



1. м„ң лЎ
мөңк·ј кё°нӣ„ліҖнҷ”лЎң мқён•ҙ нҸӯм—ј, 집мӨ‘нҳёмҡ° л“ұ к·№н•ңкё°мғҒнҳ„мғҒмқҳ мҰқк°ҖлЎң л§ҺмқҖ н”јн•ҙк°Җ л°ңмғқн•ҳкі мһҲмңјл©°, нҷҚмҲҳлЎң мқён•ң н”јн•ҙлҸ„ мҰқк°Җн•ҳмҳҖлӢӨ. 2020л…„м—җлҠ” м „м„ёкі„м ҒмңјлЎң м§ҖлӮң 20л…„(2000~2019л…„)кіј 비көҗн•ҳмҳҖмқ„ л•Ң нғңн’ҚмқҖ 26% мҰқк°Җн•ң 127кұҙ, нҷҚмҲҳлҠ” 23% мҰқк°Җн•ң 201кұҙмқҙ л°ңмғқн•ҳмҳҖлӢӨ(CRED, 2020). нҠ№нһҲ 1мӣ”м—җлҠ” мқёлҸ„л„ӨмӢңм•„ мһҗм№ҙлҘҙнғҖм—җм„ң м•Ҫ 400 mmмқҳ 집мӨ‘нҳёмҡ°к°Җ л°ңмғқн•ҳм—¬, 66лӘ…мқҙ мӮ¬л§қн•ҳкі , 6л§ҢлӘ…мқҳ мқҙмһ¬лҜјмқҙ л°ңмғқн•ҳмҳҖлӢӨ. лҳҗн•ң мқјліём—җм„ңлҠ” мһҘл§Ҳм „м„ мҳҒн–ҘмңјлЎң 1,300 mmк°Җ л„ҳлҠ” к°•мҡ°лЎң мқён•ҙ м•Ҫ 80м—¬лӘ…мқҙ мӮ¬л§қн•ҳмҳҖмңјл©°, мӨ‘көӯм—җм„ңлҸ„ мһҘл§ҲмҷҖ нғңн’ҚмңјлЎң мқён•ң 4м°ЁлЎҖмқҳ нҷҚмҲҳлЎң мҙқ 397лӘ…мқҙ мӮ¬л§қн•ҳкі м•Ҫ 1,430л§ҢлӘ…мқҳ н”јн•ҙк°Җ л°ңмғқн•ҳмҳҖлӢӨ.
мҡ°лҰ¬лӮҳлқјм—җм„ңлҸ„ 집мӨ‘нҳёмҡ°, нғңн’ҚмңјлЎң мқён•ҙ н•ҙл§ҲлӢӨ л§ҺмқҖ н”јн•ҙк°Җ л°ңмғқн•ҳкі мһҲмңјл©°, н–Ҙнӣ„ кё°нӣ„ліҖнҷ”м—җ л”°лҘё к·№лӢЁм Ғ к°•мҡ° нҳ„мғҒмқ„ к°ҖмҶҚнҷ” лҗ кІғмңјлЎң м „л§қлҗңлӢӨ. мҡ°лҰ¬лӮҳлқј м—°нҸүк· к°•мҲҳлҹүмқҖ м§ҖлӮң 100л…„ лҸҷм•Ҳ 108 mm мҰқк°Җн•ҳмҳҖкі , 2100л…„к№Ңм§Җ к·ё 2л°°мқё 216 mmк°Җ лҚ” мҰқк°Җн• кІғмңјлЎң мҳҲмёЎн•ҳкі мһҲлӢӨ. лҳҗн•ң к°•н•ң к°•мҲҳлҠ” мҰқк°Җн•ҳкі м•Ҫн•ң к°•мҡ°лҠ” к°җнҳён•ҳлҠ” нҳ„мғҒмңјлЎң к·№лӢЁм Ғмқё к°•мҡ°лҘј лӮҳнғҖлӮҙлҠ” м§ҖмҲҳмқё 5мқј мөңлӢӨк°•мҡ°лҹү, к°•мҡ°к°•лҸ„мқҳ мҰқк°Җк°Җ мҳҲмғҒлҗңлӢӨ(Korea Meteorological Administration, 2021). 2020л…„м—җлҠ” 1973л…„ мқҙнӣ„ к°ҖмһҘ кёҙ мһҘл§Ҳ(мӨ‘л¶Җ кё°мӨҖ 54мқј)мҷҖ н•Ёк»ҳ 8~9мӣ” м—°мқҙмқҖ 4к°ң нғңн’Қмқҳ мҳҒн–ҘмңјлЎң 1мЎ° 3,585м–өмӣҗмқҳ мһ¬мӮ°н”јн•ҙмҷҖ 46лӘ…мқҳ мқёлӘ…н”јн•ҙк°Җ л°ңмғқн•ҳмҳҖмңјл©°, мқҙлҠ” мөңк·ј 10л…„(2010~2019) м—°нҸүк· н”јн•ҙ(мһ¬мӮ° 3,883м–өмӣҗ, мқёлӘ… 14лӘ…) лҢҖ비 м•Ҫ 3л°°лҘј мҙҲкіјн•ҳлҠ” мҲҳм№ҳмқҙлӢӨ(Korea Meteorological Administration, 2021).
н–үм •м•Ҳм „л¶Җ көӯк°Җмһ¬лӮңкҙҖлҰ¬м •ліҙмӢңмҠӨн…ң(Natural Disaster Management System, NDMS)м—җм„ңлҠ” 2020л…„ нғңн’Қ, нҳёмҡ° л“ұ 16кұҙ мһ¬н•ҙлЎң мҙқ 3,223кұҙмқҳ м№ЁмҲҳн”јн•ҙк°Җ л°ңмғқн•ҳмҳҖлӢӨ. нҠ№нһҲ, лҸ„мӢңм§Җм—ӯм—җм„ңлҠ” м Җм§ҖлҢҖ, м§Җн•ҳм°ЁлҸ„, мҡ°мҲҳкҙҖ м—ӯлҘҳ, л°°мҲҳнҺҢн”„мһҘ лҜёмһ‘лҸҷ л“ұмңјлЎң мқён•ҙ м№ЁмҲҳк°Җ л°ңмғқн•ҳмҳҖлӢӨ. мқҙлҠ” лҸ„мӢңм№ЁмҲҳк°Җ м§ҖмҶҚмӢңк°„ 1~2мӢңк°„ мқҙлӮҙ лӢЁмӢңк°„ 집мӨ‘нҳёмҡ°м—җ мқҳн•ҙ л°ңмғқн•ҳм—¬ мӢ мҶҚн•ң лҢҖмқ‘ л°Ҹ м •нҷ•н•ң мҳҲмёЎмқҙ м–ҙл өкё° л•Ңл¬ёмқҙлӢӨ.
лҸ„мӢңм№ЁмҲҳ мҳҲмёЎмқ„ мң„н•ҙ м„ңмҡёмӢңм—җм„ңлҠ” м№ЁмҲҳмҳҲмёЎмӢңмҠӨн…ңмқ„ к°ңл°ңн•ҳм—¬ 2м°Ёмӣҗ м№ЁмҲҳн•ҙм„қмқ„ нҶөн•ҙ к°•мҡ°лҹүкіј м§ҖмҶҚмӢңк°„м—җ л”°лқј 80к°ңмқҳ мӢңлӮҳлҰ¬мҳӨлҘј мһ‘м„ұн•ҳм—¬ м№ЁмҲҳлҘј мҳҲмёЎн•ҳкі мһҲмңјл©°, н•ңкөӯкіјн•ҷкё°мҲ м •ліҙм—°кө¬мӣҗ(KISTI)м—җм„ңлҠ” мқёмІңмӢң м „мІҙ л°°мҲҳ분кө¬лҘј лҢҖмғҒмңјлЎң 2м°Ёмӣҗ м№ЁмҲҳн•ҙм„қмқ„ нҶөн•ҙ 20м—¬мў…мқҳ мӢңлӮҳлҰ¬мҳӨлҘј мғқмӮ°н•ҳм—¬ м№ЁмҲҳмҳҲмёЎм—җ нҷңмҡ©н•ҳкі мһҲлӢӨ. вҖҳSWMM мқҙмӨ‘л°°мҲҳлӘЁнҳ•(1D-1D) кё°л°ҳ мӢӨмӢңк°„ лҸ„мӢңм№ЁмҲҳ мҳҲмёЎ(Jang et al., 2020)вҖҷм—җм„ңлҠ” мӢӨмӢңк°„ лҸ„мӢңм№ЁмҲҳ мҳҲмёЎмқ„ мң„н•ҙ л№ лҘё мҳҲмёЎмқҙ к°ҖлҠҘн•ң SWMM 1D-1D лӘЁнҳ•мқ„ мӮ¬мҡ©н•ҳмҳҖмңјл©°, вҖҳл ҲмқҙлҚ” мҳҲмёЎк°•мҡ°лҘј нҷңмҡ©н•ң лҸ„мӢңм№ЁмҲҳмҳҲмёЎ(Yoon et al., 2014)вҖҷм—җм„ңлҠ” мҳҲмёЎк°•мҡ°мҷҖ SWMM лӘЁнҳ•мқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. вҖҳLSTM лӘЁнҳ•кіј лЎңм§ҖмҠӨнӢұ нҡҢк·ҖлҘј нҶөн•ң лҸ„мӢң м№ЁмҲҳ лІ”мң„мқҳ мҳҲмёЎ(Kim et al., 2020)вҖҷм—җм„ңлҠ” SWMM мң м¶ң лӘЁмқҳ кІ°кіјлҘј нҷңмҡ©н•ҳм—¬, н•ҙлӢ№мң м—ӯмқҳ м№ЁмҲҳлІ”мң„лҘј мҳҲмёЎн•ҳмҳҖлӢӨ. мқҙмҷҖ к°ҷмқҙ мөңк·ј лҸ„мӢңм№ЁмҲҳ мҳҲмёЎмқ„ мң„н•ҙ л“ұ л§ҺмқҖ м—°кө¬к°Җ мқҙлЈЁм–ҙм§Җкі мһҲмңјлӮҳ, лҢҖл¶Җ분 SWMM л“ұ н”„лЎңк·ёлһЁмқ„ мқҙмҡ©н•ң кҙҖл§қн•ҙм„қ, м§Җн‘ңмң м¶ң л“ұ мҲҳм№ҳн•ҙм„қмқ„ нҶөн•ң м—°кө¬к°Җ лҢҖл¶Җ분мқҙлӢӨ. к·ёлҹ¬лӮҳ мқҙмҷҖ к°ҷмқҖ л°©лІ•мқҖ м „көӯмқ„ лҢҖмғҒмңјлЎң м Ғмҡ©н•ҳкё°м—җлҠ” н•ңкі„к°Җ мһҲмңјл©°, л№ лҘҙкІҢ ліҖнҷ”н•ҳлҠ” лҸ„мӢңмң м—ӯмқҳ нҠ№м„ұмқ„ мҲҳмӢңлЎң л°ҳмҳҒн•ҳлҠ” кІғ лҳҗн•ң л§Өмҡ° м–ҙл Өмҡҙ мһ‘м—…мқҙлӢӨ.
м„ н–үм—°кө¬ вҖҳм§Җм—ӯлі„ мЈјмҡ” мһ¬лӮңлҢҖмқ‘ мӢңлӮҳлҰ¬мҳӨ л°Ҹ кё°мҲ к°ңл°ңвҖҷм—җм„ңлҠ” м№ЁмҲҳн”јн•ҙмқҙл Ҙкіј к°•мҡ°мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ нҶөкі„кё°л°ҳмқҳ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мӮ°м • л°©лІ•мқ„ м ңмӢңн•ҳмҳҖмңјл©°, мң м—ӯнҠ№м„ұмһҗлЈҢмҷҖ м№ЁмҲҳ мң„н—ҳкё°мӨҖкіјмқҳ кҙҖкі„лҘј нҶөн•ҙ Neuro-Fuzzy м•Ңкі лҰ¬мҰҳмқ„ мқҙмҡ©н•ң мҳҲмёЎ лӘЁлҚёмқ„ к°ңл°ңн•ҳмҳҖлӢӨ(National Disaster Management Research Institute, 2014; 2015; 2016; 2017). лҳҗн•ң мҙҲкё°нҷ” н•ЁмҲҳ л°Ҹ н•ҷмҠөмһҗлЈҢ кө¬м„ұм—җ л”°лҘё мҳҒн–Ҙмқ„ 분м„қн•ҳкі лӘЁлҚёмқ„ к°ңм„ н•ҳмҳҖлӢӨ(Kang et al., 2020).
к·ёлҹ¬лӮҳ мөңк·ј мқёкіөм§ҖлҠҘ кё°мҲ мқҳ л°ңлӢ¬лЎң лӢӨм–‘н•ң л”Ҙлҹ¬лӢқ л°Ҹ лЁёмӢ лҹ¬лӢқ м•Ңкі лҰ¬мҰҳмқҳ нҷңмҡ©лҸ„мҷҖ мҳҲмёЎ м •нҷ•м„ұмқҙ н–ҘмғҒлҗЁм—җ л”°лқј лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎм—җ м Ғмҡ©н•ҳкі мһҗ н•ңлӢӨ. л”°лқјм„ң ліё м—°кө¬м—җм„ңлҠ” Artificial Neural Network (ANN) м•Ңкі лҰ¬мҰҳмқ„ мқҙмҡ©н•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎн•ҳкі , н•ҷмҠөмһҗлЈҢмқҳ нҷ•мһҘ кё°лІ• м Ғмҡ©мқ„ нҶөн•ң мҳҒн–Ҙмқ„ 분м„қн•ҳм—¬ мҳҲмёЎ м •нҷ•м„ұмқ„ н–ҘмғҒмӢңнӮӨкі мһҗ н•ңлӢӨ.
2. м—°кө¬лӮҙмҡ© л°Ҹ л°©лІ•
лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎмқ„ мң„н•ҙ Artificial Neural Network (ANN) м•Ңкі лҰ¬мҰҳмқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. ANNмқҖ мқёк°„мқҳ лҮҢлҘј лӘЁл°©н•ҳм—¬ мқёк°„мқҳ мӮ¬кі л°©мӢқмқ„ м»ҙн“Ён„°м—җ н•ҷмҠөмӢңнӮӨлҠ” м•Ңкі лҰ¬мҰҳмңјлЎң лҮҢмқҳ кё°ліёлӢЁмң„мқё лүҙлҹ°мқҖ м—°кІ°лҗң лүҙлҹ°л“ӨлЎңл¶Җн„° м •ліҙлҘј л°ӣм•„ кі мң н•ң л°©мӢқмңјлЎң мІҳлҰ¬н•ҳкі , к·ё кІ°кіјлҘј лӢӨлҘё лүҙлҹ°м—җ м „лӢ¬н•ҳлҠ” лҮҢмқҳ кұ°лҢҖн•ң мғқл¬јн•ҷм Ғ л„ӨнҠёмӣҢнҒ¬ кө¬мЎ°лҘј лӘЁл°©н•ҳм—¬ мЈјм–ҙ진 л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ л§Ңл“Өм–ҙ진 м•Ңкі лҰ¬мҰҳмқҙлӢӨ. лүҙлҹ°мқҳ кё°лҠҘмқ„ м»ҙн“Ён„°м—җм„ң мһ¬нҳ„н•ҳкё° мң„н•ҙ Fig. 1кіј к°ҷмқҙ мІ« лІҲм§ё мёөмқё мһ…л Ҙмёө(Input layer)мңјлЎң л“Өм–ҙмҳЁnк°ңмқҳ лҚ°мқҙн„°лҘј к°Ғ лүҙлҹ°м—җм„ң нҠ№м • к°ҖмӨ‘м№ҳлҘј кіұн•ң нӣ„ н•©н•ҳм—¬ лӢӨмқҢ лүҙлҹ°кіј мқҖлӢүмёө(Hidden layer)лЎң мқҙлҸҷмӢңнӮӨл©°, л§Ҳм§Җл§ү мёөмқё м¶ңл Ҙмёө(Output layer)мқҳ лүҙлҹ°м—җм„ң кІ°кіјлҘј м¶ңл Ҙн•ңлӢӨ.
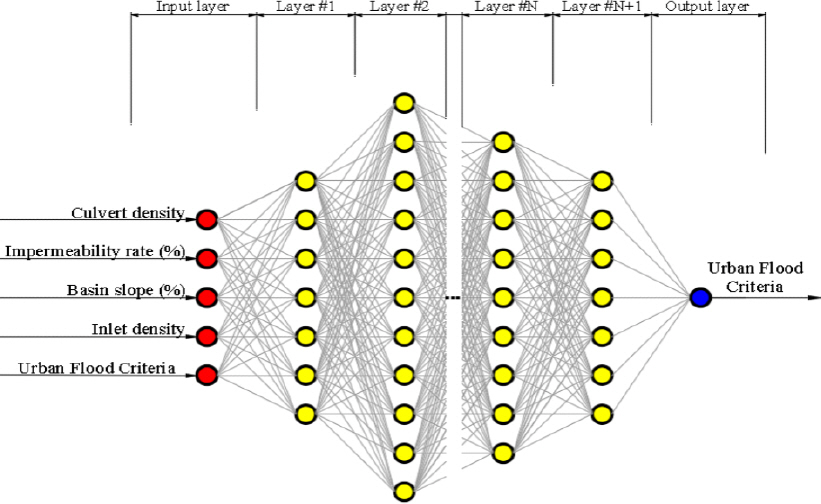
ліё м—°кө¬м—җм„ңлҠ” мһ…л ҘліҖмҲҳлЎң л¶ҲнҲ¬мҲҳмңЁ(Impermeability rate), мң м—ӯкІҪмӮ¬(Basin slope), кҙҖкұ°л°ҖлҸ„(Culvert density), л№—л¬јл°ӣмқҙ л°ҖлҸ„(Inlet density)лҘј мӮ¬мҡ©н•ҳмҳҖмңјл©°, кІ°кіјліҖмҲҳлЎң кіјкұ° м№ЁмҲҳн”јн•ҙмқҙл Ҙкё°л°ҳ мң„н—ҳкё°мӨҖ мӮ°м • кІ°кіјк°’мқ„ мӮ¬мҡ©н•ҳм—¬ мҙқ 315к°ңмқҳ Training Data Set AлҘј кө¬м¶•н•ҳмҳҖлӢӨ.
мһ…л ҘліҖмҲҳлҠ” м„ н–үм—°кө¬м—җм„ң лҸ„мӢңмң м¶ң нҠ№м„ұм—җ мҳҒн–Ҙмқ„ мЈјлҠ” ліҖмҲҳл“Өм—җ лҢҖн•ң мғҒкҙҖ분м„қ л°Ҹ лҜјк°җлҸ„ 분м„қмқ„ нҶөн•ҙ м„ м •лҗң мң м—ӯнҠ№м„ұмқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. л¶ҲнҲ¬мҲҳмңЁмқҖ нҷҳкІҪл¶Җ нҷҳкІҪкіөк°„м •ліҙм„ң비мҠӨм—җм„ң м ңкіөн•ҳлҠ” 2018л…„ нҶ м§Җн”јліөлҸ„лҘј мқҙмҡ©н•ҳм—¬ мӮ°м •н•ҳмҳҖмңјл©°, мң м—ӯкІҪмӮ¬лҠ” көӯнҶ л¶Җ көӯнҶ м •ліҙн”Ңлһ«нҸјм—җм„ң м ңкіөн•ҳлҠ” 2014л…„ Digital Elevation Model (DEM), кҙҖкұ°л°ҖлҸ„мҷҖ л№—л¬јл°ӣмқҙ л°ҖлҸ„лҠ” к°Ғ м§ҖмһҗмІҙлі„лЎң мҲҳ집н•ң м§Җн•ҳмӢңм„Өл¬ј мһҗлЈҢлҘј мқҙмҡ©н•ҳмҳҖмңјл©°, GIS 분м„қмқҖ QGISлҘј мӮ¬мҡ©н•ҳм—¬ 분м„қн•ҳмҳҖлӢӨ.
кІ°кіјліҖмҲҳмқё кіјкұ° м№ЁмҲҳн”јн•ҙмқҙл Ҙкё°л°ҳ мң„н—ҳкё°мӨҖмқҖ м„ н–үм—°кө¬(National Disaster Management Research Institute, 2014; 2015; 2016; 2017)м—җм„ң м ңмӢңн•ң н”јн•ҙмқҙл Ҙкё°л°ҳ н•ңкі„к°•мҡ°лҹү мӮ°м • л°©лІ•мқ„ мқҙмҡ©н•ҳм—¬ мӮ°м •н•ҳмҳҖмңјл©°, 2013~2019л…„ лҸҷм•Ҳмқҳ м№ЁмҲҳн”јн•ҙмқҙл Ҙкіј к°•мҡ°мһҗлЈҢлҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ. м—¬кё°м„ң, м№ЁмҲҳ мң„н—ҳкё°мӨҖмқҖ м№ЁмҲҳк°Җ л°ңмғқ(м•Ҫ 20 cm м •лҸ„)н–Ҳмқ„ л•Ңмқҳ к°•мҡ°лҹүмңјлЎң м •мқҳн•ҳмҳҖлӢӨ. м№ЁмҲҳн”јн•ҙмһҗлЈҢлҠ” н–үм •м•Ҳм „л¶Җ көӯк°Җмһ¬лӮңкҙҖлҰ¬мӢңмҠӨн…ңм—җ л“ұлЎқлҗң мһҗлЈҢлҘј мӮ¬мҡ©н•ҳмҳҖмңјл©°, к°•мҡ°мһҗлЈҢлҠ” кё°мғҒмІӯм—җм„ң м ңкіөн•ҳлҠ” ASOS, AWS, AMOS 545к°ң кҙҖмёЎмҶҢмқҳ 1분 лӢЁмң„ к°•мҡ° кҙҖмёЎлҚ°мқҙн„°лҘј мҲҳ집н•ҳм—¬ 10분, 30분, 60분, 180분, 360분, 720분 м§ҖмҶҚмӢңк°„м—җ лҢҖн•ң мөңлҢҖлҲ„м Ғк°•мҡ°лҹүмқ„ 분м„қн•ҳмҳҖлӢӨ.
Training Data Set Aмқҳ мқјл¶ҖлҘј Table 1м—җ лӮҳнғҖлӮҙм—Ҳмңјл©°, мһ…л ҘліҖмҲҳмқҳ лІ”мң„лҠ” л¶ҲнҲ¬мҲҳмңЁ 1.31~100.0 мң м—ӯкІҪмӮ¬ 0.0~48.96, кҙҖкұ°л°ҖлҸ„ 0.000003~0.052182, л№—л¬јл°ӣмқҙ л°ҖлҸ„ 0.0000001~ 0.0055238мқҙлӢӨ.
TableВ 1
Training Data Set A
Training Data Set AлҘј ANN м•Ңкі лҰ¬мҰҳм—җ м Ғмҡ©н•ҳм—¬ Model AлҘј к°ңл°ңн•ҳмҳҖмңјл©°, көҗм°ЁкІҖмҰқмқ„ нҶөн•ҙ лӘЁлҚёмқ„ нҸүк°Җн•ҳмҳҖлӢӨ. лӢӨмқҢмңјлЎң н•ҷмҠөмһҗлЈҢ нҷ•мһҘмқ„ мң„н•ҙ Fig. 2мҷҖ к°ҷмқҙ Model Aмқҳ мҳҲмёЎ кІ°кіјлҘј кІҖмҰқн•ҳм—¬ Training Data Set BлҘј кө¬м¶•н•ҳкі мқҙлҘј нҷңмҡ©н•ҙ Model BлҘј к°ңл°ңн•ҳмҳҖмңјл©°, л§Ҳм§Җл§үмңјлЎң Model AмҷҖ Bмқҳ мҳҲмёЎм„ұлҠҘмқ„ 비көҗн•ҳм—¬ н•ҷмҠөмһҗлЈҢ нҷ•мһҘм—җ л”°лҘё мҳҒн–Ҙмқ„ 분м„қн•ҳмҳҖлӢӨ.

мҳҲмёЎ м„ұлҠҘ нҸүк°ҖлҘј мң„н•ң кІҖмҰқл°©лІ•мңјлЎңлҠ” K-fold көҗм°ЁкІҖмҰқ л°©лІ•мқ„ мқҙмҡ©н•ҳмҳҖлӢӨ. K-foldлҠ” м „мІҙ лҚ°мқҙн„°лҘј kк°ңмқҳ 집합мңјлЎң лӮҳлҲ„м–ҙ k-1к°ңмқҳ 집합мқ„ н•ҷмҠөмһҗлЈҢлЎң мӮ¬мҡ©н•ҳкі лӮҳлЁём§Җ 1к°ңмқҳ 집합мқ„ кІҖмҰқлҚ°мқҙн„°лЎң мӮ¬мҡ©н•ҳлҠ” л°©лІ•мқ„ мҲңм°Ём ҒмңјлЎң л°ҳліөн•ҳм—¬ нҸүк°Җн•ҳлҠ” л°©лІ•мңјлЎң, лӘЁл“ лҚ°мқҙн„°к°Җ н•ҷмҠө л°Ҹ кІҖмҰқмһҗлЈҢлЎң мӮ¬мҡ©лҗҳл©° кіјм Ғн•©мқҙ мқјм–ҙлӮ нҷ•лҘ мқҙ лӮ®лӢӨ. ліё м—°кө¬м—җм„ңлҠ” foldмқҳ к°ңмҲҳлҘј 10к°ңлЎң н•ҳм—¬ к°Ғк°Ғмқҳ лӘЁлҚём—җ лҢҖн•ң мҳҲмёЎ кІ°кіјлҘј нҶөн•©н•ҳм—¬ м ңмӢңн•ҳмҳҖмңјл©°, лӘЁлҚё м„ұлҠҘмқҖ Eqs. (1)~(3)лҘј мқҙмҡ©н•ҳм—¬ нҸүк· м ҲлҢҖмҳӨм°Ё(Mean Absolute Error, MAE), нҸүк· м ңкіұк·јмҳӨм°Ё(Root Mean Square Error, RMSE), нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё(Mean Absolute Percentage Error, MAPE)лҘј 비көҗн•ҳмҳҖлӢӨ.
м—¬кё°м„ң, yлҠ” мӢӨм ңк°’, yМӮлҠ” мҳҲмёЎк°’, yМ„лҠ” мӢӨм ңк°’мқҳ нҸүк· , yМӮМ„лҠ” мҳҲмёЎк°’мқҳ нҸүк· , nмқҖ мң„н—ҳкё°мӨҖ к°ңмҲҳмқҙлӢӨ.
3. лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚё к°ңл°ң
ANN м•Ңкі лҰ¬мҰҳмқ„ мӮ¬мҡ©н•ҳкё° мң„н•ҙ TensorflowмҷҖ KerasлҘј м Ғмҡ©н•ҳмҳҖлӢӨ. TensorflowлҠ” Googleм—җм„ң к°ңл°ңн•ң кІғмңјлЎң мқҙмӢқм„ұм—җ лҶ’мқҖ мқёкіөмӢ кІҪл§қ лқјмқҙлёҢлҹ¬лҰ¬мқҙлӢӨ. нҠ№нһҲ, л”Ҙлҹ¬лӢқм—җм„ң л§Һмқҙ мӮ¬мҡ©н•ҳлҠ” лӢӨм–‘н•ң лӘЁлҚёкіј м•Ңкі лҰ¬мҰҳкіј Tensorboardк°Җ нҸ¬н•Ёлҗҳм–ҙ мһҲм–ҙ 분м„қкІ°кіјлҘј Data Flow Graph (DFG)лЎң н‘ңнҳ„н• мҲҳ мһҲлӢӨ. KerasлҠ” нҢҢмқҙмҚ¬мқ„ мқҙмҡ©н•ҳм—¬ мһ‘м„ұлҗң мӢ кІҪл§қ кё°л°ҳмқҳ мҳӨн”ҲмҶҢмҠӨ лқјмқҙлёҢлҹ¬лҰ¬мқҙл©°, Deeplearning4j, Tensorflow, Microsoft Cognitive Toolkit л°Ҹ Theanoм—җм„ң мӮ¬мҡ©н• мҲҳ мһҲлӢӨ. KerasлҠ” мӢ кІҪл§қкіј л№ лҘё кі„мӮ°мқҙ к°ҖлҠҘн•ҳлҸ„лЎқ м„Өкі„лҗҳм—Ҳмңјл©°, лӘЁл“Ҳ л°©мӢқмңјлЎң нҷ•мһҘм„ұмқҙ лҶ’лӢӨ. лҳҗн•ң, Tensorflowм—җм„ң мһ‘лҸҷн•ҳлҠ” кІғмңјлЎң нҢҢлқјлҜён„° м„Өм •мқҙлӮҳ мӢ кІҪл§қ кө¬мЎ°лҘј к°„лӢЁн•ҳкІҢ м„Өкі„н• мҲҳ мһҲлӢӨ.
м•Ңкі лҰ¬мҰҳ л§Өк°ңліҖмҲҳмқё dropout rate, kernel л°Ҹ biasмқҳ мҙҲкё°к°’ л“ұмқ„ Table 2мҷҖ к°ҷмқҙ м„Өм •н•ҳмҳҖлӢӨ. dropout 비мңЁмқҖ лӘЁлҚёмқҳ кіјм Ғн•©мқ„ л°©м§Җн•ҳкё° мң„н•ҙ н•ҷмҠөмӢң мһ„мқҳмқҳ 비мңЁл§ҢнҒј лүҙлҹ°мқ„ м ңмҷён•ҳм—¬ н•ҷмҠөмӢңнӮӨкё° мң„н•ң ліҖмҲҳмқҙл©°, Kernel л°Ҹ biasмқҳ мҙҲкё°к°’мқҖ к·ёлһҳл””м–ёнҠё мҶҢл©ёкіј нҸӯл°ңл¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙм„ңмқҙлӢӨ. мң„ м„ёк°Җм§Җ л§Өк°ңліҖмҲҳлҘј ліҖкІҪн•ҙк°Җл©° мөңм Ғмқҳ м§ҖмҶҚмӢңк°„лі„ н•ңкі„к°•мҡ°лҹүмқ„ м¶”м •н•ҳмҳҖлӢӨ. ANNмқ„ мқҙмҡ©н•ҳм—¬ н•ңкі„к°•мҡ°лҹүмқ„ м¶”м •н•ҳкё° мң„н•ң нҷңм„ұнҷ” н•ЁмҲҳлЎң Rectified Linear Unit (ReLU)лҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ. нҷңм„ұнҷ” н•ЁмҲҳлҠ”(Activation Function)лҠ” л…ёл“ңм—җ мһ…л Ҙлҗң к°’л“Өмқ„ л№„м„ нҳ• н•ЁмҲҳм—җ нҶөкіјмӢңнӮЁ нӣ„ лӢӨмқҢ л Ҳмқҙм–ҙлЎң м „лӢ¬н•ҳлҠ”лҚ° мӮ¬мҡ©лҗҳлҠ” н•ЁмҲҳлҘј мқҳлҜён•ңлӢӨ(ReniewвҖҷs blog CS and deep learning, 2018). ReLU мҷём—җ Sigmoid, Tanh л“ұ лӢӨм–‘н•ң нҷңм„ұнҷ” н•ЁмҲҳк°Җ мһҲм§Җл§Ң лҢҖл¶Җ분мқҳ н•ЁмҲҳл“Өмқҙ 0.0~Вұ1.0 мӮ¬мқҙк°’мқ„ м¶ңл Ҙн•ҳл©°, н•ҷмҠөмқҙ 진н–үлҗҳл©ҙм„ң 1.0 мқҙн•ҳмқҳ к°’мқҙ л°ҳліөн•ҳм—¬ кіұн•ҙм§Җл©ҙ 0м—җ мҲҳл ҙн• к°ҖлҠҘм„ұмқҙ мһҲкё° л•Ңл¬ём—җ ReLUлҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ. ReLUлҠ” мһ…л Ҙк°’мқҙ 0 мқҙмғҒмқҙл©ҙ мһ…л Ҙлҗң к°’мқ„ м¶ңл Ҙн•ҳкі 0 мқҙн•ҳмқҳ к°’мқҖ 0мңјлЎң л°ҳнҷҳн•ңлӢӨ(Saito, 2019). мҶҗмӢӨн•ЁмҲҳлҠ” к°ҖлҠҘн•ң мһ‘мқҖ к°’мқ„ к°Җм§Ҳ мҲҳ мһҲлҸ„лЎқ л§Ңл“ңлҠ” мөңм Ғнҷ” н•ЁмҲҳлҠ” Momentumкіј AdaGrad (Adaptive Gradient)к°Җ нҳјн•©лҗң л°©лІ•мқё Adam н•ЁмҲҳлҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ. MomentumмқҖ кІҪмӮ¬н•ҳк°•мқ„ нҶөн•ҙ мөңм Ғк°’мңјлЎң мқҙлҸҷн•ҳлҠ” кіјм •мқ„ лҚ”мҡұ л№ лҘҙкІҢ н•ҙмЈјл©°, AdaGradлҠ” ліҖмҲҳл“Өмқ„ к°ұмӢ н• л•Ң ліҖмҲҳл§ҲлӢӨ Step sizeлҘј лӢӨлҘҙкІҢ м„Өм •н•ҙм„ң мөңм Ғк°’мңјлЎң мқҙлҸҷн•ҳлҠ” л°©мӢқмқҙлӢӨ. мөңлҢ“к°’кіј мөңмҶҹк°’мқҳ лІ”мң„лҘј 10мқҳ кұ°л“ӯм ңкіұмңјлЎң м Ғмҡ©н•ҳм—¬, лүҙлҹ°мқҳ к°ңмҲҳлҠ” мёөлі„ 5к°ң, 10к°ң, мқҖлӢүмёөмқҳ мҲҳлҠ” 2~3мёө, л§Өк°ңліҖмҲҳлі„ мЎ°кұҙмқҖ 625к°ңлЎң мҙқ 2,500к°ңмқҳ н•ҷмҠөмЎ°кұҙмқ„ м„Өм •н•ҳмҳҖлӢӨ.
TableВ 2
ANN Algorithm Parameter
ANN м•Ңкі лҰ¬мҰҳм—җ кө¬м¶•лҗң Training Data Set AлҘј м Ғмҡ©н•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎмқ„ мң„н•ң Model AлҘј к°ңл°ңн•ҳмҳҖмңјл©°, лӘЁлҚё м„ұлҠҘнҸүк°Җ кІ°кіјлҠ” Table 3кіј к°ҷмқҙ м§ҖмҶҚмӢңк°„лі„лЎң нҸүк· м ҲлҢҖмҳӨм°ЁлҠ” 2.97~7.05 mm, нҸүк· м ңкіұк·јмҳӨм°ЁлҠ” 3.39~9.80 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°ЁлҠ” 7.07~8.31%лЎң 분м„қлҗҳм—ҲлӢӨ.
4. н•ҷмҠөмһҗлЈҢ нҷ•мһҘм—җ л”°лҘё мҳҒн–Ҙ 분м„қ
4.1 н•ҷмҠөмһҗлЈҢмқҳ нҷ•мһҘ
Model AлҘј нҶөн•ҙ мҳҲмёЎлҗң кІ°кіјлҘј кІҖмҰқн•ҳм—¬ лӢӨмӢң н•ҷмҠөмһҗлЈҢлЎң мӮ¬мҡ©н•ҳлҠ” л°©лІ•мқ„ м Ғмҡ©н•ҳмҳҖмңјл©°, нҷ•мһҘлҗң н•ҷмҠөмһҗлЈҢлҘј мӮ¬мҡ©н•ҳм—¬ к°ңл°ңлҗң Model Bмқҳ м„ұлҠҘмқ„ нҸүк°Җн•ҳмҳҖлӢӨ. лЁјм Җ Model AлҘј нҶөн•ҙ мң м—ӯнҠ№м„ұмһҗлЈҢк°Җ кө¬м¶•лҗң 2,118к°ң н–үм •лҸҷм—җ лҢҖн•ң лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ҳмҳҖмңјл©°, кіјкұ° м№ЁмҲҳн”јн•ҙмҷҖ к°•мҡ°мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ кІҖвӢ…ліҙм •н•ҳм—¬ нҷ•мһҘлҗң Training Data Set BлҘј кө¬м¶•н•ҳмҳҖлӢӨ.
Table 4мқҳ мЎ°кұҙмқ„ мқҙмҡ©н•ҳм—¬ лӘЁлҚё кІ°кіјлҘј кІҖмҰқн•ҳмҳҖлӢӨ. PлҠ” мҳҲмёЎлҗң мң„н—ҳкё°мӨҖ, RmaxлҠ” н•ҙлӢ№м§Җм—ӯмқҳ н”јн•ҙк°Җ л°ңмғқн•ҳм§Җ м•ҠмқҖ мөңлҢҖк°•мҡ°лҹү, DmaxмқҖ м№ЁмҲҳн”јн•ҙк°Җ л°ңмғқн–Ҳмқ„ л•Ң мөңмҶҢк°•мҡ°лҹүмқ„ мқҳлҜён•ңлӢӨ. мҳҲмёЎлҗң мң„н—ҳкё°мӨҖмқҙ RmaxліҙлӢӨ нҒ¬кі , DmaxліҙлӢӨ мһ‘мқ„ кІҪмҡ° True, RmaxмҷҖ DmaxліҙлӢӨ нҒ° кІҪмҡ° Available, RmaxліҙлӢӨ мһ‘мқҖ кІҪмҡ° FalseлЎң нҢҗлӢЁн•ҳмҳҖлӢӨ.
TableВ 4
Verification Method of Data
| Division | Verification Method |
|---|---|
| True (T) | Dmin > P > Rmax |
| Available (A) | P > Dmin > Rmax |
| False (F) | P < Rmax |
мң„ мЎ°кұҙм—җ л”°лқјм„ң м§ҖмҶҚмӢңк°„ 30분, 60분, 180분м—җ лҢҖн•ң мң нҡЁм„ұмқ„ нҢҗлӢЁн•ҳмҳҖмңјл©°, 3к°ңмқҳ к°’ мӨ‘ 2к°ң мқҙмғҒмқҙ Trueмқё кІҪмҡ°, Trueк°Җ 1к°ң, Availableк°Җ 2к°ң лҳҗлҠ” Availableк°Җ 3к°ңмқё кІҪмҡ°м—җлҠ” н•ҷмҠөмһҗлЈҢлЎң мӮ¬мҡ©н•ҳмҳҖлӢӨ. лҳҗн•ң Available 2к°ң Falseк°Җ 1к°ңмқё кІҪмҡ°м—җлҠ” Pк°’мқ„ RmaxлЎң мҲҳм •н•ҳм—¬ лҸҷмқјн•ң л°©лІ•мңјлЎң мһ¬кІҖнҶ н•ҳмҳҖмңјл©°, мқҙмҷё мЎ°кұҙмқҖ лҚ°мқҙн„°мқҳ мӢ лў°м„ұмқ„ нҷ•ліҙн• мҲҳ м—Ҷм–ҙ н•ҷмҠөмһҗлЈҢм—җм„ң м ңмҷён•ҳмҳҖлӢӨ. н•ҷмҠөмһҗлЈҢ м Ғмҡ© к°ҖлҠҘ м—¬л¶ҖлҘј кІҖнҶ н•ң кІ°кіј Table 5мҷҖ к°ҷмқҙ 2,118к°ң мӨ‘ 818к°ң лҚ°мқҙн„°к°Җ н•ҷмҠөмһҗлЈҢлЎң мӮ¬мҡ© к°ҖлҠҘ н•ң кІғмңјлЎң 분м„қлҗҳм—ҲлӢӨ.
TableВ 5
Verification Result
Training Data Set AмҷҖ кІҖмҰқлҗң 818к°ң лҚ°мқҙн„°мқҳ к°Ғ ліҖмҲҳлҘј м§ҖмҶҚмӢңк°„лі„лЎң 비көҗн•ҳм—¬ Figs. 3~5м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. Training Data Set AмҷҖ 비көҗн•ҳм—¬ мң м—ӯнҠ№м„ұкіј н•ңкі„к°•мҡ°лҹүк°„мқҳ мғҒкҙҖм„ұмқҙ лӘ…нҷ•н•ҙм§ҖлҠ” кІғмқ„ нҷ•мқён• мҲҳ мһҲмңјл©°, мң м—ӯнҠ№м„ұкіј н•ңкі„к°•мҡ°лҹүмқҳ кҙҖкі„м—җм„ң м–‘мқҳ мғҒкҙҖкҙҖкі„лҘј ліҙмқҙкі мһҲм§Җл§Ң м§ҖмҶҚмӢңк°„ 180분м—җм„ңлҠ” кҙҖкұ°л°ҖлҸ„мҷҖ л¶ҲнҲ¬мҲҳл©ҙм ҒмқҖ мқҢмқҳ мғҒкҙҖкҙҖкі„лҘј к°Җм§ҖлҠ” кІғмқ„ нҷ•мқён• мҲҳ мһҲм—ҲлӢӨ. мқҙлҠ” кё°мЎҙ Training Data Set AмҷҖ мң мӮ¬н•ң кІҪн–Ҙмқ„ ліҙмқҙкі мһҲм–ҙ кІҖмҰқлҗң лҚ°мқҙн„°лҠ” н•ҷмҠөмһҗлЈҢлЎң нҷңмҡ© к°ҖлҠҘн•ң кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.
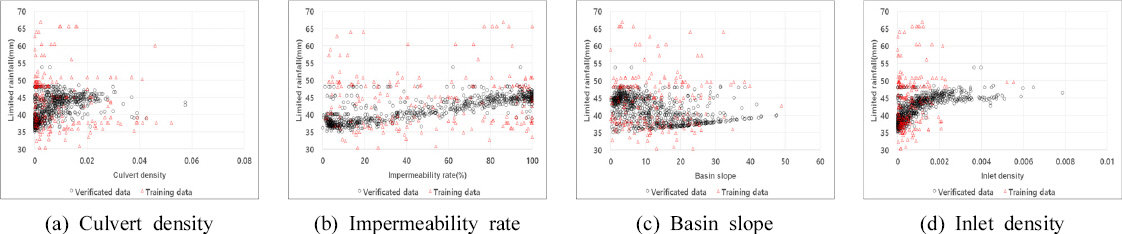
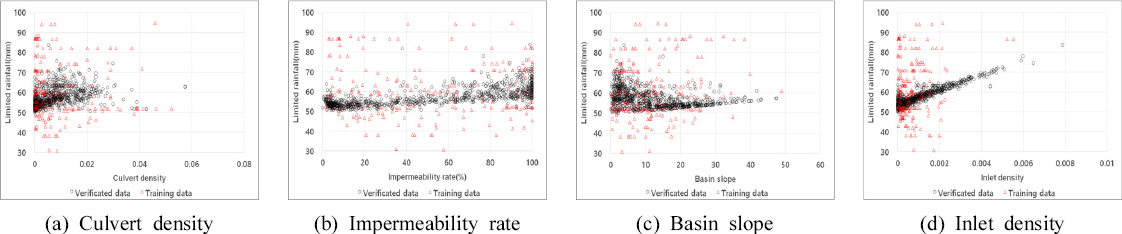
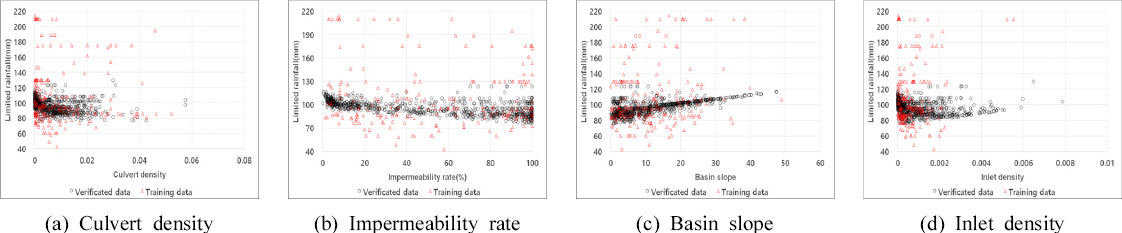
л”°лқјм„ң, кё°мЎҙ Training Data Set AмҷҖ кІҖмҰқлҗң Data 818к°ңлҘј 추к°Җн•ң Training Data Set BлҘј кө¬м¶•н•ҳмҳҖмңјл©°, Table 6м—җ мөңмҶҢ, мөңлҢҖ, нҸүк· к°’мқ„ м ңмӢңн•ҳмҳҖлӢӨ. мһ…л ҘліҖмҲҳмқҳ лІ”мң„лҠ” л¶ҲнҲ¬мҲҳмңЁ 0.04~100.0, мң м—ӯкІҪмӮ¬ 0~47.58, кҙҖкұ°л°ҖлҸ„ 0.0000003~0.0575376, л№—л¬јл°ӣмқҙ л°ҖлҸ„ 0~0.0078773мқҙлӢӨ.
TableВ 6
Training Data Set B
4.2 лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎ м„ұлҠҘ л°Ҹ мҳҒн–Ҙ нҸүк°Җ
Training Data Set BлҘј нҷңмҡ©н•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ң кІ°кіјлҘј Table 7кіј Fig. 6м—җ м ңмӢңн•ҳмҳҖлӢӨ. м§ҖмҶҚмӢңк°„ 30분м—җ лҢҖн•ң мҳҲмёЎкІ°кіјлҠ” нҸүк· м ҲлҢҖмҳӨм°Ё 1.06 mm, нҸүк· м ңкіұк·јмҳӨм°Ё 2.00 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё 2.42%лЎң лӮҳнғҖлӮҳ мҳҲмёЎ м„ұлҠҘмқҙ л§Өмҡ° мҡ°мҲҳн•ң кІғмқ„ нҷ•мқён• мҲҳ мһҲм—Ҳм§Җл§Ң н•ңкі„к°•мҡ°лҹүмқҙ лҶ’мқҖ кө¬к°„м—җм„ң кіјлҢҖ м¶”м •лҗҳлҠ” лІ”мң„к°Җ мһҲмңјл©°, м „мІҙ кө¬к°„м—җм„ң мҳҲмёЎк°’мқҙ мӢӨмёЎк°’ліҙлӢӨ лӮ®кІҢ м¶”м •лҗң кІғмқ„ нҷ•мқё н• мҲҳ мһҲм—ҲлӢӨ. м§ҖмҶҚмӢңк°„ 60분 мҳҲмёЎкІ°кіјлҠ” нҸүк· м ҲлҢҖмҳӨм°Ё 0.41 mm, нҸүк· м ңкіұк·јмҳӨм°Ё 1.03 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё 0.71%лЎң лӮҳнғҖлӮҳ м§ҖмҶҚмӢңк°„ 30분 мҳҲмёЎм„ұлҠҘліҙлӢӨ мҡ°мҲҳн•ҳмҳҖмңјл©°, мқјл¶Җ мҳҲмёЎкІ°кіјк°Җ мӢӨм ңк°’ ліҙлӢӨ лӮ®мқҖ кІғмқ„ м ңмҷён•ҳкі лҠ” л§Өмҡ° мң мӮ¬н•ң кІғмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ.
TableВ 7
Model B Prediction Performance
| Parameter | Rainfall Duration | ||
|---|---|---|---|
| 30 min | 60 min | 180 min | |
| MAE (mm) | 1.06 | 0.41 | 4.29 |
| RMSE (mm) | 2.00 | 1.03 | 6.88 |
| MAPE (%) | 2.42 | 0.71 | 4.37 |
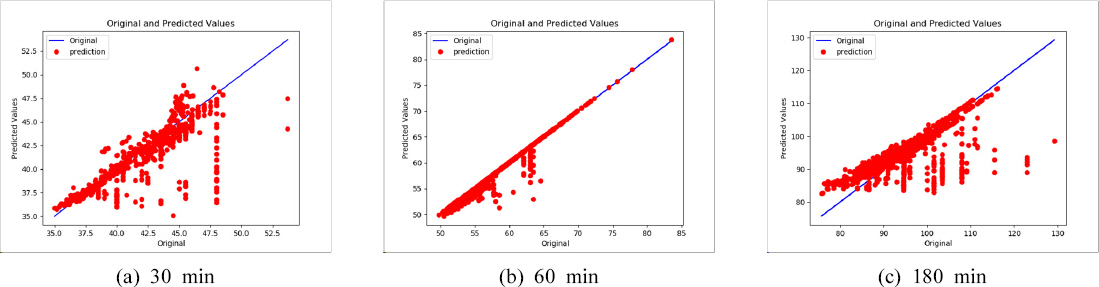
м§ҖмҶҚмӢңк°„ 180분 мҳҲмёЎкІ°кіјлҠ” нҸүк· м ҲлҢҖмҳӨм°Ё 4.29 mm, нҸүк· м ңкіұк·јмҳӨм°Ё 6.88 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё 4.37%лЎң 분м„қлҗҳм–ҙ м§ҖмҶҚмӢңк°„ 30분, 60분 кІ°кіјм—җ 비н•ҙ мҳҲмёЎм„ұлҠҘмқҙ лӮ®мқҖ кІғмңјлЎң 분м„қлҗҳм—ҲлӢӨ.
Model AмҷҖ Model Bмқҳ мҳҲмёЎ м„ұлҠҘмқ„ 비көҗн•ҳм—¬ н•ҷмҠөмһҗлЈҢ нҷ•мһҘм—җ л”°лҘё мҳҒн–Ҙмқ„ 분м„қн•ҳмҳҖмңјл©°, к·ё кІ°кіјлҘј Table 8м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. MAEлҠ” м§ҖмҶҚмӢңк°„ 30분м—җм„ң 1.90 mm, 60분 4.58 mm, 180분 2.76 mm к°җмҶҢн•ҳмҳҖмңјл©°, RMSEлҠ” к°Ғк°Ғ 1.39 mm, 4.91 mm, 2.92 mm, MAPEлҠ” 4.65%, 7.60%, 2.43% к°җмҶҢн•ҳм—¬ лӘЁлҚё м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ” кІғмңјлЎң 분м„қ лҗҳм—ҲлӢӨ. м§ҖмҶҚмӢңк°„ 60분 мҳҲмёЎкІ°кіјк°Җ мҳҲмёЎ м„ұлҠҘлҸ„ к°ҖмһҘ мўӢмқҖ кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, к°ңм„ нҡЁкіјлҸ„ к°ҖмһҘ лҶ’мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬мңјл©°, м§ҖмҶҚмӢңк°„ 180분м—җм„ң к°ңм„ нҡЁкіјк°Җ к°ҖмһҘ лӮ®мқҖ кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
TableВ 8
Improvement Effect by Training Data Augmentation
л§Ҳм§Җл§үмңјлЎң Model A, BмҷҖ м„ н–үм—°кө¬м—җм„ң к°ңл°ңлҗң Neuro-Fuzzy лӘЁлҚёмқҳ мҳҲмёЎм„ұлҠҘмқ„ 비көҗн•ҳкё° мң„н•ҙ м§ҖмҶҚмӢңк°„ 60분과 180분м—җ лҢҖн•ң нҸүк· м ңкіұк·јмҳӨм°ЁлҘј 비көҗн•ҳм—¬ Table 9м—җ лӮҳнғҖлӮҙм—ҲлӢӨ. Neuro-Fuzzy мҳҲмёЎ м„ұлҠҘкіј 비көҗн•ң кІ°кіјм—җм„ңлҸ„ нҸүк· м ңкіұк·јмҳӨм°ЁлҘј кё°мӨҖмңјлЎң Neuro-Fuzzy Model лҢҖ비 Model AлҠ” м§ҖмҶҚмӢңк°„ 60분м—җ 42.2%, 180분м—җ 46.2%, Model BлҠ” 90.0%, 62.1% к°ңм„ лҗҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ.
TableВ 9
Comparison of Model A, B and Neuro-Fuzzy Model
| Model | Number of Training Data | RMSE (mm) | Decreasing Rate (%) | ||
|---|---|---|---|---|---|
| 60 min | 180 min | 60 min | 180 min | ||
| Neuro-Fuzzy Model (Kang et al., 2020) | 118 | 10.3 | 18.2 | - | - |
| Model A | 315 | 5.95 | 9.80 | 42.2 | 46.2 |
| Model B | 1,133 | 1.03 | 6.90 | 90.0 | 62.1 |
5. кІ° лЎ
ліё м—°кө¬м—җм„ңлҠ” к°•мҡ°кё°л°ҳмқҳ м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ м„Өм •н•ҳкё° мң„н•ҙ л№„м„ нҳ•м Ғмқё кҙҖкі„лҘј к°Җм§ҖлҠ” мң м—ӯнҠ№м„ұмқ„ мқҙмҡ©н•ҳм—¬ ANN м•Ңкі лҰ¬мҰҳмқ„ мқҙмҡ©н•ң мҳҲмёЎ лӘЁлҚёмқ„ к°ңл°ңн•ҳмҳҖлӢӨ. лҳҗн•ң Training Dataк°Җ л¶ҖмЎұн•ң н•ңкі„м җмқ„ к°ңм„ н•ҳкё° мң„н•ҙ лҚ°мқҙн„° нҷ•мһҘкё°лІ•мқ„ нҶөн•ҙ лӘЁлҚёмқҳ мҳҲмёЎм„ұлҠҘмқ„ к°ңм„ н•ҳмҳҖлӢӨ.
л¶ҲнҲ¬мҲҳмңЁ, мң м—ӯкІҪмӮ¬, кҙҖкұ°л°ҖлҸ„, л№—л¬јл°ӣмқҙ л°ҖлҸ„лҘј мһ…л ҘліҖмҲҳлЎң, кіјкұ° м№ЁмҲҳн”јн•ҙмқҙл Ҙкё°л°ҳ мң„н—ҳкё°мӨҖ мӮ°м • кІ°кіјлҘј кІ°кіјліҖмҲҳлЎң мӮ¬мҡ©н•ҳм—¬ лӘЁлҚё к°ңл°ңмқ„ мң„н•ң Training Data Set AлҘј кө¬м¶•н•ҳмҳҖмңјл©°, ANN м•Ңкі лҰ¬мҰҳм—җ м Ғмҡ©н•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎмқ„ мң„н•ң Model AлҘј к°ңл°ңн•ҳмҳҖлӢӨ. K-fold көҗм°ЁкІҖмҰқмқ„ нҶөн•ҙ лӘЁлҚё м„ұлҠҘмқ„ нҸүк°Җн•ң кІ°кіј м§ҖмҶҚмӢңк°„м—җ л”°лқј нҸүк· м ҲлҢҖмҳӨм°Ё 2.97~7.05 mm, нҸүк· м ңкіұк·јмҳӨм°Ё 3.39~9.80 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё 7.07~8.31%лЎң 분м„қлҗҳм—ҲлӢӨ.
н•ҷмҠөмһҗлЈҢ нҷ•мһҘмқ„ мң„н•ҙ Model AлҘј нҶөн•ҙ мҳҲмёЎлҗң 2,118к°ңмқҳ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖмқ„ кіјкұ° м№ЁмҲҳн”јн•ҙмҷҖ к°•мҡ°мһҗлЈҢлҘј нҷңмҡ©н•ҳм—¬ кІҖвӢ…ліҙм •н•ҳм—¬ 818к°ңмқҳ н•ҷмҠөмһҗлЈҢлҘј 추к°ҖлЎң кө¬м¶•н•ҳмҳҖлӢӨ.
Training Data Set Aм—җ нҷ•мһҘлҗң лҚ°мқҙн„°лҘј 추к°Җн•ҳм—¬ Training Data Set BлҘј кө¬м¶•н•ҳмҳҖмңјл©°, мҙқ 1,133к°ң н•ҷмҠөмһҗлЈҢлҘј нҷңмҡ©н•ҳм—¬ Model BлҘј к°ңл°ңн•ҳмҳҖлӢӨ. к°ңм„ лҗң лӘЁлҚёмқҳ мҳҲмёЎ м„ұлҠҘмқҖ нҸүк· м ҲлҢҖмҳӨм°Ё 0.41~4.29 mm, нҸүк· м ңкіұк·јмҳӨм°Ё 1.03~6.88 mm, нҸүк· м ҲлҢҖ비мңЁмҳӨм°Ё 0.71~4.37%лЎң лӮҳнғҖлӮҳ, Model A лҢҖ비 м§ҖмҶҚмӢңк°„ 30분м—җм„ң 41.0~65.8%, 60분 82.6~94.5%, 180분 29.8~39.1% к°ңм„ лҗҳлҠ” кІғмңјлЎң лӮҳнғҖлӮ¬лӢӨ. лҳҗн•ң м„ н–үм—°кө¬мқё Neuro-Fuzzy лӘЁлҚёкіј 비көҗн•ң кІ°кіјм—җм„ңлҸ„ нҸүк· м ңкіұк·јмҳӨм°Ё кё°мӨҖ м§ҖмҶҚмӢңк°„ 60분 90.0%, 180분 62.1% к°ңм„ лҗҳм—ҲлӢӨ.
ANN м•Ңкі лҰ¬мҰҳкіј Training Data нҷ•мһҘмқ„ нҶөн•ң лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖ мҳҲмёЎ лӘЁлҚёмқ„ к°ңм„ нҡЁкіјлҘј нҷ•мқён•ҳмҳҖмңјл©°, н–Ҙнӣ„ к°ңм„ лҗң Model BлҘј нҷңмҡ©н•ҳм—¬ лҸ„мӢңм№ЁмҲҳ мң„н—ҳкё°мӨҖмқ„ мҳҲмёЎн•ңлӢӨл©ҙ ліҙлӢӨ м •нҷ•н•ҳкі нҡЁмңЁм Ғмқё мһ¬лӮңмғҒнҷ©кҙҖлҰ¬к°Җ к°ҖлҠҘн• кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.
ліё м—°кө¬лҘј нҶөн•ҙ кё°ліём ҒмңјлЎң л°©лҢҖн•ң лҚ°мқҙн„°лҘј н•„мҡ”лЎң н•ҳлҠ” л”Ҙлҹ¬лӢқ м•Ңкі лҰ¬мҰҳм—җ 비н•ҙ Training Dataк°Җ л¶ҖмЎұн•ң н•ңкі„м җмқ„ к·№ліөн•ҳкё° мң„н•ҙ лҚ°мқҙн„° нҷ•мһҘ кё°лІ•мқ„ мӮ¬мҡ©н•ҳмҳҖмңјл©°, мқҙлҘј нҶөн•ҙ лӘЁлҚёмқ„ м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ” кІғмқ„ нҷ•мқё н• мҲҳ мһҲм—ҲлӢӨ. м„ н–үм—°кө¬м—җм„ңмҷҖ к°ҷмқҙ Training Dataк°Җ мҰқк°Җн•ҳл©ҙ лӘЁлҚёмқҳ м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ” лҸҷмқјн•ң кІ°кіјлҘј лҸ„м¶ңн•ҳмҳҖмңјл©°, н–Ҙнӣ„ лҚ°мқҙн„° 추к°Җ кө¬м¶•мқ„ нҶөн•ҙм„ңлҸ„ м§ҖмҶҚм ҒмңјлЎң к°ңм„ мқҙ к°ҖлҠҘн• кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ. лҳҗн•ң л§Өл…„ л°ңмғқ м№ЁмҲҳн”јн•ҙмһҗлЈҢмҷҖ к°•мҡ°мһҗлЈҢлҘј нҷңмҡ©н•ҳм—¬ мҳҲмёЎлҗң м№ЁмҲҳмң„н—ҳкё°мӨҖмқ„ кІҖмҰқ л°Ҹ к°ңм„ н• н•„мҡ”к°Җ мһҲмңјл©°, нҠ№нһҲ м •нҷ•н•ң м№ЁмҲҳмӢңк°„мқ„ нҢҢм•…н• мҲҳ мһҲлҠ” м№ЁмҲҳм„јм„ң, CCTV мҳҒмғҒ л“ұ м№ЁмҲҳмһҗлЈҢлҘј нҷңмҡ©н•ңлӢӨл©ҙ м№ЁмҲҳ мң„н—ҳкё°мӨҖмқҳ м •нҷ•м„ұмқҙ н–ҘмғҒлҗ мҲҳ мһҲмқ„ кІғмқҙлӢӨ.




