



1. 서 론
상수도시스템의 비정상상황(혹은 이상 현상)을 식별하는 일반적인 방법은 압력 및 유량과 같은 시스템 특성값의 예측오차를 실시간으로 모니터링하여 사고의 발생을 감지하는 것이다. 여기서 예측오차란 특성값의 예측값과 실측값의 차이를 의미하며, 강화학습(Reinforcement learning), 지각추론(Perceptual inference), 의사 결정(Decision-making) 등의 추론 및 이론적 예측모델의 중심 개념이다(Den Ouden et al., 2012).
사고가 발생하지 않을 경우의 예측오차는 예측모델의 불확실성 및 실측데이터의 측정오류(Measurement error) 등으로 인해 발생하여 그 크기가 작지만, 사고가 발생할 경우에는 예측오차의 값이 상대적으로 증가한다. 때문에 오차의 값이 어느 특정 경계조건(Threshold)을 초과할 경우 비정상상황으로 판단하여 식별할 수 있다. 하지만, 상수도시스템에서 비정상상황을 예측하기 위해서는 관로사고 발생 시 비정상적인 수리거동을 판단해야하기 때문에 육안상 확인할 수 있는 상수도관 파괴 및 배수지 고갈과 같은 경우를 제외하고는 시스템의 계측기(e.g., 유량계, 압력계)로 부터 수집되는 계측데이터에 의존하게 되며, 이는 계측데이터의 품질과 규모 등에 따라 예측의 신뢰도가 달라진다. 상수도시스템의 비정상 수리거동을 데이터 기반으로 예측하기 위해서는 정상 및 비정상시의 수리학적 데이터를 축척하고 이 데이터를 학습해야하며, 결측치(Missing data)가 적거나 데이터의 규모가 클수록 예측오차가 줄어든다. 정상운영시의 수리학적 데이터는 스마트미터 및 다양한 계측기의 데이터를 활용하여 학습은 가능하나, 사고발생 후 수집된 비정상적인 수리데이터는 현장실험 및 실제 발생한 사고 이외에는 확보할 수 없기 때문에 실제 비정상상황을 모사하여 모의사고 데이터 생성하는 기법이 필요하다.
일반적으로 상수도시스템 이상감지 기법은 데이터 중심(Data-driven)의 모델이 대부분이며 이러한 모델이 갖는 주요 한계점은 다양한 시나리오를 근거로 계측된 데이터와 일관성을 나타낼 수 있는 자료의 수집이다. 하지만, 관 파손과 같은 비정상상황은 비정기적으로 발생하고 데이터 수집이 어렵기 때문에 필요한 사고데이터를 구축할 수 있는 유일한 방안은 상수도시스템 수리해석 모형(e.g., EPANET (Rossman, 2000))을 사용하여 모의사고 데이터를 생성하는 것이다(Menapace et al., 2020). 상수도시스템 수리해석 모형은 수요자의 물 사용량(Demand)을 입력변수로 사용하여 상수도의 수리해석 특성값(e.g., 유량, 압력)을 계산한다. 하지만 수리해석 모형의 수요량 입력변수는 일반적으로 과거데이터에 기반하여 시나리오별 입력 또는 평균값을 사용하기 때문에 그 값이 고정적이다. 일일 수요량 패턴을 적용하여 매시간별 다른 크기의 수요량을 고려할 수는 있지만 동일한 시간에는 항상 같은 수요량이 적용됨에 따라 항상 동일한 결과가 계산된다(Fig. 1). 즉, 과거데이터에만 의존하여 수리해석 모형을 활용하여 모의사고 데이터를 생성할 경우 매시간 항상 동일한 결과값이 구축될 것이다.
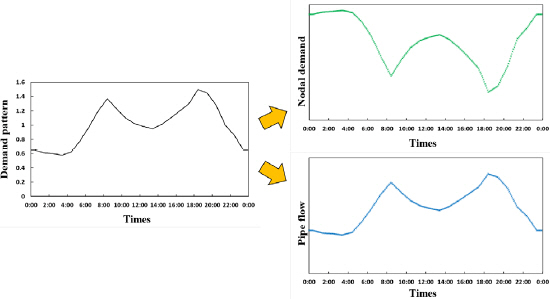
따라서, 이러한 한계점을 해결하기 위해서는 수리해석 모형을 통해 계산된 결과값에 다양한 변동성(e.g., 측정오류, 수요량 패턴)을 고려하여 수리해석이 수행될 때 마다 매번 다른 형태의 모의사고 데이터를 생성하였다.
상수도시스템의 변동성은 매시간 변하는 수요량 및 계측데이터의 측정오류 등을 고려하기 위한 요소이다. 유량, 압력, 수요량, 저수지 수위 등 실제 수집되는 모든 계측데이터는 변동성과 측정치 오류를 가지고 있기 때문에 이러한 요소를 항상 고려해야한다(Sumer and Lansey, 2009). 이러한 변동성을 고려하여 관 파손사고의 모의데이터를 생성한 연구가 다수 수행된 바 있다. Jung and Lansey (2015)와 Hagos et al. (2016)은 개별 절점 수요량의 변동성을 정규분포 식으로 분산된다고 가정하여 수요량에 변동성 값을 추가하였다. 관망해석 모형의 입력자료를 매번 상이하게 설정함으로써 항상 다른 값의 유량 및 압력이 계산되도록 설정하였다. 더 나아가, 계산된 특성 값에도 정규분포 형태를 갖는 변동성을 고려하여 측정치 오류까지 고려하였다. 이러한 과정을 거쳐 생성된 모의사고 데이터는 실제로 계측된 데이터가 갖는 변동성 및 측정오류 등의 성질을 갖는다.
상수도시스템의 수리해석 모형을 사용하여 모의사고 데이터를 생성할 경우 수많은 시나리오를 모의할 수 있다는 장점 또한 존재한다. 실제 사고가 발생하는 경우는 드물기 때문에 사고 발생위치 또한 매우 제한적이다. 하지만 관망해석 모형을 사용할 경우 분석하고자 하는 사고 위치를 결정하여 그 영향을 파악할 수 있다. 실제로 과거 수행된 연구에서는 분석하고자하는 관 파손사고의 위치 및 크기를 설정하여 그 결과를 보였다(Ahn and Jung, 2019; Zhou et al., 2019; Wang et al., 2020; Zhao et al., 2020). 최근에는 Generative Adversial Networks (GANs)라는 딥러닝 기술을 적용하여 상수도시스템의 사고데이터를 생성하는 연구가 수행되기도 하였다(Zhang et al., 2020).
이러한 연구 중 Kang and Lansey (2009)의 연구에서는 관망해석 모형을 이용한 모의사고 데이터 생성 단계를 잘 나타내었다. Fig. 2는 수요량 추정을 위해 생성된 데이터의 단계별 과정을 보여주지만, 관망해석 모형에 관 파손사고를 모의하는 emitter만 추가된다면 기존의 모의사고 데이터 생성 연구와 동일하다.
Fig. 2
The Process of Generating Simulated Data Using a Hydraulic Analysis Model (a) Original Demand Pattern before the Variation is Considered, (b) Demand Pattern Considered the Variation (c) Hydraulic Data (e.g., Pipe Flow) Considered the Variations and Measurement Error (Kang and Lansey, 2009)
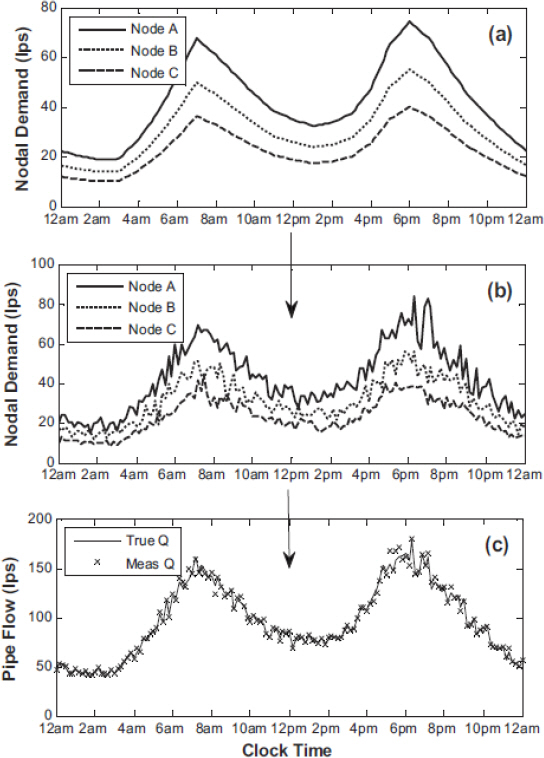
Fig. 2(a)는 변동성이 부가되기 전 과거평균 수요량을 보여준다. 앞서 설명했듯이 매시간 고정적인 값을 갖기 때문에 관망해석 수행 결과는 항상 동일하다. 하지만 평균 수요량 패턴에 변동성을 줌으로써 Fig. 2(b)와 같이 매시간 상이한 수요량을 모형의 입력자료로 사용할 수 있다. 이는 Fig. 2(c)와 같이 수요자의 물 사용 행동 패턴에 따라 시시각각 변하는 유량(혹은 압력)이 도출된다. 이 결과값에 다시 한 번 변동성을 주어 계측데이터의 측정오류를 고려한다. 따라서 최종적으로 생성된 모의사고 데이터는 실제 수집되는 사고데이터 갖는 성질을 포함한다.
또한, 최근 연구에서 Xu et al. (2020)은 보다 현실적인 모의사고 데이터를 생성하기 위해 총 세 가지의 요소를 고려하였다. 세 가지 요소는 상수도시스템 전체 수요량의 변동성, 각 절점별 수요량의 변동성, 계산된 압력 및 유량의 변동성이다. 이는 상수도시스템 수요량에 영향을 주는 날씨(e.g., 계절), 온도, 휴일 등의 인자를 고려하기 위함이다. 또한, 고객의 행동 패턴에 따라 시시각각 변하는 수요량을 반영하였고, Jun et al. (2021)은 측정치 오류와 입력변수의 변동성을 다르게 설정하여 실제 상수도시스템의 수요적 불확실성을 고려하여 현실성 높은 모의데이터를 생성할 수 있었다. 이 밖에도 수리해석 모형을 활용하여 모의데이터를 생성한 기법은 비정상상황시의 수리데이터 생성 뿐만 아니라 사이버공격(Momeni and Piratla, 2019) 및 수질사고(Uber et al., 2007) 데이터 생성에도 쓰인바 있다.
하지만, 위와 같은 연구들은 상수도 시스템의 모의를 통해 수리해석 데이터를 통한 정상⋅비정상 운영을 탐지 할 수 있었지만, 이러한 연구는 실제 현장에 대한 수요량의 불확실성과 현장여건이 반영되지 않은 한계점을 포함하고 있다. 따라서, 데이터 기반 상수도시스템 비정상상황 탐지 성능 향상을 위해 기존 수리해석을 통한 모의데이터 생성기법과 실제 상수도시스템에 설치되어 있는 스마트 미터의 계측데이터를 사용하여 시스템 이상탐지 성능 및 신뢰도 개선이 필요하다.
따라서, 본 연구에서는 앞선 연구에서 제안한 모의사고 데이터 생성기법에 스마트미터 데이터를 적용하여 학습데이터의 다양성과 신뢰도 향상을 위해 새로운 모의사고 데이터 생성 기법을 제안하고 기존 방법론과 비교분석한다. 본 연구를 수행하기 위해 먼저, (1) 상수도시스템 수리해석 모형을 이용한 모의사고 데이터와 (2) 현장시험 또는 과거사고 데이터를 활용한 모의사고 데이터를 생성하여 각각의 기법을 이용한 데이터 생성기법의 정량적 성능평가를 수행하였다.
2. 상수도관망 모의데이터 생성기법
본 연구에서 제안한 상수도시스템의 수리학적 이상감지를 위한 모의데이터 생성기법은 (1) 기존의 상수도시스템 수리해석 모형을 이용한 방법론; (2) 실제 발생한 비정상상황(e.g., 현장시험, 과거 발생한 사고) 데이터를 활용한 방법론; (3) 앞선 두 기법을 동시에 활용한 방법론에 대해 설명한다. 제안된 방법론을 실제 상수도시스템에 적용하여 제안한 방법론들의 이상감지 성능 및 결과를 비교분석한다.
2.1 수리해석 모형을 이용한 모의사고 데이터 생성
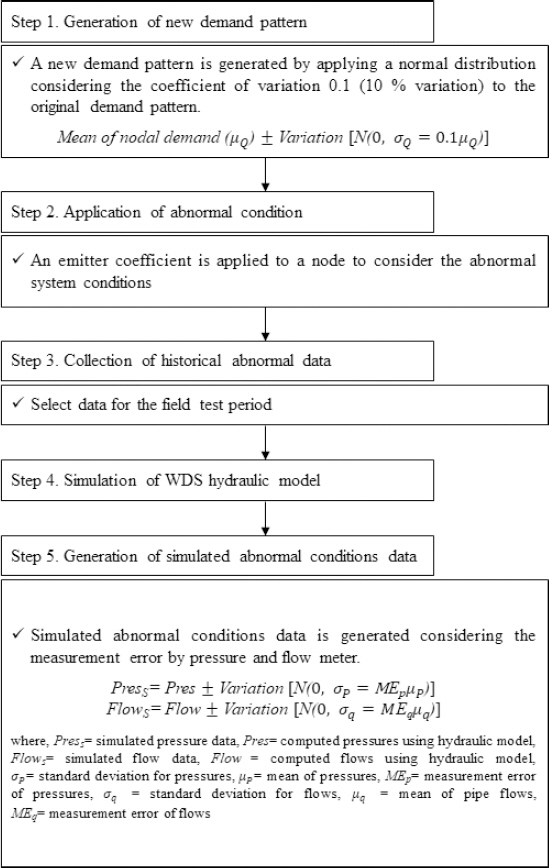
본 연구에서 제안하는 모의데이터 생성기법 중 첫 번째 방법은 상수도시스템 수리해석 모형을 활용하여 모의사고 데이터를 생성하는 기법이다. 해당 방법론을 적용하기 위해서는 먼저 실제 현장의 계측데이터와 검⋅보정이 완료된 상수도시스템 수리해석 모형(e.g., EPANET)이 있어야하며, 모든 입력 매개변수[e.g., 수요량 패턴, 절점별 하루 평균 수요량, 관로 정보(관경 및 관길이)] 역시 구축되어있어야 한다. 관망해석 모형을 이용한 모의사고 데이터 생성 기법은 구축된 모형의 입력자료 중 수요량 패턴에 변동성을 주어 수리해석의 입력자료 중 변동성이 고려된 수요량 패턴을 구성한 후 비정상상황 시나리오를 고려하여 수리해석 데이터를 생성하고, 측정오차를 고려하여 최종 모의사고 데이터를 생성한다. Fig. 3은 관망해석 모형을 이용한 모의사고 데이터 생성 기법의 순서도이다.
Fig. 3
Flow Chart of Generating Simulated Abnormal Conditions Data Using the Hydraulic Analysis Model

Step 1에서는 기존 구성된 상수도시스템 모형의수요량 패턴에 변동성을 고려하여 실제 용수 사용자의 수요량 패턴을 구성한다. 이때, 변동성은 10%로 가정하여 변동계수(coefficient of variation) 0.1을 갖는 정규분포를 사용하여 고려한다(Jung and Lansey, 2015).
변동성을 고려한 수요패턴(Fig. 4)을 생성한 이후에는 관 파손사고의 위치 및 크기를 설정한다. 관망해석 모형을 수행하여 모의사고 데이터를 생성하는 경우에는 그 위치와 크기를 사용자가 지정하여, 또는 무작위로 설정할 수 있다.
이는 본 연구에서 사용한 실제 소화전을 개방 시 방류량을 기준값을 바탕으로 설정하였다.
이후 Step 3에서 상수도시스템 비정상상황을 고려한 모형에 수리해석을 수행하여 압력 및 유량해석결과를 출력한다. Step 4에서는 출력된 수리해석 결과에 Step 1에서 수행하였던 변동성을 부여한다. 변동성은 현실적인 모의사고 데이터의 생성을 위해 압력 및 유량 계측기의 계측 오류를 고려하여 매개변수인 σp와 σq을 고려한 정규분포를 수행하여 최종 상수도시스템 모의사고 데이터를 생성한다.
2.2 실제 발생한 비정상상황 데이터를 활용한 모의사고 데이터 생성 기법
본 연구에서는 기존 방법뿐만 아니라 실제 수집된 비정상상황 데이터(e.g., 현장시험 및 과거사고 데이터)의 특성을 반영하여 모의사고 데이터를 생성하는 기법을 제시한다. 앞서 소개한 기존의 기법은 수리해석 모형을 이용하여 여러 상황의 시나리오를 고려하여 데이터를 생성할 수 있지만, 이는 실제 계측된 자료의 정보, 특성, 형태 등을 반영하지 않고 오직 과거에 수집된 데이터(e.g., 과거평균 수요량)만을 고려하여 압력 및 유량 등의 출력데이터를 계산할 뿐이다. 실제 발생하였던 비정상상황 데이터에 변동성을 부가하여 실제로 계측된 데이터와 비슷한 성질을 갖는 모의사고 데이터를 얻는다면 실제 관 파손사고가 발생하였을 때 효율적인 탐지가 가능하다. 즉, 실제 발생한 비정상상황 사고의 자료를 충분히 구축한 이후에 관 파손 탐지를 수행한다면 기존 탐지 결과보다 우수한 성능을 보일 것이다. 따라서 본 연구에서는 수집된 실제 비정상상황 데이터를 기반으로 모의사고 데이터를 생성하여 실제 발생한 사고가 계측데이터(압력, 유량 등)에 주는 영향을 고려하고자 한다. Fig. 5는 실제 비정상상황 데이터를 활용한 모의사고 데이터 생성의 순서도를 나타낸다.
Fig. 5
Flow Chart of Generating Simulated Abnormal Conditions Data Using Field Tests or Past Accident Data

실제 비정상상황 데이터를 활용한 모의사고 데이터 생성기법의 적용을 위해서는 먼저 충분한 규모의 데이터 확보가 필수적이다. 예를 들어, 본 연구에서 사용한 비정상상황 데이터는 대상관망의 소화전을 개방하여 수집한 유량 및 압력 데이터를 사용하였다. 본 방법론은 소화전을 개방한 전체 기간(e.g., 5분) 동안 수집된 실제 비정상상황 자료를 활용하여 모의사고 데이터를 생성한다.
본 절에서 제안한 기법은 기존 방법론보다 실제 발생한 비정상상황 데이터와 비슷한 성질을 갖는 데이터 생성이 가능하다는 장점이 있다. 이때 데이터의 변동성은 σp와 σq매개변수를 고려하여 기존의 수리해석 모형을 이용한 사고데이터 생성기법과 동일한 과정을 거쳐 생성한다.
2.3 현장시험 데이터와 모형을 활용한 모의사고 데이터 생성 기법
앞서 설명한 두 방법론에서는 수리해석 모형 및 실제 발생한 비정상상황 데이터를 활용하여 모의사고 데이터를 생성하는 기법을 제시하였다. 본 절에서 제안할 방법론은 앞서 제시한 두 가지 기법의 한계점을 모두 보완하는 데이터 생성기법이다. 과거에 수집된 자료에 의존하여 그 결과를 계산하는 수리해석 모형을 이용한 데이터 생성기법을 실시간으로 계측되는 데이터와 연결한다면 상수도시스템의 현황을 보다 정확히 반영하여 압력 및 유량의 값을 계산할 수 있다. 또한, 수집된 현장시험 또는 과거사고 데이터와 같은 비정상상황의 정보를 활용하여 모의사고 데이터를 생성함으로써 실제 발생한 사고의 특성을 전반적으로 반영할 수 있다. 실제 발생한 비정상상황 데이터와 수리해석 모형을 활용한 모의사고 데이터 생성 기법의 순서도는 Fig. 6과 같다.
Fig. 6
Flow Chart of Generating Simulated Abnormal Conditions Data Using Hydraulic Analysis Model and Field Tests Data
우선, 현장시험 데이터와 모형을 활용한 모의사고 데이터 생성 기법은 방법론 1의 기존 구성된 상수도시스템 모형의 수요량 패턴을 실제 계측 데이터를 바탕으로 획득한 수요량 패턴에 변동성을 고려하여 실제 용수 사용자의 수요량 패턴을 구성한다. 이후 비정상상황의 규모(e.g., 관 파손의 크기) 및 그로 인해 손실된 물의 양을 결정할 때는 실제 현장시험에서 적용한 방류량(Fire hydrant flow)을 고려하며, 이를 기 구축된 수리해석 모형에 입력자료로 활용하여 수리결과를 출력한다. 이후, 앞선 방법론과 동일하게 압력 및 유량 계측기의 계측 오류를 고려하여 상수도시스템 모의사고 데이터를 생성한다.
3. 적용 및 결과
본 연구에서는 상수도시스템의 수리학적 이상감지를 위한 모의데이터를 생성하기 위한 3가지 방법론을 제안하였다. 제안한 모의데이터 생성기법을 통한 이상감지 결과를 비교분석함으로써 새로 제안한 모의사고 데이터 생성기법의 적용성 및 우수성에 대해 설명한다. 본 연구에서 제안된 모의데이터 생성기법을 검증하기 위해서 실제 상수도시스템인 J-town network에 적용하였다. 또한, J-town network의 비정상상황을 모의하기 위해 소화전을 개방하여 관 파손시의 데이터(압력 및 유량 등)을 수집하였다.
3.1 대상 상수도관망
본 연구에 적용된 상수도시스템은 J-town network로서 526개의 절점, 580개의 관로, 1개의 배수지로 구성되어 있으며, 관로의 대부분은 100 mm의 관경이 배치되어 있으며, 전체 상수도관망의 하루 평균 수요량은 84 m3/h이다. 해당 구역에는 대수용가 스마트 미터 5개, 이상감지용 압력계 5개 및 소블록 유입점의 유량 및 압력을 측정하는 센서 1개가 설치되어 있다. 모든 데이터의 측정 시간 간격은 1분이며 계측기의 위치와 J-town network의 관망도는 Fig. 7과 같다.
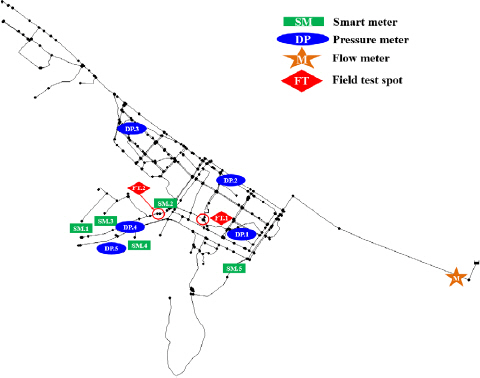
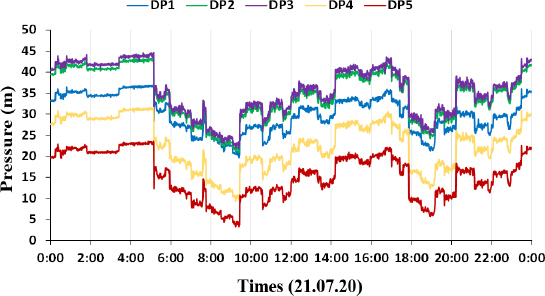
구성된 J-town network에서는 수요량 패턴 정보가 존재하지 않아 64일 동안 실제 계측된 압력계(Fig. 8) 데이터의 평균값을 고려하여 수요량패턴을 계산하였다.
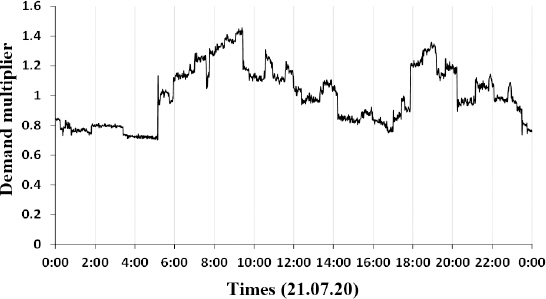
하지만, 실시간으로 계측되는 데이터가 있다면, 이를 관망해석 모형에 활용하여 수요량 패턴의 재조정이 가능하다. 이러한 재조정은 실제 계측되고 있는 데이터를 보다 현실적으로 반영하여 모의사고를 생성할 수 있다.
3.1.1 계측 데이터 정보
본 연구에서는 사용한 데이터의 계측기간은 1차와 2차로 나뉘며, 1차는 2021.02.26 0시부터 2021.03.21 23:59시, 2차는 21.06.09 15시부터 21.07.28 23:59시까지 측정된 데이터 항목을 저장한다. 본 연구에서는 0시부터 14:49시까지의 데이터 중 누락된 21.06.09의 데이터를 제외하고 2021.07.19.까지의 총 64일 동안 계측된 데이터 항목을 활용하여 상수도시스템 모의사고 데이터를 생성하였다. 또한, 21.07.19 이후의 자료에는 소화전 개방을 통한 모의 관로 파손사고 데이터가 포함되어있기 때문에 이 또한 제외하였다. 계측데이터의 결측치에 대해서는 그 전 시간(1분 전)에 측정된 데이터와 동일한 값으로 대체하였다. 또한, 본 연구에서 제안한 모의사고 데이터 생성기법의 측정오차 매개변수는 J-town network에 설치된 계측기 정보를 기반으로 설정하며, 각 매개변수 값은 유량계의 경우 0.35% (= Ep) (σ q = 0.35 100 μ q σ p = 0.2 100 μ p
3.1.2 관 파손사고 모의데이터 항목
현장시험 데이터는 본 연구에서 제안한 현장시험 또는 과거사고 데이터를 활용한 모의사고 데이터 생성 기법의 적용성을 검토하기 위해 실제 소화전 개방시험을 통해 수집된 모의 관로 파손사고 데이터를 활용한다. 모의 관로 파손사고 데이터는 21.07.20~21.07.21의 야간 최소유량(Minimum night flow) 시간대에 소화전을 개방함으로써 수집하였으며, 소화전의 개방 시간 및 시험절차는 Table 1과 같다.
Table 1
Collection of Field Test Data by Opening Fire Hydrants
소화전개방 시험은 5분 간격으로 개방 및 폐쇄를 반복하였으며, 개방시 방류량 크기는 5 m3/h, 10 m3/h, 20 m3/h로 설정하여 시험을 진행하였다.
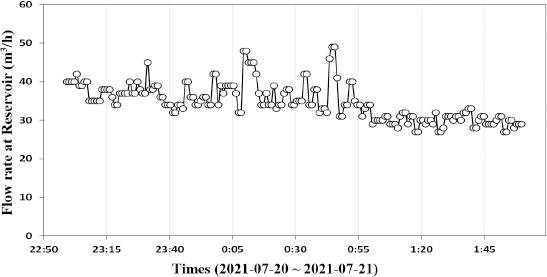
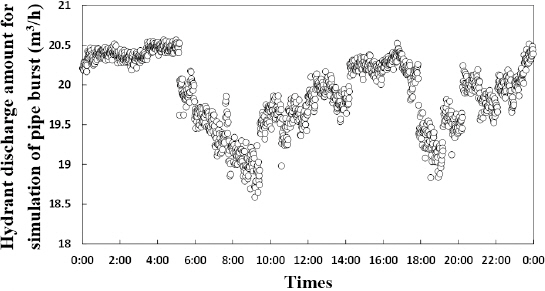
Fig. 10은 모의 관로 파손사고 시험 기간 동안 J-town network의 유입점 유량의 변화를 보여준다. 소화전 개방 전에는 유량이 대체로 일정하며 40 m3/h를 넘는 경우가 거의 없지만, 소화전을 개방함으로써 그 값이 증가한다. 이는 특히 각 소화전의 3차 개방에서 그 변화를 쉽게 파악할 수 있다. 3.3절에서는 현장시험을 통해 수집된 정상 및 비정상 데이터를 활용한 모의사고 데이터 생성에 대해 자세히 설명한다.
3.2 관망해석 모형을 이용한 모의사고 데이터 생성기법
모의사고 데이터 생성을 위한 첫 번째 방법론은 관망해석 모형을 사용하며, 과거에 계측된 데이터를 분석하여 구축한 수요량 패턴을 적용하여 결과를 도출한다. 본 절에서는 모의사고 데이터의 결과를 분석하기에 앞서, 구축된 수요량 패턴에 따라 생성된 정상데이터의 형태를 확인하고자 한다.
Fig. 11은 관망해석 모형과 구축된 수요량 패턴을 사용하여 계산한 각 압력계의 압력 값이다. 64일 동안 5개의 압력계로부터 측정된 압력의 평균값과 정확히 일치하지는 않지만 그 오차의 크기가 작으므로 구축된 수요량 패턴은 과거 평균 사용량을 잘 나타낸다고 할 수 있다. 예를 들어, DP3의 경우 하루 동안의 평균 오차 값이 7.2%이다. 단, 이 방법론의 한계점으로는 실시간 계측데이터의 예측이다. 결과 생성에 기반이 되는 자료가 과거에 의존하기 때문에 압력 및 유량 등의 정상데이터 예측은 힘들다. 하지만, 관망해석을 수행하여 사용자 혹은 상수도시스템 운영관리자가 원하는 만큼의 모의사고 데이터를 생성할 수 있다는 장점이 있다. 이 목적을 달성하기 위해 필요한 자료는 수요량 패턴이 구축되어있는 관망해석 모형 및 압력계/유량계의 계측 오차 정보이다. 이를 사용하여 생성한 결과는 아래와 같다.
Fig. 11
Pressure Results for Normal Condition Calculated by the Hydraulic Model Considering the Generated New Demand Pattern
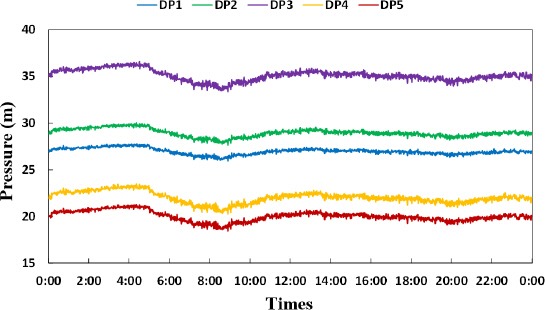
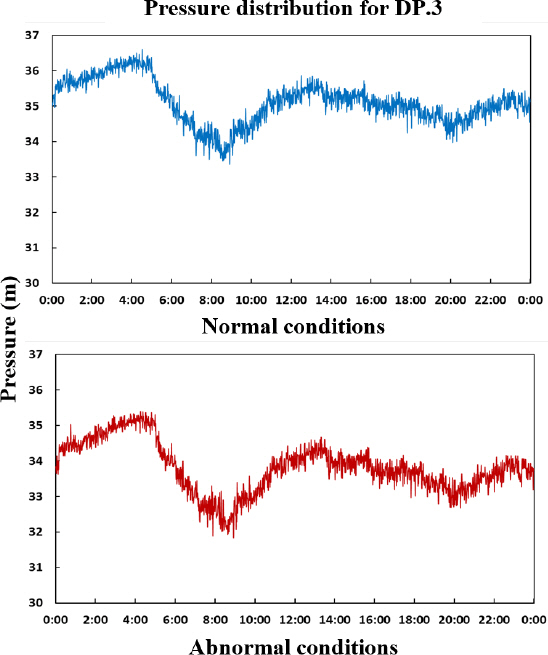
Fig. 12는 상수도시스템 내 무작위의 위치에서 관 파손사고가 발생하여 20 m3/h의 물이 손실될 때의 DP3 압력분포를 나타낸다. 다른 압력계의 경우에도 그 값의 크기만 상이할 뿐 동일한 형태를 보이기 때문에 본 연구에서는 압력계 DP3의 결과만을 나타내었다. 사고가 발생하기 이전의 계측데이터는 물 사용자의 수요량 변동성만 나타날 뿐 관 파손의 흔적은 보이지 않는다. 하지만 모의사고 데이터에는 압력의 값이 전반적으로 작아졌음을 확인할 수 있다. 이는 상수도시스템에 관 파손사고로 인해 추가적으로 흐르는 유량 때문에 손실수두가 상승하여 압력이 줄어든 결과이다.
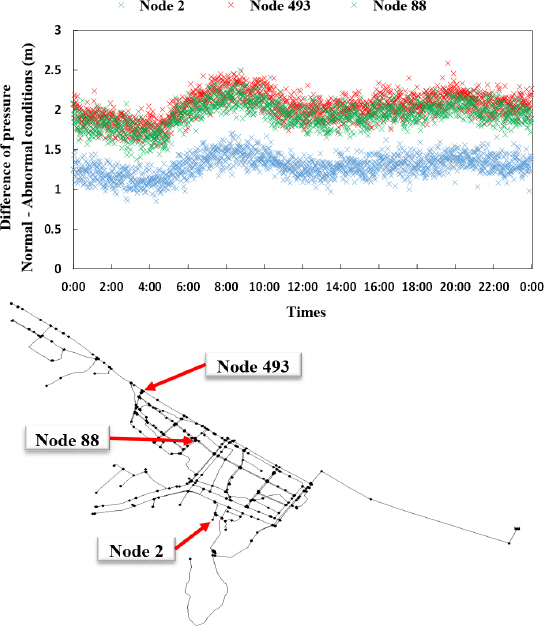
관 파손의 영향은 Fig. 13을 통해 보다 명확히 확인할 수 있다. 추가적으로 흐르는 유량으로 인해 압력이 감소하였고 때문에 정상데이터 및 모의사고 데이터의 차이가 발생한다. 하지만 그 차이의 크기는 다른데 이는 관 파손이 일어난 위치에 따라 상이하다. 같은 크기의 사고가 발생하였더라도 그 위치가 관 말단이라면, 추가적인 유량이 관 말단까지 흐르면서 더 큰 크기의 손실수두가 누적된다. 반면에, 물이 공급되는 저수지 근처에서 사고가 발생하였더라면 손실수두의 값은 상대적으로 작다. 이와 같이 수리해석 모형을 활용하여 모의사고 데이터를 생성할 경우 수많은 모의사고 시나리오를 고려할 수 있다는 장점이 있다. 사고의 위치를 조정하여 관 파손이 상수도시스템에 주는 영향을 비교분석 할 수 있고, 그 크기를 조절하여 크기에 따른 압력의 변화 정도를 분석할 수 있다. 하지만, 앞서 말했듯, 해당 방법론은 실시간 계측데이터의 현황을 반영할 수 없다. 또한, 관망해석 모형과 과거평균 데이터에 의존하기 때문에 실제 발생한 사고 데이터(e.g., 현장시험 데이터)의 특성을 반영하지 못한다는 단점이 존재한다.
3.3 실제 발생한 비정상상황 데이터를 활용한 모의사고 데이터 생성 기법
모의사고 데이터 생성을 위한 두 번째 방법론은 실제 발생한 비정상상황 데이터를 활용한다. 이 방법론은 관망해석 모형이 필요하지 않으며 소화전 개방 등의 현장시험 혹은 수요자의 민원 등으로 인해 확인된 실제 비정상상황에 대한 계측데이터만 준비되어있다면 이에 변동성을 부가하여 수많은 모의사고 데이터를 생성할 수 있다.
Fig. 14는 21.07.21 00:10분에 2번 소화전을 열어 수집된 DP02 및 DP03 압력을 활용하여 생성한 모의사고 압력 데이터이다. 보다시피 변동성을 부가하여 현장시험 압력과 동일하지는 않지만 그와 비슷한 값을 갖는 데이터를 독립시행횟수(이 경우 1,000번)만큼 생성하였다. 이를 통해 실제 수집된 데이터의 성질에 기반하여 그 특성이 반영된 모의사고 데이터를 구축할 수 있다. 특성이라면, 실제 발생한 사고에 따른 압력의 변화 및 그 변화가 전반적으로 상수도시스템에 주는 영향 등이 있다. 관망 내에 설치된 계측기가 많을수록 관 파손사고가 시스템에 미치는 영향을 자세히 파악할 수 있으며 계측기 개수에 따라 다양한 모의사고 시나리오를 고려할 수 있다. 예를 들어, 총 17개의 센서(스마트미터, 압력계, 유입점)가 설치된 J-town network의 경우 매 독립시행횟수마다 17개의 다른 값을 갖는 모의사고 데이터 셋을 생성할 수 있으며, 이는 오직 2개의 센서로 모의사고 데이터 셋을 생성하는 경우보다 그 변동성이 크다. 이때, 변동성은 오차 정보를 토대로 설정된 정규분포를 활용하여 계산된다. Fig. 15는 이러한 특성을 보여준다.
Fig. 14
Results of Simulated Abnormal Condition’s Data (Pressure) Generated by Field Test Data Using Fire Hydrants
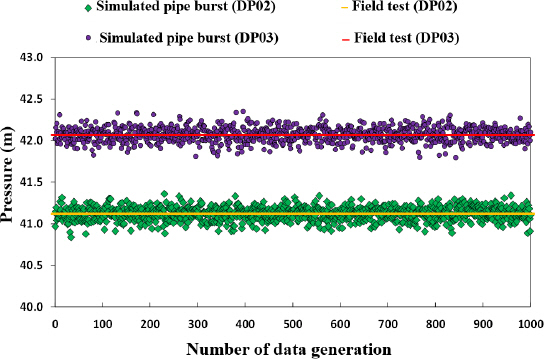
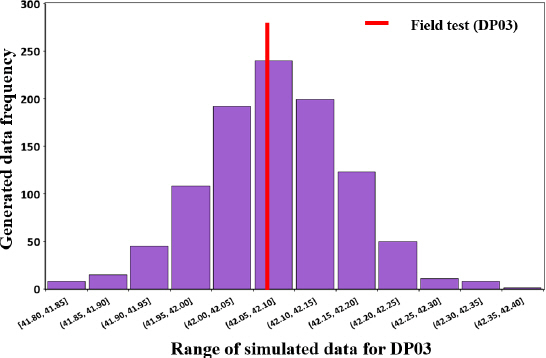
본 연구에서는 1,000번의 모의데이터를 생성하였으며, 생성된 모의사고 데이터 중 85% 이상은 실제 측정된 사고 데이터와 유사한 값을 가지며, 오차가 큰 경우는 약 10% 미만으로 판단된다. 하지만 매시간 사용되는 수요량에 따라 관 파손이 압력변화에 미치는 영향이 다르기 때문에 이러한 경우도 고려해야한다. 해당 방법론은 이러한 특성까지 반영하여 모의사고 데이터를 생성하였지만, 관망해석 모형을 사용했을 경우와는 다르게 사고의 위치에 대한 고려가 제한적이다. 이 경우, 사고의 위치는 소화전 1과 2 두 가지이며 다른 위치에서 사고가 발생하였을 경우가 미치는 영향을 분석할 수 없다. 또한, 발생한 사고의 크기도 소화전만을 조절하여 설정할 수 있으며, 데이터가 수집된 이후에는 그 값을 변형할 수 없는 점이 제한된다.
3.4 현장시험 데이터와 관망해석 모형을 활용한 모의사고 데이터 생성
본 절에서는 관망해석 모형 및 현장시험(또는 과거사고) 데이터를 모두 활용하여 모의사고 데이터를 생성한다. 다만, 첫 번째 방법론과는 다르게 실시간으로 계측된 데이터를 기반으로 관망해석을 수행하여 첫 번째 방법론의 단점을 보완한다. 즉, 실시간으로 수집된 계측데이터를 바탕으로 상수도시스템의 현황을 보다 더 정확히 파악할 수 있다.또한, 현장시험 데이터와 동일한 관 파손의 크기를 고려하여 실제 수집된 비정상상황 데이터와 비슷한 자료의 생성이 가능하다. 본 연구에서는 관망해석 모형 내 소화전의 위치에 4의 값을 갖는 emitter 계수를 적용하여 평균 약 20 m3/h를 갖는 관 파손사고를 모의하였다. 20 m3/h의 크기를 갖도록 설정한 것은 21.07.21 0:10에 소화전2를 개방했을 때와 0:45에 소화전1을 개방하였을 때 해당 크기만큼 유입점의 유량이 증가하였기 때문이다. Fig. 16은 관 파손크기의 한 예를 보여준다. 이와 같이 실시간 계측된 데이터를 기반으로 실제 시험한 자료와 동일한 관 파손의 크기를 동일한 위치에 적용시켜 생성한 모의사고 데이터는 실제 발생한 관 파손사고가 상수도시스템에 미치는 특성을 보다 정확하고 현실적으로 갖는다.
따라서 이와 같이 구축된 비정상상황 데이터를 활용한다면 기존의 방법론이 갖는 단점을 보완하고 추후 사고를 방지하는데 유용하게 쓰일 수 있다. 또한, 사고를 관망 내 여러 곳에 위치시켜 어느 지점이 취약한지, 어떤 곳에서 사고가 발생하였을 때 시스템에 미치는 영향이 큰지 등의 분석이 가능하다. 아래 Fig. 17은 현장시험 데이터와 관망해석 모형을 활용한 모의사고 데이터 생성 기법을 적용하였을 경우 각 압력계의 값을 보여준다.
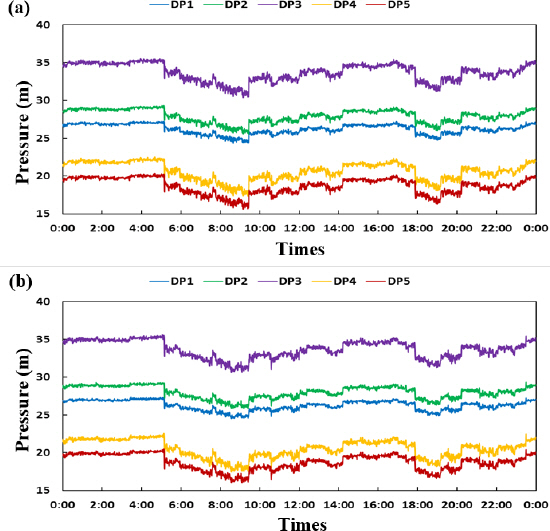
소화전1과 소화전2를 개방하였을 경우 각 압력계에 미치는 영향은 비슷하다. 하지만, 소화전의 위치를 바꿀 경우 혹은 관 파손사고 위치가 달라질 경우 각 압력계에서 측정되는 압력은 상이할 수 있으며 같은 크기의 관 파손이더라도 더 큰 영향일 미칠 수 있다. 본 연구에서 제안하는 방법론은 이러한 분석까지 수행가능하기 때문에 기존 방법론에 비해 큰 장점을 지닌다.
4. 결 론
본 연구에서는 상수도시스템 수리해석 모형 및 현장시험 데이터를 활용하여 모의사고 데이터를 생성하는 방법론을 제안하였다. 첫 번째 방법은 검⋅보정이 완료된 상수도시스템 수리해석 모형을 이용하여 운영관리자가 확인하고자하는 관 파손사고의 위치 및 크기의 영향을 모의할 수 있다. 많은 분석을 통해 실제 사고가 발생하기 이전에, 사고에 취약한 지역 및 상대적으로 안전한 지역 등을 파악하여 이에 대한 대응 매뉴얼을 수립할 수 있다. 두 번째 모의데이터 생성기법은 현장시험 데이터의 활용방안을 검토하여 수집된 과거사고 자료를 기반으로 모의사고 데이터를 생성하는 방법론을 설명하였다. 이를 통해 실제 사고가 발생하였을 경우 상수도시스템에 미치는 특성을 반영한 모의사고 데이터를 구축할 수 있다. 이는 관망해석 모형만을 이용한 방법론의 한계점을 보완하지만, 사고의 발생위치가 고정적이라는 한계를 갖고 있다. 따라서, 앞서 설명한 방법론의 한계점을 보완하기 위해 본 연구에서는 상수도시스템 수리해석 모형 및 현장시험 데이터를 모두 활용한 모의데이터 생성기법을 제안하였다. 제안된 기법은 실제 발생한 사고의 특성 및 여러 경우의 시나리오(상이한 사고의 위치 및 크기)를 고려한 모의사고 데이터 생성이 가능하다.
향후 연구에서는 본 연구에서 제안한 모의데이터 생성기법의 성능향상을 위해 몇 가지 개선사항을 제안한다. 우선 해당 방법론은 실시간으로 계측된 데이터를 관망해석 모형에 쓰기 때문에 신속하게 모형을 검⋅보정할 수 있는 최적화 알고리즘이 필요하다. 또한, 오⋅결측치가 발생할 확률을 시간에 따라 상이하게 설정하여 실측데이터가 갖는 연속성의 문제를 반영하여 모의사고 데이터를 생성할 수 있다. 마지막으로, 본 연구에서는 압력계의 데이터를 위주로 분석을 수행하였지만, 대수용가 스마트미터 데이터(e.g., advanced metering infrastructure; AMI)를 활용하여 각 방법론을 향상시킬 수 있다. 추후에 ICT 기술 및 스마트미터기반으로 운영되는 상수도시스템의 운영관리 현황화면에 관 파손사고의 여부 및 크기가 자동적으로 표출하도록 고도화될 수 있다. 이를 통해 사고의 영향이 미치는 지역의 확산 경로를 시각적으로 확인 가능하다. 또한, 지도적 표출을 통해 사고를 미리 방지할 수 있다.




