Ā, Zhai and Jiang(2014)ļŖö ļ»ĖĻĄŁņØś ļ│┤ĒŚśĒÜīņé¼ņØś ņ×ÉļŻīļź╝ ļ░öĒāĢņ£╝ļĪ£ 1988Ōł╝2012ļģäĻ╣īņ¦ĆņØś 73Ļ░£ ņŚ┤ļīĆņĀĆĻĖ░ņĢĢ ļ░öļ×ī ņåŹļÅäņÖĆ ĒÅŁĒÆŹ Ēü¼ĻĖ░ņŚÉ ļö░ļźĖ Ēö╝ĒĢ┤ņŚÉ ļīĆĒĢ┤ ļŗżļ│Ćļ¤ēņĄ£ņåīņĀ£Ļ│▒ĒÜīĻĘĆļČäņäØ(multi-variate least squares regression)ņØä ņĀüņÜ®ĒĢśņŚ¼ Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśļź╝ ņĀ£ņĢłĒĢśņśĆļŗż.
ĻĄŁļé┤ņØś ņŚ░ĻĄ¼ņé¼ļĪĆļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ MOLIT(2001)ņŚÉņä£ļŖö ĒÖŹņłśĒö╝ĒĢ┤ņĢĪĻ│╝ ņ╣©ņłśņŗ¼Ļ░äņØś Ļ┤ĆĻ│äļź╝ ĒÜīĻĘĆļ¬©ĒśĢņØä ĒåĄĒĢ┤ ļÅäņČ£ĒĢśņŚ¼ ņ╣©ņłśņŗ¼ļ│ä ĒÖŹņłśĒö╝ĒĢ┤ņåÉņŗżĒĢ©ņłśļź╝ ņĀ£ņĢłĒĢśņśĆĻ│Ā, Yeo(2003)ņØĆ ĒÜīĻĘĆļ¬©ĒśĢņØä ĒåĄĒĢ┤ ņ╣©ņłśļ®┤ņĀüĻ│╝ ĒÖŹņłśĒö╝ĒĢ┤ņĢĪņØś Ļ┤ĆĻ│äņŗØņØä ņĀ£ņĢłĒĢśņśĆļŗż. Chung et al.(2005)ņØĆ ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ļ¬©ĒśĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņ╣©ņłśĒö╝ĒĢ┤ ņśłņĖĪļ¬©ĒśĢņØä Ļ░£ļ░£ĒĢśņśĆļŖöļŹ░, 108Ļ░£ņØś ņżæņ£ĀņŚŁņØä ļīĆņāüņ£╝ļĪ£ ņ╣©ņłśĒö╝ĒĢ┤ļ®┤ņĀüĻ│╝ ņ£ĀņŚŁĒÖśĻ▓ĮņĀĢļ│┤ļź╝ ļ│ĆņłśļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. Jang et al.(2009)ņØĆ ļ╣äņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢņØä ĒåĄĒĢ┤ ĒÖŹņłśĒö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆĻ│Ā, ņäżļ¬ģļ│ĆņłśļĪ£ ņāüĻ┤Ćņä▒ņØ┤ ļåÆņØĆ 2Ļ░Ćņ¦ĆņØś Ļ░ĢņÜ░ņ×ÉļŻīļź╝ Ēś╝ĒĢ®ĒĢ£ ļ│ĄĒĢ®Ļ░ĢņÜ░ļź╝ ņĀ£ņĢłĒĢśņśĆļŗż. Choi(2010)ņØś ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ļ¬©ĒśĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņ×ÉņŚ░ņ×¼ļé£ Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŖöļŹ░, 5ņØ╝ ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē, ļłäņĀüĻ░ĢņÜ░ļ¤ē, ņĄ£ļīĆĒÆŹņåŹņØä ņäżļ¬ģļ│ĆņłśļĪ£ ņØ┤ņÜ®ĒĢśņśĆļŗż. Lee et al.(2016)ņØś ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņłśņøÉņŗ£, ņ¢æĒÅēĻĄ░, ņØ┤ņ▓£ņŗ£ļź╝ ļīĆņāüņ£╝ļĪ£ ļ╣äņäĀĒśĢ ĒÜīĻĘĆņŗØņØä ņØ┤ņÜ®ĒĢśņŚ¼ Ļ░ĢņÜ░ļĪ£ ņØĖĒĢ£ ĒÖŹņłśĒö╝ĒĢ┤ ņśłņĖĪĒĢ©ņłśļź╝ ņĀ£ņŗ£ĒĢśņśĆĻ│Ā, ņŗżņĀ£Ēö╝ĒĢ┤ņĢĪĻ│╝ ļ╣äĻĄÉĒĢ┤ļ│┤ļ®┤ Ļ░üĻ░üņØś Ēö╝ĒĢ┤ņĢĪņØ┤ ŌĆō14%, -15%, 37% Ļ░Ćļ¤ē Ļ│╝ņåīŌŗģĻ│╝ļīĆ ņČöņĀĢļÉśļŖö Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż.
ĻĖ░ņĪ┤ ĻĄŁļé┤ŌŗģņÖĖ ņäĀĒ¢ēņŚ░ĻĄ¼ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ņŻ╝ļĪ£ Ēā£ĒÆŹĻ│╝ ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ļ¬©ļæÉ Ļ│ĀļĀżĒĢ£ ĒÖŹņłśĒö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśĻ▒░ļéś, 1Ļ░Ćņ¦ĆņØś ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀļ¦īņØä ņĀüņÜ®ĒĢśņŚ¼ ņ×¼ļé£Ēö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśļŖö ĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś ĒśĖņÜ░Ēö╝ĒĢ┤ņÖĆ Ēā£ĒÆŹĒö╝ĒĢ┤ņØś ĒŖ╣ņä▒ņØĆ ļ¦żņÜ░ ļŗżļź┤ĻĖ░ ļĢīļ¼ĖņŚÉ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ×¼ĒĢ┤ņøÉņØĖļ│äļĪ£ ĻĄ¼ļČä ļÉśņ¢┤ ņ׳ļŖö ņ×¼ĒĢ┤ņŚ░ļ│┤ņāüņØś ĻĄ¼ļČäņŚÉ ļö░ļØ╝ ĒśĖņÜ░Ēö╝ĒĢ┤ļ¦īņØä ļīĆņāüņ£╝ļĪ£ ņŚ░ĻĄ¼ļź╝ ņ¦äĒ¢ēĒĢśņśĆļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĒåĄĻ│äņĀü ļ¬©ĒśĢņ£╝ļĪ£ ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢ, ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢ, ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢ, ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØä ņØ┤ņÜ®ĒĢśņśĆĻ│Ā, ļ│ĆņłśņäĀĒāØļ▓Ģņ£╝ļĪ£ ļŗ©Ļ│äļ│ä ļ│ĆņłśņäĀĒāØļ▓Ģ, ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ ņ┤Ø 11Ļ░£ņØś ņ×¼ļé£ĒåĄĻ│äĻĖ░ļ░ś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż.
2. ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłś Ļ░£ļ░£ņØä ņ£äĒĢ£ ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀ
ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśĻĖ░ ņ£äĒĢ┤ņä£ļŖö ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪĻ│╝ ņäżļ¬ģļ│Ćņłś ņé¼ņØ┤ņØś ĒĢ©ņłś Ļ┤ĆĻ│äļź╝ ĒīīņĢģĒĢśļŖö Ļ▓āņØ┤ ņżæņÜöĒĢśļŗż. ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪĻ│╝ ņäżļ¬ģļ│Ćņłś ņé¼ņØ┤ņØś Ļ┤ĆĻ│äļź╝ ņäĀĒśĢ ĒĢ©ņłśļĪ£ļ¦ī Ļ░ĆņĀĢĒĢśļŖö Ļ▓āņØĆ ņŗ¼Ļ░üĒĢ£ ņĀ£ņĢĮņĪ░Ļ▒┤ņØ┤ ļÉśļ»ĆļĪ£ ņŗżņĀ£ ņ×ÉļŻīļź╝ ņ£ĀņŚ░ĒĢśĻ▓ī ļŗżļŻ©ĻĖ░ ņ£äĒĢ┤ ļ╣äņäĀĒśĢ Ļ┤ĆĻ│äļź╝ ļ¬©ĒśĢĒÖö ĒĢĀ ņłś ņ׳Ļ│Ā, ļ░śņØæļ│ĆņłśņØś ĒÅēĻĘĀņłśņżĆņŚÉ ļö░ļźĖ ļČäņé░ ņłśņżĆņØś ļ│ĆĒÖö ļō▒ņØä Ļ│ĀļĀżĒĢĀ ņłś ņ׳ļŖö ņ£ĀņŚ░ĒĢ£ ļ░®ļ▓ĢņØä Ļ│ĀļĀżĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ļŗż. ņØ┤ļź╝ ņ£äĒĢ┤ ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢĻ│╝ ņØĖĻ│ĄņŗĀĻ▓Įļ¦Øļ¬©ĒśĢņØä Ļ│ĀļĀżĒĢśņśĆļŗż. ĻĘĖļ”¼Ļ│Ā ļŗżņżæĻ│ĄņäĀņä▒ņØä ĒĢ┤ņåīĒĢśĻĖ░ ņ£äĒĢ£ ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢĻ│╝ ņĄ£ĻĘ╝ ņśłņĖĪļĀź Ļ░£ņäĀņØ┤ Ēü░ ļÅäņøĆņØ┤ ļÉśļŖö Ļ▓āņ£╝ļĪ£ ņĢīļĀżņĀĖ ņ׳ļŖö ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ĒżĒĢ©ĒĢśņŚ¼ Ļ│ĀļĀżĒĢśņśĆļŗż. ņ£äņŚÉņä£ ņ¢ĖĻĖēļÉ£ ļŗżņ¢æĒĢ£ ĒåĄĻ│äņĀü ļ¬©ĒśĢĻ│╝ ļ│ĆņłśņäĀĒāØļ▓ĢņØś ņĪ░ĒĢ®ņ£╝ļĪ£ļČĆĒä░ ņŚ¼ļ¤¼ Ēøäļ│┤ ļ¬©ĒśĢņØä ņČöņĀĢĒĢ£ ļŗżņØī, ņśłņĖĪļĀź ĒÅēĻ░Ćļź╝ ĒåĄĒĢ┤ Ļ░Ćņן ņÜ░ņłśĒĢ£ ņśłņĖĪļĀźņØä Ļ░¢ļŖö ņĄ£ņóģļ¬©ĒśĢņØä ņäĀņĀĢĒĢśĻ│Āņ×É ĒĢśņśĆļŗż.
2.1 ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢ
ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢ(Linear Regression Model, LRM)ņØĆ ņóģņåŹļ│Ćņłś yņŚÉ ņ£ĀņØśĒĢ£ ņśüĒ¢źņØä ļ»Ėņ╣Ā Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉśļŖö ņäżļ¬ģļ│ĆņłśļōżņØĖ x1, ŌĆ”, xKņØä Ļ│ĀļĀżĒĢśņŚ¼, ņóģņåŹļ│ĆņłśĻ░Ć ņŚ¼ļ¤¼ Ļ░£ņØś ņäżļ¬ģļ│ĆņłśļōżļĪ£ ņäżļ¬ģļÉśļŖö Eq. (1)Ļ│╝ Ļ░ÖņØĆ ĻĄ¼ņĪ░ļź╝ Ļ░¢ļŖöļŗż(Chatterjee and Hadi, 2012).
(1)
Eq. (1)ņŚÉņä£ņØś ņĢäļל ņ▓©ņ×É iļŖöiļ▓łņ¦Ė ļŹ░ņØ┤Ēä░ņØś Ļ░ÆņØä ņØśļ»ĖĒĢśļ®░, ļŹ░ņØ┤Ēä░ņØś ņ┤Ø Ļ░£ņłśļŖö nĻ░£ļź╝ Ļ░ĆņĀĢĒĢ£ļŗż. Eq. (1)ņŚÉņä£╬▓0ļŖö ņĀłĒÄĖ(intercept)ņØ┤ļ®░, ņäżļ¬ģļ│Ćņłś ņĢ×ņŚÉ ļČÖņØĆ╬▓1, ŌĆ”, ╬▓KļŖö ĒÜīĻĘĆĻ│äņłś(regression coefficient)ļź╝ ļéśĒāĆļéĖļŗż. ╬ÆjļŖö jļ▓łņ¦Ė ņäżļ¬ģļ│Ćņłś xjļź╝ ņĀ£ņÖĖĒĢ£ ļéśļ©Ėņ¦Ć ņäżļ¬ģļ│ĆņłśļōżņØś ĒÜ©Ļ│╝Ļ░Ć ĒåĄņĀ£ļÉśĻ│Ā ņ׳ļŖö ņāüĒÖ®ņŚÉņä£xjņØś Ļ░ÆņØ┤ ĒĢ£ ļŗ©ņ£ä ņ”ØĻ░ĆĒĢĀ ļĢī, yņØś ĻĖ░ļīōĻ░ÆņØĖ╬╝(=E(y))ņØś ļ│ĆĒÖöļ¤ēņØä ņØśļ»ĖĒĢ£ļŗż. ╬ĄļŖö ņśżņ░©(error)ļĪ£ņŹ©, ņóģņåŹļ│Ćņłś yĻ░Ć ņäżļ¬ģļ│Ćņłśx1, ŌĆ”, xKņŚÉ ņØśĒĢ┤ ņäżļ¬ģļÉśņ¦Ć ņĢŖļŖö ļéśļ©Ėņ¦Ć ļČĆļČäņØä ļéśĒāĆļéĖļŗż. ĒÜīĻĘĆļ¬©ĒśĢņŚÉņä£ ņśżņ░©ĒĢŁņØĆ ņä£ļĪ£ ĒåĄĻ│äņĀüņ£╝ļĪ£ ļÅģļ”ĮņØ┤ļ®░, ĒÅēĻĘĀņØ┤ 0ņØ┤Ļ│Ā ļÅÖņØ╝ĒĢ£ ļČäņé░ņØä Ļ░Ćņ¦ĆļŖö ņĀĢĻĘ£ļČäĒż(normal distribution)ļź╝ ļö░ļźĖļŗżĻ│Ā Ļ░ĆņĀĢĒĢ£ļŗż.
2.2 ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢ
ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢ(Generalized Linear Model, GLM)ņØĆ ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢņŚÉņä£ ņóģņåŹļ│ĆņłśņŚÉ ļīĆĒĢ£ ļČäĒż Ļ░ĆņĀĢņØä ļŗżņ¢æĒÖö ĒĢĀ ņłś ņ׳ļŖö ļ¬©ĒśĢņØ┤ļŗż(Nelder and Wedderburn, 1972). ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņØĆ Eq. (2)ņÖĆ Ļ░ÖņØ┤ Ēæ£ĒśäļÉ£ļŗż.
Eq. (2)ņŚÉņä£╬╝ļŖö ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀņØĖ E(y)ņØä ņØśļ»ĖĒĢśļ®░, g(┬Ę)ļŖö ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀĻ│╝ ņäżļ¬ģļ│ĆņłśņØś ņäĀĒśĢĻ▓░ĒĢ®ņØä ņŚ░Ļ▓░ĒĢśļŖö ņŚŁĒĢĀņØä ņłśĒ¢ēĒĢśļŖö ņŚ░Ļ▓░ĒĢ©ņłś(link function)ņØ┤ļŗż. Eqs. (3-5)ļŖö ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ļÉ£ ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņØś ļČäĒż Ļ░ĆņĀĢņØä Ēæ£ĒśäĒĢ£ Ļ▓āņØ┤ļŗż.
Eq. (3)ļŖö ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀĻ│╝ ļČäņé░ņØ┤ ņä£ļĪ£ ļŗżļźĖ ļ│ĆņłśļØ╝Ļ│Ā Ļ░ĆņĀĢĒĢ£ Ļ▓āņØ┤ļŗż. Eq. (4)ļŖö ņóģņåŹļ│ĆņłśņØś ļČäņé░ņØ┤ ņé░Ēżļ¬©ņłś(dispersion parameter)ņØĖŽåņŚÉ ņØśĒĢ┤ ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀņØś 1ņ░©ĒĢ©ņłśļĪ£ Ēæ£ĒśäļÉ£ļŗżĻ│Ā Ļ░ĆņĀĢĒĢśĻ│Ā, ļĪ£ĻĘĖ ņŚ░Ļ▓░ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. Eq. (5)ļŖö ņóģņåŹļ│ĆņłśņØś ļČäņé░ņØ┤ ņé░Ēżļ¬©ņłś kņŚÉ ņØśĒĢ┤ ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀņØś 2ņ░©ĒĢ©ņłśļĪ£ Ēæ£ĒśäļÉ£ļŗżĻ│Ā Ļ░ĆņĀĢĒĢśĻ│Ā, ļĪ£ĻĘĖ ņŚ░Ļ▓░ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢ£ļŗż.
2.3 ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢ
ņŻ╝ņä▒ļČä ļČäņäØņØĆ ņ░©ņøÉņČĢņåī(dimension reduction) ĻĖ░ļ▓Ģ ņżæ ĒĢśļéśļĪ£ņŹ©, ņäżļ¬ģļ│ĆņłśļōżņØś Ļ│ĄļČäņé░Ē¢ēļĀ¼ ļśÉļŖö ņāüĻ┤ĆĒ¢ēļĀ¼ņØä Ļ│Āņ£Āņ╣ś-Ļ│Āņ£Āļ▓ĪĒä░ ļČäĒĢ┤(eigen valueŌĆōeigen vector decomposition)ĒĢśņŚ¼ ņäżļ¬ģļ│ĆņłśļōżņØś ņäĀĒśĢĻ▓░ĒĢ®ņ£╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ĆļŖö ņä£ļĪ£ ņāüĻ┤ĆļÉśņ¢┤ņ׳ņ¦Ć ņĢŖņØĆ ļ│Ćņłśļź╝ ņ░ŠņĢäļéĖļŗż(Hotelling, 1933). ņØ┤ ļ│Ćņłśļź╝ ņŻ╝ņä▒ļČäņØ┤ļØ╝Ļ│Ā ĒĢśļŖöļŹ░, ņŻ╝ņä▒ļČäļōżņØĆ ņäżļ¬ģļ│ĆņłśļōżņØś ļ│ĆļÅÖ(variation)ņØä ņĄ£ļīĆĒĢ£ ņäżļ¬ģĒĢĀ ņłś ņ׳ļÅäļĪØ ļ¦īļōżņ¢┤ņ¦ĆĻ▓ī ļÉśļ»ĆļĪ£ ņĀĢļ│┤ņØś ņåÉņŗżņØ┤ ņĄ£ņåīĒÖöļÉ£ļŗż. ļŗżņżæĻ│ĄņäĀņä▒ņØä Ēö╝ĒĢśļ®┤ņä£, ļåÆņØĆ ņāüĻ┤ĆĻ┤ĆĻ│äļź╝ Ļ░¢ļŖö ļŗżņłśņØś ņäżļ¬ģļ│Ćņłśļōż ļīĆņŗĀņŚÉ ņåīņłśņØś ņŻ╝ņä▒ļČäņØä ņäżļ¬ģļ│ĆņłśļĪ£ ļīĆņŗĀ ņé¼ņÜ®ĒĢśļŖö ĒÜīĻĘĆļ¬©ĒśĢņØä ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢ(Principle Component Regression model, PCR)ļØ╝Ļ│Ā ĒĢ£ļŗż. ņäżļ¬ģļ│Ćņłśx1, ŌĆ”, xKļĪ£ļČĆĒä░ mĻ░£ņØś ņŻ╝ņä▒ļČäņĀÉņłśz1, ŌĆ”, zm(m Ōē” k)ļź╝ ĻĄ¼ņä▒ĒĢśņśĆļŗżĻ│Ā ĒĢĀ ļĢī, ņĀüĒĢ®ļÉśļŖö ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢņØĆ Eq. (6)Ļ│╝ Ļ░Öļŗż.
2.4 ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ļ¬©ĒśĢ
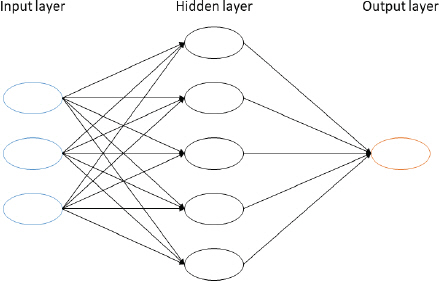
ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø(Artificial Neural Network, ANN)ņØĆ ņāØņ▓┤ ņŗĀĻ▓Įļ¦ØņØś ĒŖ╣ņ¦ĢņØä ļŗ©ņł£ĒÖö ĒĢ£ Ļ▓āņ£╝ļĪ£ ņØĖĻ░äņØ┤ Ļ│╝Ļ▒░ņØś Ļ▓ĮĒŚśĻ│╝ ĒøłļĀ©ņØä ĒåĄĒĢ┤ ņ¦ĆņŗØņØä ņČĢņĀüĒĢśņŚ¼ ļŗżļźĖ ņāüĒÖ®ņŚÉ ņĀüņÜ®ĒĢśļō»ņØ┤ Ļ│╝Ļ▒░ņ×ÉļŻīņØś ņ×ģŌŗģņČ£ļĀźĒī©Ēä┤ ņĀĢļ│┤ļź╝ ņČöņČ£ĒĢśņŚ¼ ņĀĆņןĒĢśĻ│Ā, ņĀĆņןļÉ£ ņĀĢļ│┤ļź╝ ĻĖ░ņ┤łļĪ£ ņŗ£ņŖżĒģ£ņØś ņ×ģŌŗģņČ£ļĀź Ļ┤ĆĻ│äļź╝ ļ░śļ│ĄņĀüņØĖ ĒøłļĀ©(training)ņØä ĒåĄĒĢ┤ Ļ░Ćņżæņ╣ś(weight)ļź╝ ņĄ£ņĀüĒÖöĒĢ©ņ£╝ļĪ£ņä£ ņāłļĪ£ņÜ┤ ļŹ░ņØ┤Ēä░ņŚÉ ļ»ĖļלņāüĒÖ®ņŚÉ ļīĆĒĢ£ ņĀĢļ│┤ļź╝ ņĀ£ņŗ£ĒĢśļÅäļĪØ ĒĢśļŖö ļ░®ļ▓ĢņØ┤ļŗż(Kim, 2013). ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ĻĄ¼ņĪ░ļŖö Fig. 1Ļ│╝ Ļ░ÖņØ┤ ņÖĖļČĆ ņ×ģļĀźņØä ļ░øņĢäļōżņØ┤ļŖö ņ×ģļĀźņĖĄ(input layer), ņ×ģļĀźņĖĄĻ│╝ ņČ£ļĀźņĖĄ ņé¼ņØ┤ņŚÉ ņ£äņ╣śĒĢśņŚ¼ ņÖĖļČĆļĪ£ ļéśĒāĆļéśņ¦Ć ņĢŖļŖö ņØĆļŗēņĖĄ(hidden layer), ņ▓śļ”¼ļÉ£ Ļ▓░Ļ│╝Ļ░Ć ņČ£ļĀźļÉśļŖö ņČ£ļĀźņĖĄ(output layer)ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦äļŗż. ņ▓śļ”¼ņÜöņåīļŖö ņŚ¼ļ¤¼ ļŗżļźĖ ņ▓śļ”¼ ņÜöņåīļōżļĪ£ļČĆĒä░ ņ×ģļĀźņØä ļ░øņĢäļōżņŚ¼ ņŚ░Ļ▓░Ļ░Ćņżæņ╣ś(connection weight)ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņł£ ņ×ģļĀźĻ░ÆņØä Ļ│äņé░ĒĢ£ Ēøä ĒÖ£ņä▒ĒÖö ĒĢ©ņłś(activation function)ļź╝ ĒåĄĒĢ┤ ņČ£ļĀźĻ░ÆņØä Ļ▓░ņĀĢĒĢśĻ▓ī ļÉ£ļŗż(Oh et al., 2008). ņŗĀĻ▓Įļ¦ØņØś ņ¦ĆļÅäĒĢÖņŖĄ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ļŖö ņŚŁņĀäĒīī ņĢīĻ│Āļ”¼ņ”śĻ│╝ Fletcher- Reeves ņĢīĻ│Āļ”¼ņ”ś, BFGS ņĢīĻ│Āļ”¼ņ”śņØ┤ ņ׳ļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņŗżņĖĪĻ░ÆĻ│╝ Ļ▓░Ļ│╝Ļ░ÆņØś ņ░©ņØ┤ļź╝ ņŚŁņ£╝ļĪ£ ņ¦äĒ¢ēņŗ£Ēéżļ®┤ņä£ ņśżņ░©Ļ░Ć ņĄ£ņåīĻ░Ć ļÉśļÅäļĪØ ņĖĄĻ│╝ ņĖĄ ņé¼ņØ┤ņØś ņŚ░Ļ▓░Ļ░ĢļÅäļź╝ ĻĄ¼ĒĢśļŖö ņŚŁņĀäĒīī ņĢīĻ│Āļ”¼ņ”śņØä ņØ┤ņÜ®ĒĢśņŚ¼ ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśņśĆļŗż.
2.5 ņĀäĒåĄņĀü ļ│ĆņłśņäĀĒāØļ▓Ģ
ļ│ĆņłśņäĀĒāØņØĆ ņäżļ¬ģļ│Ćņłś ņżæ ņóģņåŹļ│ĆņłśņÖĆ ņ£ĀņØśĒĢ£ ņŚ░Ļ┤Ćņä▒ņØä Ļ░¢ļŖö ņäżļ¬ģļ│Ćņłśļ¦īņØä ņäĀĒāØĒĢśņŚ¼ ņé¼ņÜ®ĒĢśļŖö ļ░®ļ▓ĢņØ┤ļŗż. ņĀäĒåĄņĀüņØĖ ļ│ĆņłśņäĀĒāØ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ļŖö ņĀäņ¦äņäĀĒāØļ▓Ģ(forward selection), Ēøäņ¦äņåīĻ▒░ļ▓Ģ(backward elimination), ļŗ©Ļ│äļ│äņäĀĒāØļ▓Ģ(stepwise selection) ļō▒ņØ┤ ņ׳ņ£╝ļ®░, ļŗ©Ļ│äļ│äņäĀĒāØļ▓ĢņØĆ ļŗżļźĖ ļÅģļ”Įļ│ĆņłśĻ░Ć ĒÜīĻĘĆņŗØņŚÉ ņĪ┤ņ×¼ĒĢĀ ļĢī ņóģņåŹļ│ĆņłśņŚÉ ņśüĒ¢źļĀźņØ┤ ņ׳ļŖö ļ│Ćņłśļōżļ¦īņØä ĒÜīĻĘĆņŗØņŚÉ ĒżĒĢ©ņŗ£ĒéżĻĖ░ ļĢīļ¼ĖņŚÉ ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśļŖöļŹ░ ĒÜ©Ļ│╝ņĀüņØ┤ņ¢┤ņä£ ļ¦ÄņØ┤ ņō░ņØ┤Ļ│Ā ņ׳ļŗż.
2.6 ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓Ģ
ņĀäĒåĄņĀü ļ│ĆņłśņäĀĒāØļ▓ĢņØĆ ņäżļ¬ģļ│ĆņłśņØś Ļ░£ņłśĻ░Ć ļ¦ÄņØä Ļ▓ĮņÜ░ Ļ│äņé░ņŗ£Ļ░äņØ┤ ņśżļל Ļ▒Ėļ”░ļŗżļŖö ļŗ©ņĀÉņØ┤ ņ׳ļŗż. ņØ┤ļ¤¼ĒĢ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ ļ░®ļ▓Ģņ£╝ļĪ£ ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØ┤ ņĀ£ņĢłļÉśņŚłļŗż. ĒÜīĻĘĆļ¬©ĒśĢņØś Ļ▓ĮņÜ░ļź╝ ņśłļĪ£ ļōżņ¢┤ ņäżļ¬ģĒĢśļ®┤, ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØĆ Eq. (7)ņØä ņĄ£ņåīĒÖöĒĢśļŖö ĒÜīĻĘĆĻ│äņłśņØś ņČöņĀĢļ¤ēņØä ņ░ŠļŖöļŗż.
Eq. (7)ņŚÉņä£ ņ▓½ ļ▓łņ¦Ė ĒĢŁņØĆ ņ×öņ░©ņĀ£Ļ│▒ĒĢ®ņ£╝ļĪ£ ņ×ÉļŻīņŚÉ ļīĆĒĢ£ ļ¬©ĒśĢņØś ņĀüĒĢ®ļÉ£ ņĀĢļÅäļź╝ ņØśļ»ĖĒĢśļ®░, ļæÉ ļ▓łņ¦Ė ĒĢŁņØĆ Ēü░ ĒÜīĻĘĆĻ│äņłś Ļ░ÆņŚÉ ļ▓īņĀÉņØä ņŻ╝Ļ│Ā ņ׳ļŗż. ╬╗ļŖö ņ×öņ░©ņĀ£Ļ│▒ĒĢ®Ļ│╝ ļ▓īņĀÉ Ļ░äņØś ņāüļīĆņĀü ļ╣äņżæņØä ņĪ░ņĀĢĒĢśļŖö ņĪ░ņ£© ļ¬©ņłś(tuning paramter)ņØ┤ļŗż. ļ│┤ĒåĄ╬╗ļŖö ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ļź╝ 10-ļČäĒĢĀ ĻĄÉņ░© Ļ▓Ćņ”Ø(10-fold cross-validation)ĒĢśņŚ¼ ņ¢╗ņ¢┤ņ¦ĆļŖö ņśłņĖĪņśżņ░©ņØś ĒÅēĻĘĀņØä ņĄ£ņåīĒÖöĒĢśļŖö ĻĖ░ņżĆņ£╝ļĪ£ Ļ│äņé░ļÉśļ®░, ņØ┤ļĀćĻ▓ī ņ¢╗ņ¢┤ņ¦ä╬╗ĒĢśņŚÉņä£ Eq. (7)ļź╝ ĒÆĆņ¢┤ ĒÜīĻĘĆĻ│äņłś ļōżņØä ņČöņĀĢĒĢ£ļŗż.
Eq. (7)ņŚÉņä£ q = 2ņØĖ Ļ▓ĮņÜ░ņØś ĒÜīĻĘĆĻ│äņłś ņČöņĀĢņ╣śļź╝ ĻĄ¼ĒĢśļŖö ļ¼ĖņĀ£ļź╝ ļŖźĒśĢĒÜīĻĘĆ(ridge regression)ņØ┤ļØ╝Ļ│Ā ĒĢśļŖöļŹ░, ņäżļ¬ģļ│Ćņłś ņé¼ņØ┤ņØś Ļ░ĢĒĢ£ ņāüĻ┤ĆĻ┤ĆĻ│äļĪ£ ņØĖĒĢ£ ļŗżņżæĻ│ĄņäĀņä▒ņØś ļ¼ĖņĀ£ļź╝ ĻĘ╣ļ│ĄĒĢśĻĖ░ ņ£äĒĢ┤ Hoerl and Kennard(1970)ņŚÉ ņØśĒĢ┤ Ļ│ĀņĢłļÉśņŚłļŗż. ĒĢśņ¦Ćļ¦ī ņØ┤ ļ░®ļ▓ĢņØĆ ļ¬©ļōĀ ņäżļ¬ģļ│ĆņłśļōżņØ┤ ļ¬©ĒśĢņŚÉ ĒżĒĢ©ļÉśļ»ĆļĪ£ ļ│ĆņłśņäĀĒāØ Ļ┤ĆņĀÉņŚÉņä£ļŖö ņĀüņĀłĒĢśņ¦Ć ņĢŖļŗż.
ļ░śļ®┤ q = 1ņØĖ Ļ▓ĮņÜ░ņØś ĒÜīĻĘĆĻ│äņłś ņČöņĀĢņ╣śļź╝ ĻĄ¼ĒĢśļŖö ļ░®ļ▓ĢņØ┤ Tibshirani(1996)ņŚÉ ņØśĒĢ┤ ņĀ£ņĢłļÉśņŚłņ£╝ļ®░ ņØ┤ļź╝ lasso (least absolute shrinkage and selection operator)ļØ╝Ļ│Ā ĒĢ£ļŗż. ņØ┤Ēøä ridgeņÖĆ lassoņØś ņĀłņČ®ņØĖ elastic netņØ┤ Zou and Hastie(2005)ņŚÉ ņØśĒĢ┤ ņĀ£ņĢłļÉśņŚłĻ│Ā, Eq. (8)Ļ│╝ Ļ░Öļŗż.
(8)
Eq. (8)ņŚÉņä£╬▒ ŌłŖ [0, 1]ņØś Ļ░ÆņØä Ļ░¢ļŖöļŗż. elastic netņØĆ ņāüĻ┤ĆĻ┤ĆĻ│äĻ░Ć ļåÆņØĆ ņäżļ¬ģļ│Ćņłśļōż ņżæņŚÉņä£ ĒĢśļéśņØś ļ│Ćņłśļ¦īņØä ĒØöĒ׳ ņäĀĒāØĒĢśļŖö lassoņØś ļŗ©ņĀÉņØä ļ│┤ņÖäĒĢśĻĖ░ ņ£äĒĢśņŚ¼ ņĀ£ņĢłļÉśņŚłļŗż. Eq. (8)ņŚÉņä£╬▒= 1ņØ┤ļ®┤ ridge, ╬▒ = 0ņØ┤ļ®┤ lassoņØś ļ¼ĖņĀ£ļź╝ ĒæĖļŖö Ļ▓āņØ┤ ļÉ£ļŗż.
ņĀäņłĀĒĢ£ lasso ļśÉļŖö elastic netņØś Ļ▓ĮņÜ░, ņØ╝ļČĆ ņäżļ¬ģļ│ĆņłśņŚÉ ļīĆĒĢ£ ĒÜīĻĘĆĻ│äņłś ņČöņĀĢņ╣śĻ░Ć ņĀĢĒÖĢĒ׳ 0ņØ┤ ļÉśņ¢┤ ļ│ĆņłśņäĀĒāØĻ│╝ ļÅÖņØ╝ĒĢ£ ĒÜ©Ļ│╝ļź╝ Ļ░Ćņ¦äļŗż. ņ”ē, ņäżļ¬ģļ│ĆņłśņŚÉ ļīĆĒĢ£ ĒÜīĻĘĆĻ│äņłś ņČöņĀĢ ļ░Å ļ│ĆņłśņäĀĒāØņØä ļÅÖņŗ£ņŚÉ ĒĢśļŖö ņØ┤ņĀÉņØ┤ ņ׳ņ£╝ļ®░ Ļ│äņé░ņŗ£Ļ░ä ļśÉĒĢ£ ņĀäĒåĄņĀüņØĖ ļ│ĆņłśņäĀĒāØļ▓Ģļ│┤ļŗż ļŹö ļ╣Āļź┤ļŗżļŖö ņĀÉ ļĢīļ¼ĖņŚÉ ļŗżņ¢æĒĢ£ ņØæņÜ® ļČäņĢ╝ņŚÉņä£ļÅä Ļ░üĻ┤æņØä ļ░øĻ▓ī ļÉśņŚłļŗż.
2.7 ņśłņĖĪļĀź ĒÅēĻ░Ć
ņĀäņ▓┤ ļŹ░ņØ┤Ēä░ņģŗņØä ļÅģļ”ĮņØ┤ļØ╝Ļ│Ā Ļ░ĆņĀĢĒĢśĻ│Ā ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ņÖĆ ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ļź╝ ļéśļłł ļŗżņØī, ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ļ¦īņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņśłņĖĪĒĢ©ņłśļź╝ ĻĄ¼ņä▒ĒĢśņśĆļŗż. ņØ┤Ēøä ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ņŚÉņä£ ļ¦īļōżņ¢┤ņ¦ä ņśłņĖĪĒĢ©ņłśļź╝ ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņģŗņŚÉ ņĀüņÜ®ĒĢśņŚ¼, ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņģŗņØś ņŗżņĀ£Ļ░ÆĻ│╝ ņśłņĖĪĻ░ÆņØä ļ╣äĻĄÉĒĢśņśĆļŗż. ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņŚÉņä£ņØś ņśłņĖĪļĀźņØ┤ ņÜ░ņłśĒĢĀņłśļĪØ ļ»Ėļל ļŹ░ņØ┤Ēä░ņŚÉ ļīĆĒĢ£ ņśłņĖĪļĀźņØ┤ ņÜ░ņłśĒĢ£ ļ¬©ĒśĢņØä ĻĖ░ļīĆĒĢĀ ņłś ņ׳ņ£╝ļ»ĆļĪ£ ļÅÖņØ╝ĒĢ£ ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ņŚÉņä£ ņŚ¼ļ¤¼ Ļ░Ćņ¦Ć ĒåĄĻ│äņĀü ļ░®ļ▓Ģņ£╝ļĪ£ ļ¬©ĒśĢņØä ļ¦īļōĀ ļŗżņØī, ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņŚÉņä£ Ļ░Ćņן ņśłņĖĪļĀźņØ┤ ņÜ░ņłśĒĢ£ ļ¬©ĒśĢņØä ņĄ£ņóģ ļ¬©ĒśĢņØä ņäĀņĀĢĒĢśļŖö Ļ▓āņØ┤ ļ░öļ×īņ¦üĒĢśļŗżĻ│Ā ĒīÉļŗ©ĒĢśņśĆļŗż. ņśłņĖĪļĀź ĒÅēĻ░ĆĻ│╝ņĀĢņØä ņÜöņĢĮĒĢśļ®┤ ļŗżņØīĻ│╝ Ļ░Öļŗż.
ŌæĀ 1994~2011ļģä ļŹ░ņØ┤Ēä░ņģŗņØä ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ļĪ£, 2012~2015ļģä ļŹ░ņØ┤Ēä░ņģŗņØä ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ļĪ£ ņ¦ĆņĀĢ
ŌæĪ ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ņģŗņ£╝ļĪ£ ņśłņĖĪĒĢ©ņłś ņČöņĀĢ Ēøä, ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņģŗņŚÉ ņĀüņÜ®
Ōæó ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņģŗņŚÉņä£ņØś ņśłņĖĪĻ░ÆĻ│╝ ņŗżņĀ£Ļ░Æ ļ╣äĻĄÉ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņśłņĖĪļĀź ĒÅēĻ░ĆņØś ņ¦ĆĒæ£ļĪ£ RMSE(root mean squared error)ļź╝ Ēæ£ņżĆĒÖöĒĢ£ NRMSE(normalized root mean squared error)ļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. NRMSEļŖö ļ¬©ĒśĢņØś ņśłņĖĪļĀźņØä ĒÅēĻ░ĆĒĢĀ ļĢī ņŻ╝ļĪ£ ņé¼ņÜ®ļÉ£ļŗż(Kim et al., 2012; Hwang, 2014; Cho et al., 2016). NRMSEļŖö ļČäņ×ÉņØĖ RMSEļź╝ ļČäļ¬©ņØĖ ņóģņåŹļ│ĆņłśņØś ļ▓öņ£äļĪ£ Ēæ£ņżĆĒÖöĒĢ£ Ļ░Æņ£╝ļĪ£ 0ņŚÉ Ļ░ĆĻ╣īņÜĖņłśļĪØ ņóģņåŹļ│ĆņłśņØś ļ▓öņ£ä ļīĆļ╣äĒĢ£ ņśżņ░©ņØś ņĀĢļÅäĻ░Ć ņ×æņØīņØä ņØśļ»ĖĒĢ£ļŗż. ņØ┤ļŖö ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņŚÉņä£ņØś ņŗżņĀ£Ļ░Æ Ļ│╝ ņśłņĖĪĻ░Æ ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Eq. (9)ņÖĆ Ļ░ÖņØ┤ Ļ│äņé░ļÉ£ļŗż.
Eq. (9)ņØś nņØĆ ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņØś Ļ░£ņłśņØ┤ļ®░, ļČäļ¬©ļŖö ņóģņåŹļ│ĆņłśņØś ĒÅēĻĘĀĻ│╝ Ļ░ÖņØĆ ļŗżļźĖ Ļ░Æņ£╝ļĪ£ ļīĆņ▓┤ļÉĀ ņłś ņ׳ļŗż.
3. ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłś Ļ░£ļ░£
3.1 ļīĆņāü ņ¦ĆņŚŁ ņäĀņĀĢ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĻĄŁļ»╝ņĢłņĀäņ▓ś(ĻĄ¼ ņåīļ░®ļ░®ņ×¼ņ▓Ł)ņŚÉņä£ ļ░£Ļ░äĒĢ£ ņ×¼ĒĢ┤ņŚ░ļ│┤ļź╝ ĒåĄĒĢ┤ 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņ×ÉļŻīļź╝ ĻČīņŚŁļ│äļĪ£ ĻĄ¼ļČäĒĢśņŚ¼ Table 1ņŚÉ ļéśĒāĆļāłļŗż. ļČäņäØ Ļ▓░Ļ│╝ ĒĢ£Ļ░ĢĻČīņŚŁņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪņØ┤ Ļ░Ćņן Ēü¼Ļ│Ā, ļ░£ņāØĒܤņłśļÅä Ļ░Ćņן ļ¦ÄņØĆ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż. ļö░ļØ╝ņä£ Fig. 2ņÖĆ Ļ░ÖņØ┤ ņ┤Ø 5Ļ░£ņØś ņŗ£ļÅä(ņä£ņÜĖņŗ£, ņØĖņ▓£ņŗ£, Ļ▓ĮĻĖ░ļÅä, Ļ░ĢņøÉļÅä, ņČ®ļČü ņØ╝ļČĆ)ļĪ£ ņØ┤ļżäņ¦ä ĒĢ£Ļ░ĢĻČīņŚŁņØä ļīĆņāü ņ¦ĆņŚŁņ£╝ļĪ£ ņäĀņĀĢĒĢśņśĆļŗż.
3.2 ņóģņåŹļ│Ćņłś ņé░ņĀĢ
ĒĢ£Ļ░Ģ ĻČīņŚŁņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖö ĒśĖņÜ░Ēö╝ĒĢ┤ ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśĻĖ░ ņ£äĒĢ┤ ņóģņåŹļ│ĆņłśļĪ£ ņ×¼ĒĢ┤ņŚ░ļ│┤ņØś 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņ×ÉļŻīļź╝ ĒÖ£ņÜ®ĒĢśņśĆļŗż. Ļ│╝Ļ▒░ņØś ĒÖöĒÅÉĻ░Ćņ╣śņÖĆ Ēśäņ×¼ņØś ĒÖöĒÅÉĻ░Ćņ╣śĻ░Ć ļŗżļź┤ĻĖ░ ļĢīļ¼ĖņŚÉ 22ļģäĻ░äņØś ĒÖöĒÅÉĻ░Ćņ╣śļź╝ ĒÖśņé░ĒĢ┤ņĢ╝ ĒĢśļŖöļŹ░, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ×¼ĒĢ┤ņŚ░ļ│┤ņŚÉņä£ ņé¼ņÜ®ĒĢ£ ļ░®ļ▓ĢĻ│╝ ļÅÖņØ╝ĒĢśĻ▓ī ņāØņé░ņ×É ļ¼╝Ļ░Ćņ¦Ćņłśļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ 2015ļģä ĻĖ░ņżĆņ£╝ļĪ£ ĒśäĻ░ĆĒÖö ĒĢśņśĆļŗż. ņ×¼ĒĢ┤ņŚ░ļ│┤ņŚÉļŖö ņ×¼ĒĢ┤ļ░£ņāØĻĖ░Ļ░äļ│äļĪ£ ņŗ£ĻĄ░ĻĄ¼ļ│ä ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪņØ┤ ņłśņ¦æļÉśĻĖ░ ļĢīļ¼ĖņŚÉ ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśņŚÉņä£ ņóģņåŹļ│ĆņłśļŖö ņ┤Ø 1,352Ļ▒┤ņØś ņ×¼ĒĢ┤ļ░£ņāØĻĖ░Ļ░äļ│ä ņŗ£ĻĄ░ĻĄ¼ ļŗ©ņ£äņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪņ£╝ļĪ£ ņé░ņĀĢĒĢśņśĆļŗż.
3.3 ņäżļ¬ģļ│Ćņłś ņé░ņĀĢ
ņäĀĒ¢ē ņŚ░ĻĄ¼ļōżņØä ņ░ĖĻ│ĀĒĢśņŚ¼ ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśļź╝ ĻĄ¼ņä▒ĒĢśļŖö ņäżļ¬ģļ│ĆņłśļĪ£ ņ┤Ø Ļ░ĢņÜ░ļ¤ē(Total rainfall), ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē(Antecedent rainfall), ņ¦ĆņåŹņŗ£Ļ░äļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ē(Maximum rainfall by duration), ņ¦ĆņŚŁ ļ®┤ņĀü(Area), ņ×¼ĒĢ┤ĻĖ░Ļ░ä(Number of date)ņØä Ļ│ĀļĀżĒĢśņśĆļŗż.
ņ┤Ø Ļ░ĢņÜ░ļ¤ē, ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē, ņ¦ĆņåŹņŗ£Ļ░äļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ēĻ│╝ Ļ░ÖņØĆ ņłśļ¼ĖĻĖ░ņāüņ×ÉļŻīļź╝ Ļ│ĀļĀżĒĢśĻĖ░ ņ£äĒĢ┤ 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ĻĖ░ņāüņ▓Ł ņŗ£Ļ░ĢņÜ░ ņ×ÉļŻīļź╝ ĻĖ░ņ┤ł ņ×ÉļŻīļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. ĻĖ░ņāüņ▓ŁņØĆ ņ¦Ćņāü ļČĆĻĘ╝ņØś ļīĆĻĖ░ņāüĒā£ļź╝ ņŗżņŗ£Ļ░äņ£╝ļĪ£ Ļ┤ĆņĖĪĒĢśĻĖ░ ņ£äĒĢ£ ĻĖ░ļ│Ė ņןļ╣äņØĖ ņóģĻ┤ĆĻĖ░ņāüĻ┤ĆņĖĪņןļ╣ä(Automated Synoptic Observing System, ASOS)ņÖĆ ļ¼┤ņØĖņ£╝ļĪ£ ņÜ┤ņśüļÉśļŖö ņ×ÉļÅÖĻĖ░ņāüĻ┤ĆņĖĪņןļ╣ä(Automatic Weather System, AWS)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņ¦ĆņāüĻĖ░ņāüĻ┤ĆņĖĪņŚģļ¼┤ļź╝ ņłśĒ¢ēĒĢśĻ│Ā ņ׳ļŖöļŹ░, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļ╣äĻĄÉņĀü Ļ┤ĆņĖĪ ņ×ÉļŻīņØś Ļ▓Ćņ”Ø ļ░Å Ļ┤Ćļ”¼Ļ░Ć ĻŠĖņżĆĒ׳ ņØ┤ļŻ©ņ¢┤ņ¦ĆĻ│Ā ņ׳ļŖö ņóģĻ┤ĆĻĖ░ņāüĻ┤ĆņĖĪņןļ╣äņØś ņŗ£Ļ░ĢņÜ░ ņ×ÉļŻīļź╝ ĒÖ£ņÜ®ĒĢśņśĆļŗż. ĒĢ£Ļ░Ģ ĻČīņŚŁņŚÉ ĒĢ┤ļŗ╣ļÉśļŖö ņóģĻ┤ĆĻĖ░ņāüĻ┤ĆņĖĪņןļ╣ä Ļ┤ĆņĖĪņåīņØś ņŗ£Ļ░ĢņÜ░ņ×ÉļŻīļź╝ Thiessen ļ®┤ņĀüļ▓ĢņØä ĒÖ£ņÜ®ĒĢśņŚ¼ Ē¢ēņĀĢĻĄ¼ņŚŁ ļŗ©ņ£äļ│ä ļ®┤ņĀü Ļ░ĢņÜ░ļ¤ēņ£╝ļĪ£ ņé░ņĀĢĒĢśņśĆĻ│Ā, ņØ┤ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪņŚÉ ņśüĒ¢źņØä ļ»Ėņ╣Ā Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉśļŖö ņ┤Ø Ļ░ĢņÜ░ļ¤ē, ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē, ņ¦ĆņåŹņŗ£Ļ░äļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ēņØä ņé░ņĀĢĒĢśņśĆļŗż. ņ┤Ø Ļ░ĢņÜ░ļ¤ēņØĆ ņ×¼ĒĢ┤ĻĖ░Ļ░äļÅÖņĢłņØś ļłäņĀüļÉ£ ņ┤Ø Ļ░ĢņÜ░ļ¤ēņØä ļéśĒāĆļé┤Ļ│Ā, ņäĀĒ¢ē Ļ░ĢņÜ░ļ¤ēņØĆ ņ×¼ĒĢ┤ ņŗ£ņ×æ 1ņØ╝, 2ņØ╝, ŌĆ”, 7ņØ╝ņĀäņØś ļłäņĀü ņäĀĒ¢ē Ļ░ĢņÜ░ļ¤ēņØä ņØśļ»ĖĒĢ£ļŗż. ņ¦ĆņåŹņŗ£Ļ░ä ļ│ä ņĄ£ļīĆ Ļ░ĢņÜ░ļ¤ēņØĆ ņ×¼ĒĢ┤ĻĖ░Ļ░ä ļÅÖņĢłņØś ņ¦ĆņåŹņŗ£Ļ░ä 1ņŗ£Ļ░ä, 2ņŗ£Ļ░ä, ŌĆ”, 24ņŗ£Ļ░ä ļłäņĀü Ļ░ĢņÜ░ļ¤ēņØś ņĄ£ļīōĻ░ÆņØä ļéśĒāĆļéĖļŗż. ņ¦ĆņŚŁ ļ®┤ņĀüņØĆ ĒśĖņÜ░Ēö╝ĒĢ┤ ņ¦ĆņŚŁ(ņŗ£ĻĄ░ĻĄ¼ ļŗ©ņ£ä)ņØś ļ®┤ņĀüņØä ļéśĒāĆļé┤ļ®░, ņ×¼ĒĢ┤ĻĖ░Ļ░äļŖö ņ┤Ø ņ×¼ĒĢ┤ĻĖ░Ļ░äņØä ļéśĒāĆļéĖļŗż. Table 2ļŖö ņäżļ¬ģļ│ĆņłśņÖĆ ļ│ĆņłśņØś ļŗ©ņ£äļź╝ ļéśĒāĆļéĖ Ļ▓āņØ┤ļŗż.
3.4 ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀņØä ņĀüņÜ®ĒĢ£ ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłś Ļ░£ļ░£
ĒåĄĻ│äņĀü ļ¬©ĒśĢņ£╝ļĪ£ ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢ, ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢ, ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢ, ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØä ņØ┤ņÜ®ĒĢśņśĆĻ│Ā, ļ│ĆņłśņäĀĒāØļ▓Ģņ£╝ļĪ£ ļŗ©Ļ│äļ│ä ļ│ĆņłśņäĀĒāØļ▓Ģ, ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ ņ┤Ø 11Ļ░£ņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż. Table 3ņØĆ ņśłņĖĪĒĢ©ņłśņØś ļ¬©ĒśĢĻ│╝ ļ│ĆņłśņäĀĒāØļ▓ĢņØä ņĀĢļ”¼ĒĢ£ Ļ▓āņØ┤ļŗż.
Table┬Ā3
Heavy Rainfall Damage Prediction Function
Table 3ņŚÉņä£ ņśłņĖĪĒĢ©ņłś ŌæĀ, ŌæĪļŖö ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢņØś Ļ▓░Ļ│╝ņØ┤ļŗż. ņśłņĖĪĒĢ©ņłś ŌæĀņŚÉņä£ļŖö ļ¬©ļōĀ ņäżļ¬ģļ│Ćņłś(ņ┤Ø Ļ░ĢņÜ░ļ¤ē, ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē, ņ¦ĆņåŹņŗ£Ļ░äļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ē, ņ¦ĆņŚŁ ļ®┤ņĀü, ņ×¼ĒĢ┤ĻĖ░Ļ░ä)ļź╝ ņäżļ¬ģļ│ĆņłśļĪ£ Ļ│ĀļĀżĒĢśņśĆļŗż. ņśłņĖĪĒĢ©ņłś ŌæĪļŖö ņśłņĖĪĒĢ©ņłś ŌæĀņŚÉņä£ ņé¼ņÜ®ļÉ£ ņäżļ¬ģļ│ĆņłśļōżņŚÉ ļīĆĒĢ┤ ļŗ©Ļ│äņĀü ņäĀĒāØļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ ņäĀĒāØļÉ£ ļ│Ćņłśļōżļ¦ī ņé¼ņÜ®ĒĢśņśĆļŗż.
ņśłņĖĪĒĢ©ņłś Ōæó, ŌæŻ, ŌæżļŖö ļ¬©ļōĀ ņäżļ¬ģļ│Ćņłśļź╝ ņé¼ņÜ®ĒĢśņŚ¼ Ļ░üĻ░ü Eqs. (3-5)ņØś ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņŚÉ lassoļź╝ ĒåĄĒĢ┤ ļ│ĆņłśņäĀĒāØņØä ĒĢ£ ļ¬©ĒśĢņØ┤ļŗż. ņśłņĖĪĒĢ©ņłś Ōæź, Ōæ”, Ōæ¦ņØĆ ļ¬©ļōĀ ņäżļ¬ģļ│Ćņłśļź╝ ņé¼ņÜ®ĒĢśņŚ¼ Ļ░üĻ░ü Eqs. (3-5)ņØś ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņŚÉ elastic netņØä ĒåĄĒĢ┤ ļ│ĆņłśņäĀĒāØņØä ĒĢ£ ļ¬©ĒśĢņØ┤ļŗż.
ņśłņĖĪĒĢ©ņłś Ōæ©ļŖö ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ēņØä ļéśĒāĆļé┤ļŖö ņäżļ¬ģļ│ĆņłśļōżļĪ£ļČĆĒä░ Ļ│äņé░ļÉ£ 2Ļ░£ņØś ņŻ╝ņä▒ļČäĻ│╝ ņ¦ĆņåŹņŗ£Ļ░ä ļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ēņ£╝ļĪ£ļČĆĒä░ Ļ│äņé░ļÉ£ 2Ļ░£ņØś ņŻ╝ņä▒ļČäņØ┤ Ļ░ü ņäżļ¬ģļ│Ćņłś ņ¦æĒĢ®ņØś ļ│ĆļÅÖņØä Ļ░üĻ░ü 83%, 97% ņĀĢļÅä ņäżļ¬ģĒĢśņśĆļŗż. ļö░ļØ╝ņä£ ņØ┤ļĀćĻ▓ī Ļ│äņé░ļÉ£ ņ┤Ø 4Ļ░£ņØś ņŻ╝ņä▒ļČäĻ│╝ ļéśļ©Ėņ¦Ć ņäżļ¬ģļ│ĆņłśļōżņØä ņäżļ¬ģļ│ĆņłśļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. ņśłņĖĪĒĢ©ņłś Ōæ®ņØĆ ņśłņĖĪĒĢ©ņłś Ōæ©ņŚÉņä£ ņé¼ņÜ®ĒĢ£ ņäżļ¬ģļ│ĆņłśļōżņØä ņé¼ņÜ®ĒĢśņŚ¼ ļŗ©Ļ│äņĀü ņäĀĒāØļ▓ĢņØä ĒåĄĒĢ┤ ļ│ĆņłśņäĀĒāØņØä ņ¦äĒ¢ēĒĢśņśĆļŗż.
ņśłņĖĪĒĢ©ņłś Ōæ¬ņØĆ ļ¬©ļōĀ ņäżļ¬ģļ│ĆņłśņÖĆ 1Ļ░£ņØś ņØĆļŗēņĖĄĻ│╝ 10Ļ░£ņØś ņØĆļŗēļģĖļō£ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśņśĆļŗż.
4. ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłś ņśłņĖĪļĀź ĒÅēĻ░Ć ļ░Å ņĄ£ņóģļ¬©ĒśĢ Ļ░£ļ░£
4.1 ņśłņĖĪļĀź ĒÅēĻ░Ć
ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░ņŚÉ ļ¬©ĒśĢņØä ņĀüĒĢ®ĒĢ£ Ļ▓░Ļ│╝ļŖö Table 4ņÖĆ Ļ░Öļŗż. NRMSEļź╝ ĻĖ░ņżĆņ£╝ļĪ£ ņŚ¼ļ¤¼ ļ¬©ĒśĢņØä ļ╣äĻĄÉĒĢ┤ļ│┤ņĢśņØä ļĢī Eq. (4)ņØś ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņŚÉ lassoļź╝ ĒåĄĒĢ£ ļ│ĆņłśņäĀĒāØĒĢ£ ņśłņĖĪĒĢ©ņłś ŌæŻĻ░Ć 10.61%ļĪ£ Ļ░Ćņן ļé«ņØĆ NRMSEĻ░ÆņØä Ļ░Ćņ¦ä Ļ▓āņØä ļ│╝ ņłś ņ׳ļŗż. ļö░ļØ╝ņä£ ņśłņĖĪĒĢ©ņłś ŌæŻļź╝ ņĄ£ņóģļ¬©ĒśĢņ£╝ļĪ£ ņäĀĒāØĒĢśņśĆļŗż.
4.2 ņĄ£ņóģļ¬©ĒśĢ Ļ░£ļ░£
4.1ņĀłņŚÉņä£ ņäĀĒāØļÉ£ ņĄ£ņóģļ¬©ĒśĢņØĖ ņśłņĖĪĒĢ©ņłś ŌæŻņŚÉ ļīĆĒĢ┤ ļ¬©ļōĀ ļŹ░ņØ┤Ēä░ņģŗņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒÜīĻĘĆĻ│äņłśļź╝ Ļ░▒ņŗĀĒĢśņśĆļŗż. ĻĖ░ņĪ┤ņŚÉ ĒĢ©ņłśņŗØņØä Ļ░£ļ░£ĒĢśĻĖ░ ņ£äĒĢ┤ 1994ļģäļČĆĒä░ 2011ļģäĻ╣īņ¦ĆņØś ļŹ░ņØ┤Ēä░ļ¦īņØä ņé¼ņÜ®ĒĢśņśĆļŖöļŹ░, ņĄ£ņóģļ¬©ĒśĢņØä ņäĀĒāØĒĢśņśĆĻĖ░ ļĢīļ¼ĖņŚÉ 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ņĀäņ▓┤ ļŹ░ņØ┤Ēä░ņģŗņØä ņé¼ņÜ®ĒĢśņŚ¼ ĒÜīĻĘĆĻ│äņłśļź╝ ņČöņĀĢĒĢśņśĆļŗż. Ļ░▒ņŗĀļÉ£ ĒĢ£Ļ░ĢĻČīņŚŁņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłś ņĄ£ņóģļ¬©ĒśĢņØĆ Eq. (10)Ļ│╝ Ļ░Öļŗż.
(10)
Eq. (10)ņŚÉņä£ 1(ņ¦ĆņŚŁ=ņ¦ĆņŚŁļ¬ģ)ņØĆ ĒĢ┤ļŗ╣ ņ¦ĆņŚŁļ¬ģņØ┤ļ®┤ 1ņØ┤Ļ│Ā, ņĢäļŗłļ®┤ 0ņØś Ļ░ÆņØä Ļ░Ćņ¦ĆļŖö ļŹöļ»Ėļ│Ćņłśļź╝ ņØśļ»ĖĒĢśļ®░, ĒÜīĻĘĆĻ│äņłśĻ░Ć Ēæ£ņŗ£ļÉśņ¦Ć ņĢŖņØĆ ņØ╝ļČĆ ņäżļ¬ģļ│ĆņłśļōżņØĆ lassoņØś ļ▓īņĀÉĒĢ©ņłśņŚÉ ņØśĒĢ┤ ĒÜīĻĘĆĻ│äņłśĻ░Ć 0ņ£╝ļĪ£ ņČöņĀĢļÉśļ»ĆļĪ£ ĻĖ░ņ×¼ĒĢśņ¦Ć ņĢŖņĢśļŗż. ņ┤Ø Ēö╝ĒĢ┤ņĢĪņØä Ļ│äņé░ĒĢĀ ļĢīļŖö ļ©╝ņĀĆ ļĪ£ĻĘĖ ļŗ©ņ£äņØś ņśłņĖĪĻ░ÆņØä ņ¢╗ņ¢┤ļéĖ ļŗżņØī, ļŗżņŗ£ ņ¦Ćņłś ļ│ĆĒÖśĒĢśņŚ¼ ņøÉļל ļŗ©ņ£äņØś ņśłņĖĪĻ░ÆņØä ņ¢╗ļŖöļŗż. ļ¬©ļōĀ ļŹ░ņØ┤Ēä░ņģŗņØä ņé¼ņÜ®ĒĢśņŚ¼ Ļ░▒ņŗĀļÉ£ ļ¬©ĒśĢņØś NRMSE Ļ░ÆņØĆ 6.31%ļĪ£ ņŗżņĀ£Ēö╝ĒĢ┤ņĢĪĻ│╝ ļ╣äĻĄÉĒ¢łņØä ļĢī ņĀüņĀłĒĢśĻ▓ī ņśłņĖĪĒĢśļŖö Ļ▓āņ£╝ļĪ£ ĒÅēĻ░ĆļÉśņŚłļŗż.
5. Ļ▓░ļĪĀ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĻĄŁļé┤ ņ×¼ļé£Ēö╝ĒĢ┤ņØś ņĀłļ░ś ņØ┤ņāüņØä ņ░©ņ¦ĆĒĢśĻ│Ā ņ׳ļŖö ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ļīĆņāüņ£╝ļĪ£ ļŗżņ¢æĒĢ£ ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀņØä ņĀüņÜ®ĒĢśņŚ¼ ņĀüņĀłĒĢ£ ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż.
ĒåĄĻ│äņĀü ļ¬©ĒśĢņ£╝ļĪ£ ņäĀĒśĢĒÜīĻĘĆļ¬©ĒśĢ, ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢ, ņŻ╝ņä▒ļČä ĒÜīĻĘĆļ¬©ĒśĢ, ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø ļ¬©ĒśĢņØä ņé¼ņÜ®ĒĢśņśĆĻ│Ā, ļ│Ćņłś ņäĀĒāØļ░®ļ▓Ģņ£╝ļĪ£ ļŗ©Ļ│äļ│ä ļ│ĆņłśņäĀĒāØļ▓ĢĻ│╝ ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ ņ┤Ø 11Ļ░£ņØś ĒĢ©ņłśņŗØņØä Ļ░£ļ░£ĒĢśņśĆļŗż.
ļīĆņāüņ¦ĆņŚŁņØĆ ĒśĖņÜ░Ēö╝ĒĢ┤Ļ░Ć Ļ░Ćņן ĻĘ╣ņŗ¼ĒĢ£ ĒĢ£Ļ░ĢĻČīņŚŁņØä ņäĀĒāØĒĢśņśĆĻ│Ā, ņóģņåŹļ│ĆņłśļĪ£ ļ¦żļģä ĻĄŁļ»╝ņĢłņĀäņ▓śņŚÉņä£ ņ×ÉņŚ░ņ×¼ĒĢ┤ ļ░£ņāØņŗ£ Ēö╝ĒĢ┤ņĢĪņØä ņ¦æĻ│äĒĢśņŚ¼ ņĀ£ņŗ£ĒĢśļŖö ņ×¼ĒĢ┤ņŚ░ļ│┤ņØś 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņĢĪ ņ×ÉļŻīļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. ņäżļ¬ģļ│ĆņłśļĪ£ļŖö ņ┤Ø Ļ░ĢņÜ░ļ¤ē, ņäĀĒ¢ēĻ░ĢņÜ░ļ¤ē, ņ¦ĆņåŹņŗ£Ļ░äļ│ä ņĄ£ļīĆĻ░ĢņÜ░ļ¤ē, ņ¦ĆņŚŁ ļ®┤ņĀü, ņ×¼ĒĢ┤ĻĖ░Ļ░äņØä ņé¼ņÜ®ĒĢśņśĆļŗż.
ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░(1994Ōł╝2011ļģä)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņśłņĖĪĒĢ©ņłśļź╝ ĻĄ¼ņČĢĒĢśņśĆĻ│Ā, ņØ┤ļź╝ ĒÅēĻ░ĆņÜ® ļŹ░ņØ┤Ēä░(2012Ōł╝2015ļģä)ņŚÉ ņĀüņÜ®ĒĢśņŚ¼ ņśłņĖĪļĀźņØä ĒÅēĻ░ĆĒĢśņŚ¼ ĒĢ£Ļ░ĢĻČīņŚŁņØś ņĄ£ņĀüņØś ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ ņäĀņĀĢĒĢśņśĆļŗż. ņŻ╝ņÜö Ļ▓░Ļ│╝ļź╝ ņÜöņĢĮĒĢśļ®┤ ļŗżņØīĻ│╝ Ļ░Öļŗż.
(1) 11Ļ░£ ĒĢ©ņłśņØś NRMSEļŖö 10.61Ōł╝13.89%ļĪ£ ļīĆļČĆļČäņØś ĒĢ©ņłśĻ░Ć ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ņĀüņĀłĒĢśĻ▓ī ņśłņĖĪĒĢśļŖö Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż.
(2) ņśłņĖĪļĀź ĒÅēĻ░Ć Ļ▓░Ļ│╝ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņŚÉ ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ņĀüņÜ®ĒĢ£ ĒĢ©ņłśņŚÉņä£ Ļ░Ćņן ņóŗņØĆ ņśłņĖĪļĀźņØä ļéśĒāĆļāłĻ│Ā, ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØä ņØ┤ņÜ®ĒĢ£ ĒĢ©ņłśņŚÉņä£ Ļ░Ćņן ļé«ņØĆ ņśłņĖĪļĀźņØä ļéśĒāĆļāłļŗż.
(3) ĒĢ£Ļ░Ģ ĻČīņŚŁņŚÉ Ļ░Ćņן ņĀüĒĢ®ĒĢ£ ĒĢ©ņłśļĪ£ ņäĀĒāØĒĢ£ ņĄ£ņóģĒĢ©ņłśļŖö ņØ╝ļ░śĒÖöņäĀĒśĢļ¬©ĒśĢņŚÉ ļ▓īņĀÉĒÖöļź╝ ĒåĄĒĢ£ ņČĢņåīņČöņĀĢļ▓ĢņØä ņĀüņÜ®ĒĢ£ ĒĢ©ņłśņśĆļŖöļŹ░, 1994ļģäļČĆĒä░ 2015ļģäĻ╣īņ¦ĆņØś ņĀäņ▓┤ ļŹ░ņØ┤Ēä░ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ĒÜīĻĘĆĻ│äņłśļź╝ Ļ░▒ņŗĀĒĢśļ®┤ ņśłņĖĪļĀźņØ┤ ļŹöņÜ▒ ņ”ØĻ░ĆĒĢśļŖö Ļ▓āņ£╝ļĪ£ ļéśĒāĆļé¼ļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļ¬ć Ļ░Ćņ¦Ć ĒĢ£Ļ│äņĀÉņØ┤ ņ׳ļŖöļŹ░ ņÜ░ņäĀ, ņóģņåŹļ│ĆņłśļĪ£ ņé¼ņÜ®ĒĢ£ ņ×¼ĒĢ┤ņŚ░ļ│┤ņ×ÉļŻīņØś Ļ▓ĮņÜ░ 1994ļģä ņØ┤ņĀäņØś ņ×ÉļŻīļŖö ņŗĀļó░ļÅäĻ░Ć ļé«Ļ│Ā, Ēśäņ×¼ņØś ņ×¼ĒĢ┤ņŚ░ļ│┤ ņ▓┤Ļ│äņÖĆ ņāüņØ┤ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ 1994ļģä ņØ┤Ēøä ņ×ÉļŻīļ¦īņØä ņé¼ņÜ®ĒĢśņŚ¼ ņĀäņ▓┤ņĀüņØĖ ņ×ÉļŻīņØś Ļ░£ņłśĻ░Ć ļŗżņåī ļČĆņĪ▒ĒĢ£ ĒĢ£Ļ│äņĀÉņØ┤ ņ׳ļŗż. ļö░ļØ╝ņä£ ņ▓┤Ļ│äĒÖöļÉ£ ņ×¼ĒĢ┤ĒåĄĻ│ä ņ×ÉļŻīĻ░Ć ņČĢņĀüļÉ£ļŗżļ®┤ ņČöĒøä ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļŹö ļéśņØĆ Ļ▓░Ļ│╝ļź╝ ņĀ£ņŗ£ĒĢĀ ņłś ņ׳ņØä Ļ▓āņØ┤ļŗż.
ļśÉĒĢ£ ņäżļ¬ģļ│ĆņłśļĪ£ ņłśļ¼ĖĻĖ░ņāüĒĢÖņĀü ņ×ÉļŻī, ņŗ£ĻĄ░ĻĄ¼ ļ®┤ņĀü, ņ×¼ĒĢ┤ĻĖ░Ļ░äļ¦īņØä Ļ│ĀļĀżĒĢśņśĆļŖöļŹ░ ņØ┤ ņÖĖņŚÉ ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ņäżļ¬ģĒĢĀ ņłś ņ׳ļŖö ļŗżļźĖ ņäżļ¬ģļ│ĆņłśļōżņØä Ļ│ĀļĀżĒĢśņ¦Ć ļ¬╗ĒĢ£ ļ¼ĖņĀ£Ļ░Ć ņ׳ņŚłļŗż. ĒŖ╣Ē׳ Ēö╝ĒĢ┤ņ¦ĆņŚŁņŚÉ ļ│ĄĻĄ¼ļ╣äĻ░Ć ņ¦ĆĻĖēļÉśĻ▒░ļéś ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ļīĆļ╣äĒĢśĻĖ░ ņ£äĒĢ£ ņśłļ░®ļ╣äĻ░Ć Ēł¼ņ×ģļÉ£ ņ¦Ćņ×Éņ▓┤ņØś Ļ▓ĮņÜ░, ļ│Ė ņŚ░ĻĄ¼ Ļ▓░Ļ│╝ļĪ£ ņĀ£ņŗ£ĒĢ£ ĒĢ©ņłśņŗØņØś ņśłņĖĪļĀźņØ┤ ļé«ņĢäņ¦ĆļŖö ĒĢ£Ļ│äĻ░Ć ņ׳ņŚłļŗż. ļö░ļØ╝ņä£ ļ│ĄĻĄ¼ļ╣äļéś ņśłļ░®ļ╣ä ļō▒ņØś ņĀĢņ▒ģņĀüņØĖ ņÜöņåīļōżņØä Ļ│ĀļĀżĒĢ£ ĒĢ©ņłśņŗØ Ļ░£ļ░£ņØ┤ ĒĢäņÜöĒĢĀ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĒĢ£Ļ░Ģ ĻČīņŚŁ ņĀäņ▓┤ļź╝ ĒĢśļéśņØś ĒĢ©ņłśņŗØņØä ĒåĄĒĢśņŚ¼ ĻĄ¼ņä▒ĒĢśņśĆļŖöļŹ░, ņŗ£ĻĄ░ĻĄ¼ļ│äļĪ£ ņ¦ĆņŚŁņĀü ĒŖ╣ņä▒ņØ┤ ļ░śņśüļÉ£ ĒĢ©ņłśņŗØņØä Ļ░£ļ░£ĒĢ£ļŗżļ®┤ ļŹöņÜ▒ ņĀĢļ░ĆĒĢśĻ│Ā ņśłņĖĪļĀź ļåÆņØĆ ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ ĒĢĀ ņłś ņ׳ņØä Ļ▓āņØ┤ļŗż.
ĻĖ░ņĪ┤ņØś ĻĄŁļé┤ŌŗģņÖĖ ņŚ░ĻĄ¼ņé¼ļĪĆļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ņŻ╝ļĪ£ ĒÖŹņłśĒö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśĻ▒░ļéś, 1Ļ░Ćņ¦ĆņØś ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀļ¦īņØä ņĀüņÜ®ĒĢśņŚ¼ Ēö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśļŖö ĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļŗżņ¢æĒĢ£ ĒåĄĻ│äņĀü ļ¬©ĒśĢĻ│╝ ļ│ĆņłśņäĀĒāØļ▓ĢņØä ņĀüņÜ®ĒĢśņŚ¼ ņé¼ņĀäņŚÉ ĒśĖņÜ░Ēö╝ĒĢ┤ļź╝ ņśłņĖĪĒĢśļŖö ĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆļŗż. ĒŖ╣Ē׳, ĻĖ░ņĪ┤ņØś Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłś Ļ░£ļ░£ņŚÉ ņĀüņÜ®ĒĢśņ¦Ć ļ¬╗Ē¢łļŹś ļŗżņ¢æĒĢ£ ĒåĄĻ│äņĀü ļ░®ļ▓ĢļĪĀļōżņØä ņĀüņÜ®ĒĢśņŚ¼ ņ×¼ĒĢ┤ĒåĄĻ│äĻĖ░ļ░ś ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ Ļ░£ļ░£ĒĢśņśĆĻ│Ā, Ļ░£ļ░£ļÉ£ ĒĢ©ņłśņŗØņØĆ ĒĢ£Ļ░Ģ ĻČīņŚŁņØś Ēö╝ĒĢ┤ņĢĪņØä ņĀüņĀłĒĢśĻ▓ī ņśłņĖĪĒĢśļŖö Ļ▓āņ£╝ļĪ£ ĒÅēĻ░ĆļÉśņŚłļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņĀ£ņŗ£ĒĢ£ ĒśĖņÜ░Ēö╝ĒĢ┤ņśłņĖĪĒĢ©ņłśļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ĒśĖņÜ░Ēö╝ĒĢ┤ ļ░£ņāØ ņĀäņŚÉ ņ¦Ćņ×Éņ▓┤ļ│äļĪ£ Ēö╝ĒĢ┤ ļ▓öņ£ä ļ░Å ņśüĒ¢źņØä ņśłņĖĪĒĢśĻ│Ā, ņśłļ░® ļ░Å ļīĆļ╣ä ņ░©ņøÉņŚÉņä£ ĒÜ©Ļ│╝ņĀüņØĖ ņ×¼ļé£Ļ┤Ćļ”¼ļź╝ ņŗżņŗ£ĒĢ£ļŗżļ®┤ ĻĄŁļé┤ ĒśĖņÜ░Ēö╝ĒĢ┤ ļ░£ņāØņØä Ēü¼Ļ▓ī ņżäņØ╝ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.




